 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Scientific Research with Gemini: Case Studies and Common Techniques
Feb 03, 2026Recent advances in large language models (LLMs) have opened new avenues for accelerating scientific research. While models are increasingly capable of assisting with routine tasks, their ability to contribute to novel, expert-level mathematical discovery is less understood. We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models, specifically Google's Gemini-based models (in particular Gemini Deep Think and its advanced variants), to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer. While the majority of our results stem from this interactive, conversational methodology, we also highlight specific instances that push beyond standard chat interfaces. These include deploying the model as a rigorous adversarial reviewer to detect subtle flaws in existing proofs, and embedding it within a "neuro-symbolic" loop that autonomously writes and executes code to verify complex derivations. Together, these examples highlight the potential of AI not just as a tool for automation, but as a versatile, genuine partner in the creative process of scientific discovery.
Efficient Swap Regret Minimization in Combinatorial Bandits
Feb 02, 2026This paper addresses the problem of designing efficient no-swap regret algorithms for combinatorial bandits, where the number of actions $N$ is exponentially large in the dimensionality of the problem. In this setting, designing efficient no-swap regret translates to sublinear -- in horizon $T$ -- swap regret with polylogarithmic dependence on $N$. In contrast to the weaker notion of external regret minimization - a problem which is fairly well understood in the literature - achieving no-swap regret with a polylogarithmic dependence on $N$ has remained elusive in combinatorial bandits. Our paper resolves this challenge, by introducing a no-swap-regret learning algorithm with regret that scales polylogarithmically in $N$ and is tight for the class of combinatorial bandits. To ground our results, we also demonstrate how to implement the proposed algorithm efficiently -- that is, with a per-iteration complexity that also scales polylogarithmically in $N$ -- across a wide range of well-studied applications.
Exact Learning of Weighted Graphs Using Composite Queries
Nov 18, 2025In this paper, we study the exact learning problem for weighted graphs, where we are given the vertex set, $V$, of a weighted graph, $G=(V,E,w)$, but we are not given $E$. The problem, which is also known as graph reconstruction, is to determine all the edges of $E$, including their weights, by asking queries about $G$ from an oracle. As we observe, using simple shortest-path length queries is not sufficient, in general, to learn a weighted graph. So we study a number of scenarios where it is possible to learn $G$ using a subquadratic number of composite queries, which combine two or three simple queries.
Last-iterate Convergence Separation between Extra-gradient and Optimism in Constrained Periodic Games
Jun 15, 2024Last-iterate behaviors of learning algorithms in repeated two-player zero-sum games have been extensively studied due to their wide applications in machine learning and related tasks. Typical algorithms that exhibit the last-iterate convergence property include optimistic and extra-gradient methods. However, most existing results establish these properties under the assumption that the game is time-independent. Recently, (Feng et al, 2023) studied the last-iterate behaviors of optimistic and extra-gradient methods in games with a time-varying payoff matrix, and proved that in an unconstrained periodic game, extra-gradient method converges to the equilibrium while optimistic method diverges. This finding challenges the conventional wisdom that these two methods are expected to behave similarly as they do in time-independent games. However, compared to unconstrained games, games with constrains are more common both in practical and theoretical studies. In this paper, we investigate the last-iterate behaviors of optimistic and extra-gradient methods in the constrained periodic games, demonstrating that similar separation results for last-iterate convergence also hold in this setting.
Optimistic Policy Gradient in Multi-Player Markov Games with a Single Controller: Convergence Beyond the Minty Property
Dec 21, 2023Policy gradient methods enjoy strong practical performance in numerous tasks in reinforcement learning. Their theoretical understanding in multiagent settings, however, remains limited, especially beyond two-player competitive and potential Markov games. In this paper, we develop a new framework to characterize optimistic policy gradient methods in multi-player Markov games with a single controller. Specifically, under the further assumption that the game exhibits an equilibrium collapse, in that the marginals of coarse correlated equilibria (CCE) induce Nash equilibria (NE), we show convergence to stationary $\epsilon$-NE in $O(1/\epsilon^2)$ iterations, where $O(\cdot)$ suppresses polynomial factors in the natural parameters of the game. Such an equilibrium collapse is well-known to manifest itself in two-player zero-sum Markov games, but also occurs even in a class of multi-player Markov games with separable interactions, as established by recent work. As a result, we bypass known complexity barriers for computing stationary NE when either of our assumptions fails. Our approach relies on a natural generalization of the classical Minty property that we introduce, which we anticipate to have further applications beyond Markov games.
On the Convergence of No-Regret Learning Dynamics in Time-Varying Games
Jan 26, 2023


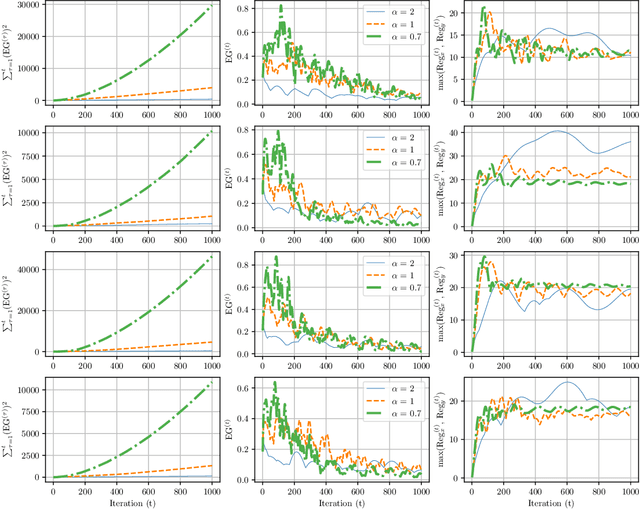
Most of the literature on learning in games has focused on the restrictive setting where the underlying repeated game does not change over time. Much less is known about the convergence of no-regret learning algorithms in dynamic multiagent settings. In this paper, we characterize the convergence of \emph{optimistic gradient descent (OGD)} in time-varying games by drawing a strong connection with \emph{dynamic regret}. Our framework yields sharp convergence bounds for the equilibrium gap of OGD in zero-sum games parameterized on the \emph{minimal} first-order variation of the Nash equilibria and the second-order variation of the payoff matrices, subsuming known results for static games. Furthermore, we establish improved \emph{second-order} variation bounds under strong convexity-concavity, as long as each game is repeated multiple times. Our results also apply to time-varying \emph{general-sum} multi-player games via a bilinear formulation of correlated equilibria, which has novel implications for meta-learning and for obtaining refined variation-dependent regret bounds, addressing questions left open in prior papers. Finally, we leverage our framework to also provide new insights on dynamic regret guarantees in static games.
On Scrambling Phenomena for Randomly Initialized Recurrent Networks
Oct 11, 2022
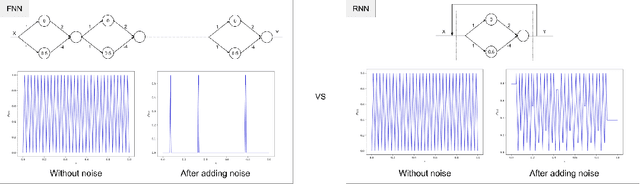


Recurrent Neural Networks (RNNs) frequently exhibit complicated dynamics, and their sensitivity to the initialization process often renders them notoriously hard to train. Recent works have shed light on such phenomena analyzing when exploding or vanishing gradients may occur, either of which is detrimental for training dynamics. In this paper, we point to a formal connection between RNNs and chaotic dynamical systems and prove a qualitatively stronger phenomenon about RNNs than what exploding gradients seem to suggest. Our main result proves that under standard initialization (e.g., He, Xavier etc.), RNNs will exhibit \textit{Li-Yorke chaos} with \textit{constant} probability \textit{independent} of the network's width. This explains the experimentally observed phenomenon of \textit{scrambling}, under which trajectories of nearby points may appear to be arbitrarily close during some timesteps, yet will be far away in future timesteps. In stark contrast to their feedforward counterparts, we show that chaotic behavior in RNNs is preserved under small perturbations and that their expressive power remains exponential in the number of feedback iterations. Our technical arguments rely on viewing RNNs as random walks under non-linear activations, and studying the existence of certain types of higher-order fixed points called \textit{periodic points} that lead to phase transitions from order to chaos.
Efficiently Computing Nash Equilibria in Adversarial Team Markov Games
Aug 03, 2022
Computing Nash equilibrium policies is a central problem in multi-agent reinforcement learning that has received extensive attention both in theory and in practice. However, provable guarantees have been thus far either limited to fully competitive or cooperative scenarios or impose strong assumptions that are difficult to meet in most practical applications. In this work, we depart from those prior results by investigating infinite-horizon \emph{adversarial team Markov games}, a natural and well-motivated class of games in which a team of identically-interested players -- in the absence of any explicit coordination or communication -- is competing against an adversarial player. This setting allows for a unifying treatment of zero-sum Markov games and Markov potential games, and serves as a step to model more realistic strategic interactions that feature both competing and cooperative interests. Our main contribution is the first algorithm for computing stationary $\epsilon$-approximate Nash equilibria in adversarial team Markov games with computational complexity that is polynomial in all the natural parameters of the game, as well as $1/\epsilon$. The proposed algorithm is particularly natural and practical, and it is based on performing independent policy gradient steps for each player in the team, in tandem with best responses from the side of the adversary; in turn, the policy for the adversary is then obtained by solving a carefully constructed linear program. Our analysis leverages non-standard techniques to establish the KKT optimality conditions for a nonlinear program with nonconvex constraints, thereby leading to a natural interpretation of the induced Lagrange multipliers. Along the way, we significantly extend an important characterization of optimal policies in adversarial (normal-form) team games due to Von Stengel and Koller (GEB `97).
Accelerated Multiplicative Weights Update Avoids Saddle Points almost always
Apr 25, 2022



We consider non-convex optimization problems with constraint that is a product of simplices. A commonly used algorithm in solving this type of problem is the Multiplicative Weights Update (MWU), an algorithm that is widely used in game theory, machine learning and multi-agent systems. Despite it has been known that MWU avoids saddle points, there is a question that remains unaddressed:"Is there an accelerated version of MWU that avoids saddle points provably?" In this paper we provide a positive answer to above question. We provide an accelerated MWU based on Riemannian Accelerated Gradient Descent, and prove that the Riemannian Accelerated Gradient Descent, thus the accelerated MWU, almost always avoid saddle points.
Teamwork makes von Neumann work: Min-Max Optimization in Two-Team Zero-Sum Games
Nov 29, 2021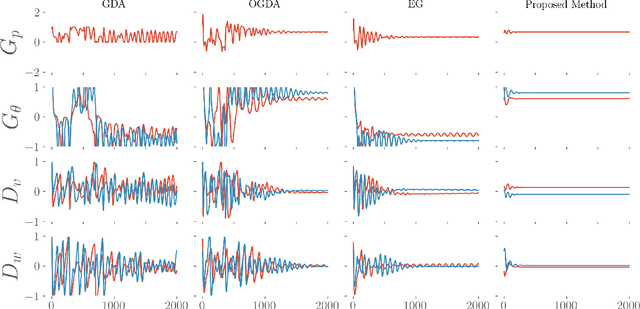
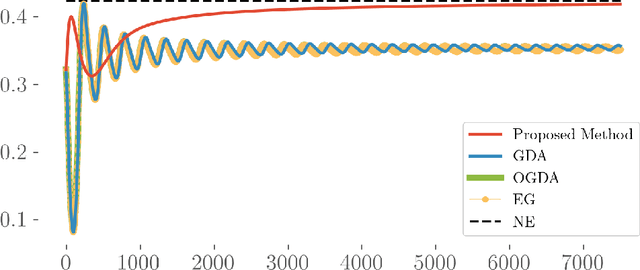


Motivated by recent advances in both theoretical and applied aspects of multiplayer games, spanning from e-sports to multi-agent generative adversarial networks, we focus on min-max optimization in team zero-sum games. In this class of games, players are split into two teams with payoffs equal within the same team and of opposite sign across the opponent team. Unlike the textbook two-player zero-sum games, finding a Nash equilibrium in our class can be shown to be CLS-hard, i.e., it is unlikely to have a polynomial-time algorithm for computing Nash equilibria. Moreover, in this generalized framework, we establish that even asymptotic last iterate or time average convergence to a Nash Equilibrium is not possible using Gradient Descent Ascent (GDA), its optimistic variant, and extra gradient. Specifically, we present a family of team games whose induced utility is \emph{non} multi-linear with \emph{non} attractive \emph{per-se} mixed Nash Equilibria, as strict saddle points of the underlying optimization landscape. Leveraging techniques from control theory, we complement these negative results by designing a modified GDA that converges locally to Nash equilibria. Finally, we discuss connections of our framework with AI architectures with team competition structures like multi-agent generative adversarial networks.