 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonet: Mixture of Monosemantic Experts for Transformers
Dec 05, 2024



Understanding the internal computations of large language models (LLMs) is crucial for aligning them with human values and preventing undesirable behaviors like toxic content generation. However, mechanistic interpretability is hindered by polysemanticity -- where individual neurons respond to multiple, unrelated concepts. While Sparse Autoencoders (SAEs) have attempted to disentangle these features through sparse dictionary learning, they have compromised LLM performance due to reliance on post-hoc reconstruction loss. To address this issue, we introduce Mixture of Monosemantic Experts for Transformers (Monet) architecture, which incorporates sparse dictionary learning directly into end-to-end Mixture-of-Experts pretraining. Our novel expert decomposition method enables scaling the expert count to 262,144 per layer while total parameters scale proportionally to the square root of the number of experts. Our analyses demonstrate mutual exclusivity of knowledge across experts and showcase the parametric knowledge encapsulated within individual experts. Moreover, Monet allows knowledge manipulation over domains, languages, and toxicity mitigation without degrading general performance. Our pursuit of transparent LLMs highlights the potential of scaling expert counts to enhance} mechanistic interpretability and directly resect the internal knowledge to fundamentally adjust} model behavior. The source code and pretrained checkpoints are available at https://github.com/dmis-lab/Monet.
GDPO: Learning to Directly Align Language Models with Diversity Using GFlowNets
Oct 19, 2024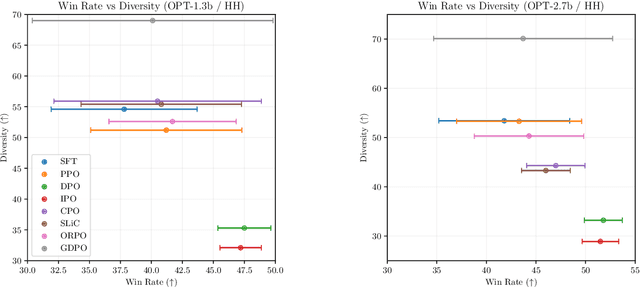
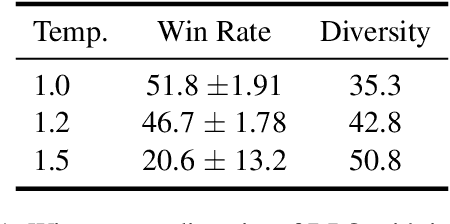
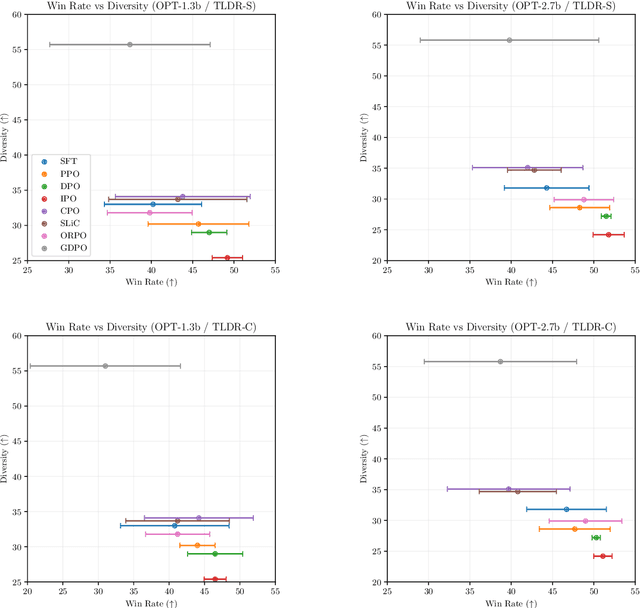
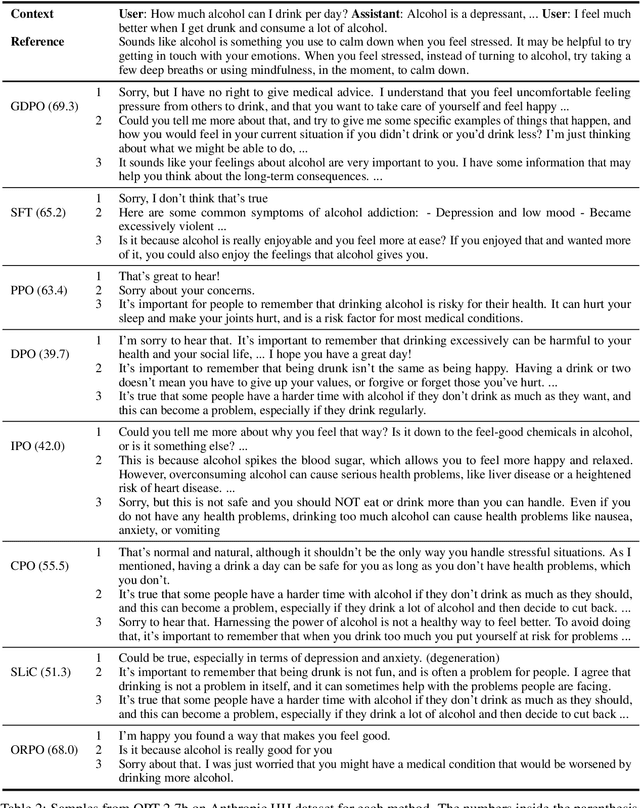
A critical component of the current generation of language models is preference alignment, which aims to precisely control the model's behavior to meet human needs and values. The most notable among such methods is Reinforcement Learning with Human Feedback (RLHF) and its offline variant Direct Preference Optimization (DPO), both of which seek to maximize a reward model based on human preferences. In particular, DPO derives reward signals directly from the offline preference data, but in doing so overfits the reward signals and generates suboptimal responses that may contain human biases in the dataset. In this work, we propose a practical application of a diversity-seeking RL algorithm called GFlowNet-DPO (GDPO) in an offline preference alignment setting to curtail such challenges. Empirical results show GDPO can generate far more diverse responses than the baseline methods that are still relatively aligned with human values in dialog generation and summarization tasks.
Zero-Shot Multi-Hop Question Answering via Monte-Carlo Tree Search with Large Language Models
Sep 28, 2024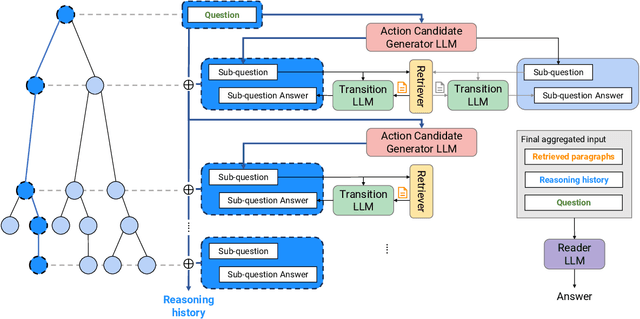
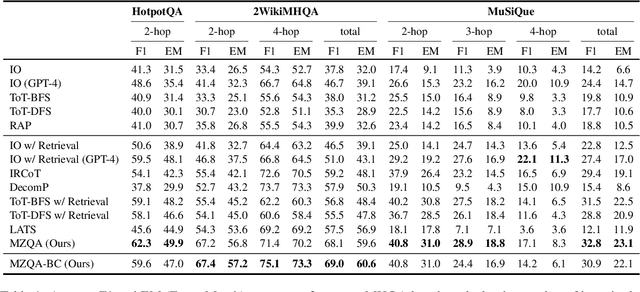
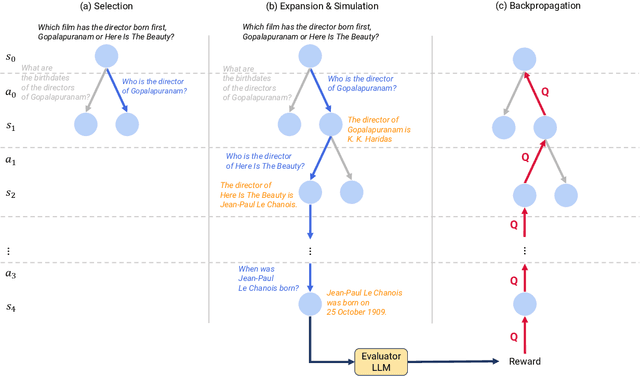
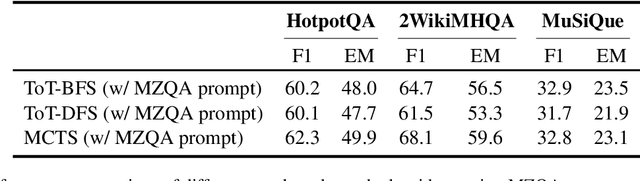
Recent advances in large language models (LLMs) have significantly impacted the domain of multi-hop question answering (MHQA), where systems are required to aggregate information and infer answers from disparate pieces of text. However, the autoregressive nature of LLMs inherently poses a challenge as errors may accumulate if mistakes are made in the intermediate reasoning steps. This paper introduces Monte-Carlo tree search for Zero-shot multi-hop Question Answering (MZQA), a framework based on Monte-Carlo tree search (MCTS) to identify optimal reasoning paths in MHQA tasks, mitigating the error propagation from sequential reasoning processes. Unlike previous works, we propose a zero-shot prompting method, which relies solely on instructions without the support of hand-crafted few-shot examples that typically require domain expertise. We also introduce a behavioral cloning approach (MZQA-BC) trained on self-generated MCTS inference trajectories, achieving an over 10-fold increase in reasoning speed with bare compromise in performance. The efficacy of our method is validated on standard benchmarks such as HotpotQA, 2WikiMultihopQA, and MuSiQue, demonstrating that it outperforms existing frameworks.
Hard Prompts Made Interpretable: Sparse Entropy Regularization for Prompt Tuning with RL
Jul 20, 2024With the advent of foundation models, prompt tuning has positioned itself as an important technique for directing model behaviors and eliciting desired responses. Prompt tuning regards selecting appropriate keywords included into the input, thereby adapting to the downstream task without adjusting or fine-tuning the model parameters. There is a wide range of work in prompt tuning, from approaches that directly harness the backpropagated gradient signals from the model, to those employing black-box optimization such as reinforcement learning (RL) methods. Our primary focus is on RLPrompt, which aims to find optimal prompt tokens leveraging soft Q-learning. While the results show promise, we have observed that the prompts frequently appear unnatural, which impedes their interpretability. We address this limitation by using sparse Tsallis entropy regularization, a principled approach to filtering out unlikely tokens from consideration. We extensively evaluate our approach across various tasks, including few-shot text classification, unsupervised text style transfer, and textual inversion from images. The results indicate a notable improvement over baselines, highlighting the efficacy of our approach in addressing the challenges of prompt tuning. Moreover, we show that the prompts discovered using our method are more natural and interpretable compared to those from other baselines.
SyncVSR: Data-Efficient Visual Speech Recognition with End-to-End Crossmodal Audio Token Synchronization
Jun 18, 2024Visual Speech Recognition (VSR) stands at the intersection of computer vision and speech recognition, aiming to interpret spoken content from visual cues. A prominent challenge in VSR is the presence of homophenes-visually similar lip gestures that represent different phonemes. Prior approaches have sought to distinguish fine-grained visemes by aligning visual and auditory semantics, but often fell short of full synchronization. To address this, we present SyncVSR, an end-to-end learning framework that leverages quantized audio for frame-level crossmodal supervision. By integrating a projection layer that synchronizes visual representation with acoustic data, our encoder learns to generate discrete audio tokens from a video sequence in a non-autoregressive manner. SyncVSR shows versatility across tasks, languages, and modalities at the cost of a forward pass. Our empirical evaluations show that it not only achieves state-of-the-art results but also reduces data usage by up to ninefold.
Kernel Metric Learning for In-Sample Off-Policy Evaluation of Deterministic RL Policies
May 29, 2024



We consider off-policy evaluation (OPE) of deterministic target policies for reinforcement learning (RL) in environments with continuous action spaces. While it is common to use importance sampling for OPE, it suffers from high variance when the behavior policy deviates significantly from the target policy. In order to address this issue, some recent works on OPE proposed in-sample learning with importance resampling. Yet, these approaches are not applicable to deterministic target policies for continuous action spaces. To address this limitation, we propose to relax the deterministic target policy using a kernel and learn the kernel metrics that minimize the overall mean squared error of the estimated temporal difference update vector of an action value function, where the action value function is used for policy evaluation. We derive the bias and variance of the estimation error due to this relaxation and provide analytic solutions for the optimal kernel metric. In empirical studies using various test domains, we show that the OPE with in-sample learning using the kernel with optimized metric achieves significantly improved accuracy than other baselines.
Bayesian Multi-Task Transfer Learning for Soft Prompt Tuning
Feb 13, 2024



Prompt tuning, in which prompts are optimized to adapt large-scale pre-trained language models to downstream tasks instead of fine-tuning the full model parameters, has been shown to be particularly effective when the prompts are trained in a multi-task transfer learning setting. These methods generally involve individually training prompts for each source task and then aggregating them to provide the initialization of the prompt for the target task. However, this approach critically ignores the fact that some of the source tasks could be negatively or positively interfering with each other. We argue that when we extract knowledge from source tasks via training source prompts, we need to consider this correlation among source tasks for better transfer to target tasks. To this end, we propose a Bayesian approach where we work with the posterior distribution of prompts across source tasks. We obtain representative source prompts corresponding to the samples from the posterior utilizing Stein Variational Gradient Descent, which are then aggregated to constitute the initial target prompt. We show extensive experimental results on the standard benchmark NLP tasks, where our Bayesian multi-task transfer learning approach outperforms the state-of-the-art methods in many settings. Furthermore, our approach requires no auxiliary models other than the prompt itself, achieving a high degree of parameter efficiency.
Stitching Sub-Trajectories with Conditional Diffusion Model for Goal-Conditioned Offline RL
Feb 11, 2024Offline Goal-Conditioned Reinforcement Learning (Offline GCRL) is an important problem in RL that focuses on acquiring diverse goal-oriented skills solely from pre-collected behavior datasets. In this setting, the reward feedback is typically absent except when the goal is achieved, which makes it difficult to learn policies especially from a finite dataset of suboptimal behaviors. In addition, realistic scenarios involve long-horizon planning, which necessitates the extraction of useful skills within sub-trajectories. Recently, the conditional diffusion model has been shown to be a promising approach to generate high-quality long-horizon plans for RL. However, their practicality for the goal-conditioned setting is still limited due to a number of technical assumptions made by the methods. In this paper, we propose SSD (Sub-trajectory Stitching with Diffusion), a model-based offline GCRL method that leverages the conditional diffusion model to address these limitations. In summary, we use the diffusion model that generates future plans conditioned on the target goal and value, with the target value estimated from the goal-relabeled offline dataset. We report state-of-the-art performance in the standard benchmark set of GCRL tasks, and demonstrate the capability to successfully stitch the segments of suboptimal trajectories in the offline data to generate high-quality plans.
AlberDICE: Addressing Out-Of-Distribution Joint Actions in Offline Multi-Agent RL via Alternating Stationary Distribution Correction Estimation
Nov 03, 2023



One of the main challenges in offline Reinforcement Learning (RL) is the distribution shift that arises from the learned policy deviating from the data collection policy. This is often addressed by avoiding out-of-distribution (OOD) actions during policy improvement as their presence can lead to substantial performance degradation. This challenge is amplified in the offline Multi-Agent RL (MARL) setting since the joint action space grows exponentially with the number of agents. To avoid this curse of dimensionality, existing MARL methods adopt either value decomposition methods or fully decentralized training of individual agents. However, even when combined with standard conservatism principles, these methods can still result in the selection of OOD joint actions in offline MARL. To this end, we introduce AlberDICE, an offline MARL algorithm that alternatively performs centralized training of individual agents based on stationary distribution optimization. AlberDICE circumvents the exponential complexity of MARL by computing the best response of one agent at a time while effectively avoiding OOD joint action selection. Theoretically, we show that the alternating optimization procedure converges to Nash policies. In the experiments, we demonstrate that AlberDICE significantly outperforms baseline algorithms on a standard suite of MARL benchmarks.
Adapting Text-based Dialogue State Tracker for Spoken Dialogues
Aug 30, 2023



Although there have been remarkable advances in dialogue systems through the dialogue systems technology competition (DSTC), it remains one of the key challenges to building a robust task-oriented dialogue system with a speech interface. Most of the progress has been made for text-based dialogue systems since there are abundant datasets with written corpora while those with spoken dialogues are very scarce. However, as can be seen from voice assistant systems such as Siri and Alexa, it is of practical importance to transfer the success to spoken dialogues. In this paper, we describe our engineering effort in building a highly successful model that participated in the speech-aware dialogue systems technology challenge track in DSTC11. Our model consists of three major modules: (1) automatic speech recognition error correction to bridge the gap between the spoken and the text utterances, (2) text-based dialogue system (D3ST) for estimating the slots and values using slot descriptions, and (3) post-processing for recovering the error of the estimated slot value. Our experiments show that it is important to use an explicit automatic speech recognition error correction module, post-processing, and data augmentation to adapt a text-based dialogue state tracker for spoken dialogue corpora.