 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndependent Natural Policy Gradient Always Converges in Markov Potential Games
Paper and Code
Oct 20, 2021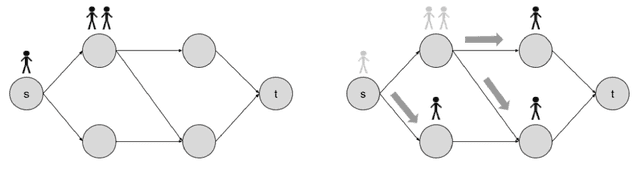
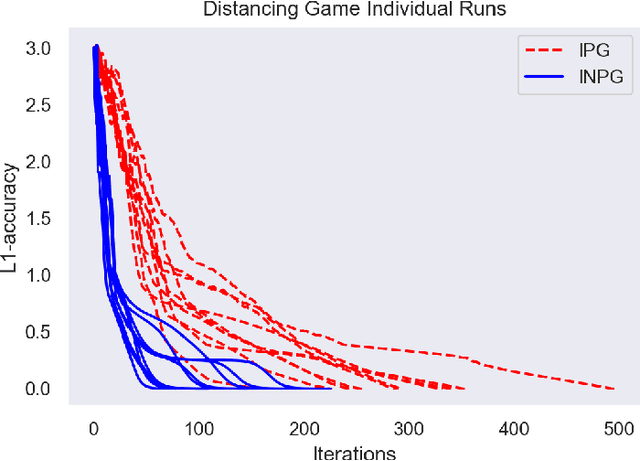
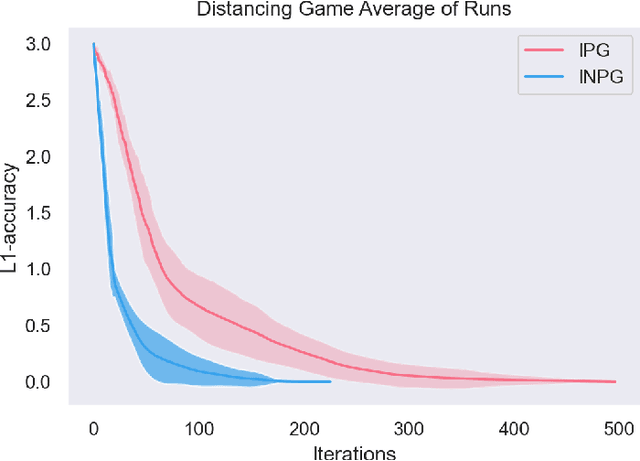
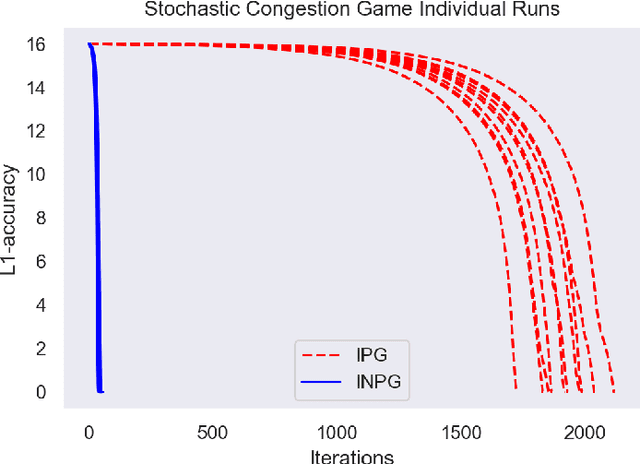
Multi-agent reinforcement learning has been successfully applied to fully-cooperative and fully-competitive environments, but little is currently known about mixed cooperative/competitive environments. In this paper, we focus on a particular class of multi-agent mixed cooperative/competitive stochastic games called Markov Potential Games (MPGs), which include cooperative games as a special case. Recent results have shown that independent policy gradient converges in MPGs but it was not known whether Independent Natural Policy Gradient converges in MPGs as well. We prove that Independent Natural Policy Gradient always converges in the last iterate using constant learning rates. The proof deviates from the existing approaches and the main challenge lies in the fact that Markov Potential Games do not have unique optimal values (as single-agent settings exhibit) so different initializations can lead to different limit point values. We complement our theoretical results with experiments that indicate that Natural Policy Gradient outperforms Policy Gradient in routing games and congestion games.