 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitcoin's Edge: Embedded Sentiment in Blockchain Transactional Data
Apr 18, 2025



Cryptocurrency blockchains, beyond their primary role as distributed payment systems, are increasingly used to store and share arbitrary content, such as text messages and files. Although often non-financial, this hidden content can impact price movements by conveying private information, shaping sentiment, and influencing public opinion. However, current analyses of such data are limited in scope and scalability, primarily relying on manual classification or hand-crafted heuristics. In this work, we address these limitations by employing Natural Language Processing techniques to analyze, detect patterns, and extract public sentiment encoded within blockchain transactional data. Using a variety of Machine Learning techniques, we showcase for the first time the predictive power of blockchain-embedded sentiment in forecasting cryptocurrency price movements on the Bitcoin and Ethereum blockchains. Our findings shed light on a previously underexplored source of freely available, transparent, and immutable data and introduce blockchain sentiment analysis as a novel and robust framework for enhancing financial predictions in cryptocurrency markets. Incidentally, we discover an asymmetry between cryptocurrencies; Bitcoin has an informational advantage over Ethereum in that the sentiment embedded into transactional data is sufficient to predict its price movement.
AlberDICE: Addressing Out-Of-Distribution Joint Actions in Offline Multi-Agent RL via Alternating Stationary Distribution Correction Estimation
Nov 03, 2023One of the main challenges in offline Reinforcement Learning (RL) is the distribution shift that arises from the learned policy deviating from the data collection policy. This is often addressed by avoiding out-of-distribution (OOD) actions during policy improvement as their presence can lead to substantial performance degradation. This challenge is amplified in the offline Multi-Agent RL (MARL) setting since the joint action space grows exponentially with the number of agents. To avoid this curse of dimensionality, existing MARL methods adopt either value decomposition methods or fully decentralized training of individual agents. However, even when combined with standard conservatism principles, these methods can still result in the selection of OOD joint actions in offline MARL. To this end, we introduce AlberDICE, an offline MARL algorithm that alternatively performs centralized training of individual agents based on stationary distribution optimization. AlberDICE circumvents the exponential complexity of MARL by computing the best response of one agent at a time while effectively avoiding OOD joint action selection. Theoretically, we show that the alternating optimization procedure converges to Nash policies. In the experiments, we demonstrate that AlberDICE significantly outperforms baseline algorithms on a standard suite of MARL benchmarks.
Exploration-Exploitation in Multi-Agent Competition: Convergence with Bounded Rationality
Jun 24, 2021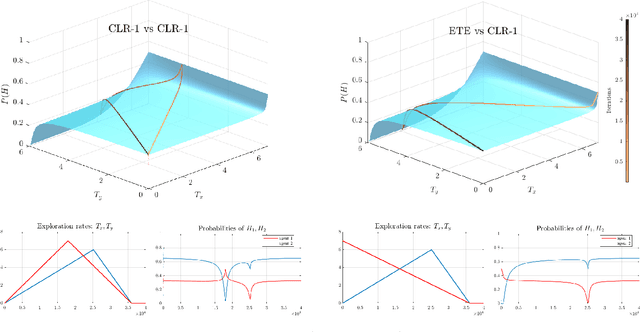



The interplay between exploration and exploitation in competitive multi-agent learning is still far from being well understood. Motivated by this, we study smooth Q-learning, a prototypical learning model that explicitly captures the balance between game rewards and exploration costs. We show that Q-learning always converges to the unique quantal-response equilibrium (QRE), the standard solution concept for games under bounded rationality, in weighted zero-sum polymatrix games with heterogeneous learning agents using positive exploration rates. Complementing recent results about convergence in weighted potential games, we show that fast convergence of Q-learning in competitive settings is obtained regardless of the number of agents and without any need for parameter fine-tuning. As showcased by our experiments in network zero-sum games, these theoretical results provide the necessary guarantees for an algorithmic approach to the currently open problem of equilibrium selection in competitive multi-agent settings.
Global Convergence of Multi-Agent Policy Gradient in Markov Potential Games
Jun 03, 2021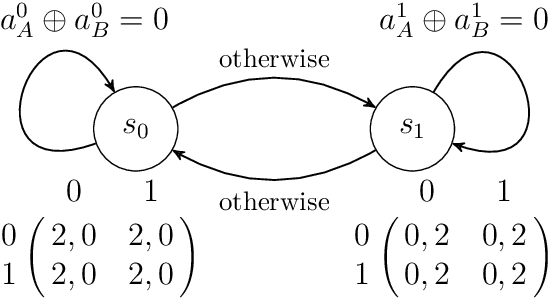

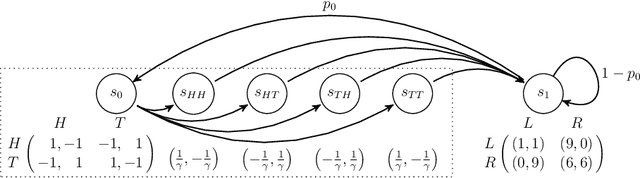
Potential games are arguably one of the most important and widely studied classes of normal form games. They define the archetypal setting of multi-agent coordination as all agent utilities are perfectly aligned with each other via a common potential function. Can this intuitive framework be transplanted in the setting of Markov Games? What are the similarities and differences between multi-agent coordination with and without state dependence? We present a novel definition of Markov Potential Games (MPG) that generalizes prior attempts at capturing complex stateful multi-agent coordination. Counter-intuitively, insights from normal-form potential games do not carry over as MPGs can consist of settings where state-games can be zero-sum games. In the opposite direction, Markov games where every state-game is a potential game are not necessarily MPGs. Nevertheless, MPGs showcase standard desirable properties such as the existence of deterministic Nash policies. In our main technical result, we prove fast convergence of independent policy gradient to Nash policies by adapting recent gradient dominance property arguments developed for single agent MDPs to multi-agent learning settings.