 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndependent Natural Policy Gradient Always Converges in Markov Potential Games
Oct 20, 2021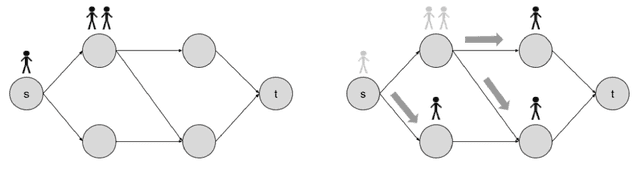
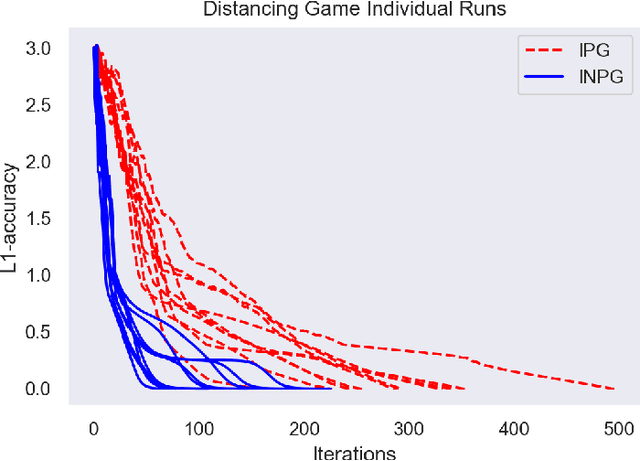
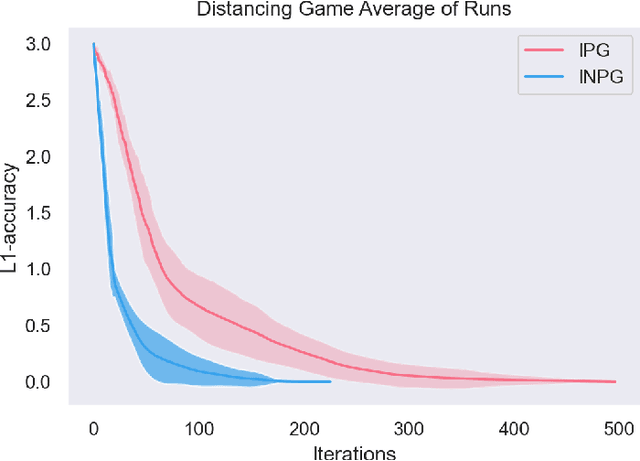
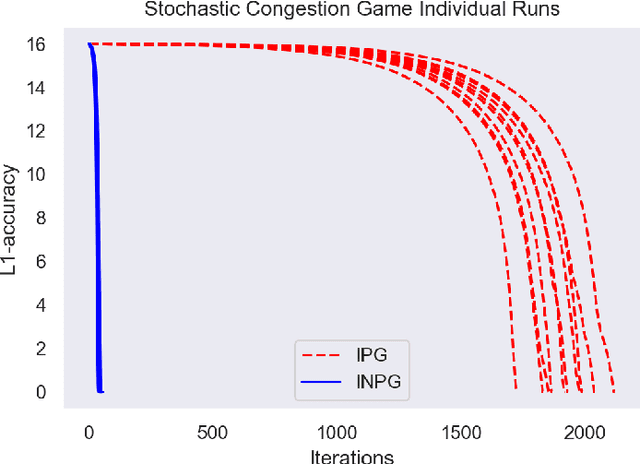
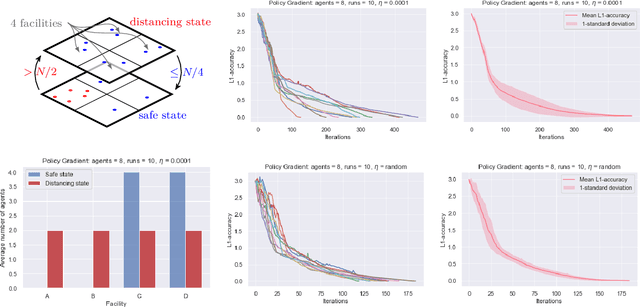
Multi-agent reinforcement learning has been successfully applied to fully-cooperative and fully-competitive environments, but little is currently known about mixed cooperative/competitive environments. In this paper, we focus on a particular class of multi-agent mixed cooperative/competitive stochastic games called Markov Potential Games (MPGs), which include cooperative games as a special case. Recent results have shown that independent policy gradient converges in MPGs but it was not known whether Independent Natural Policy Gradient converges in MPGs as well. We prove that Independent Natural Policy Gradient always converges in the last iterate using constant learning rates. The proof deviates from the existing approaches and the main challenge lies in the fact that Markov Potential Games do not have unique optimal values (as single-agent settings exhibit) so different initializations can lead to different limit point values. We complement our theoretical results with experiments that indicate that Natural Policy Gradient outperforms Policy Gradient in routing games and congestion games.
Global Convergence of Multi-Agent Policy Gradient in Markov Potential Games
Jun 03, 2021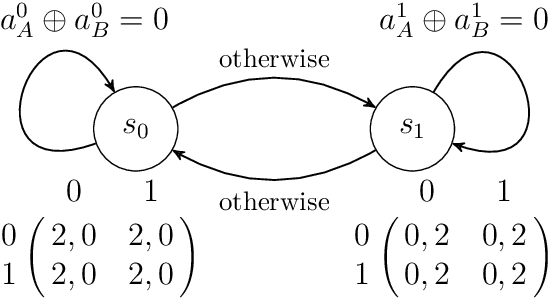

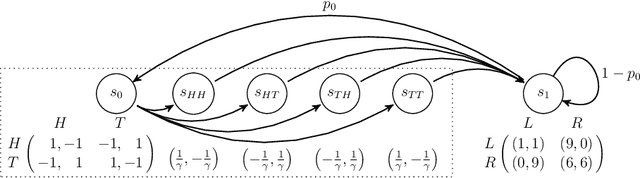
Potential games are arguably one of the most important and widely studied classes of normal form games. They define the archetypal setting of multi-agent coordination as all agent utilities are perfectly aligned with each other via a common potential function. Can this intuitive framework be transplanted in the setting of Markov Games? What are the similarities and differences between multi-agent coordination with and without state dependence? We present a novel definition of Markov Potential Games (MPG) that generalizes prior attempts at capturing complex stateful multi-agent coordination. Counter-intuitively, insights from normal-form potential games do not carry over as MPGs can consist of settings where state-games can be zero-sum games. In the opposite direction, Markov games where every state-game is a potential game are not necessarily MPGs. Nevertheless, MPGs showcase standard desirable properties such as the existence of deterministic Nash policies. In our main technical result, we prove fast convergence of independent policy gradient to Nash policies by adapting recent gradient dominance property arguments developed for single agent MDPs to multi-agent learning settings.