 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDPO: Learning to Directly Align Language Models with Diversity Using GFlowNets
Oct 19, 2024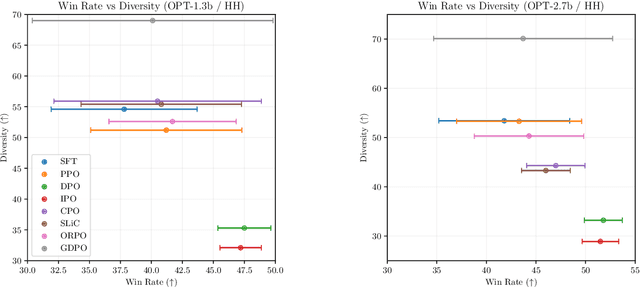
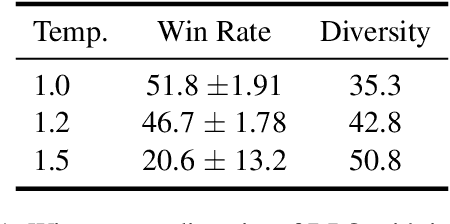
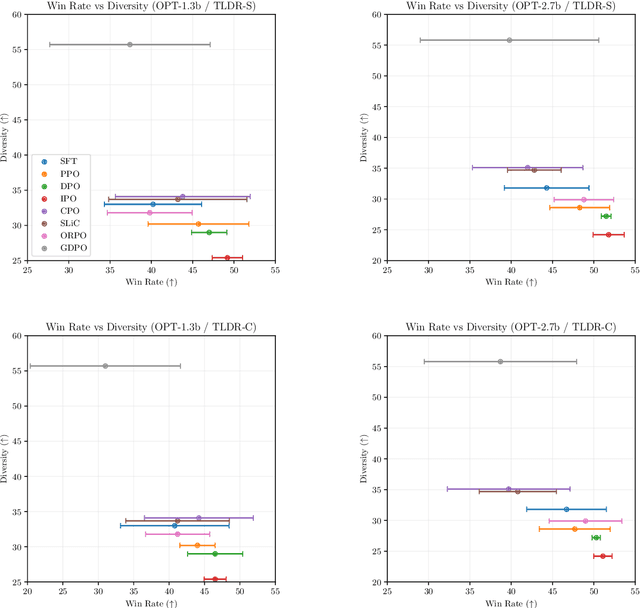
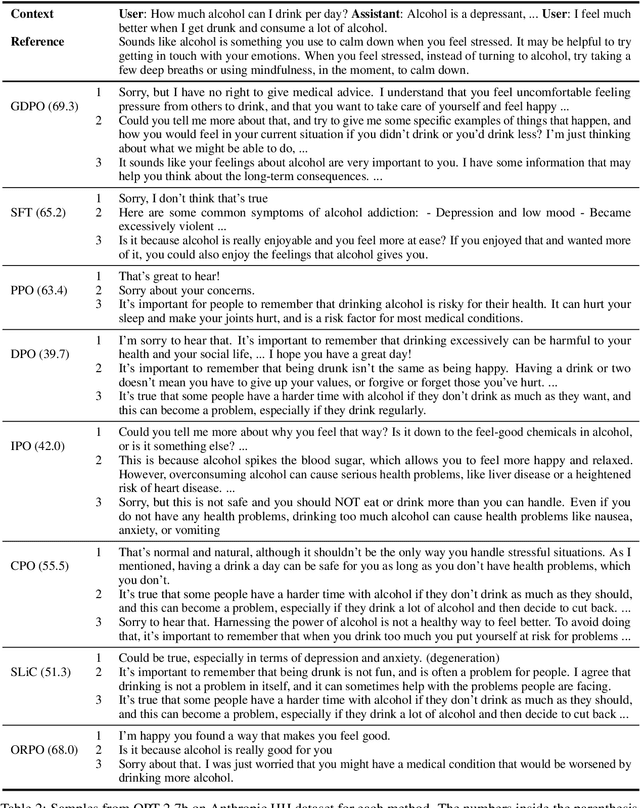
A critical component of the current generation of language models is preference alignment, which aims to precisely control the model's behavior to meet human needs and values. The most notable among such methods is Reinforcement Learning with Human Feedback (RLHF) and its offline variant Direct Preference Optimization (DPO), both of which seek to maximize a reward model based on human preferences. In particular, DPO derives reward signals directly from the offline preference data, but in doing so overfits the reward signals and generates suboptimal responses that may contain human biases in the dataset. In this work, we propose a practical application of a diversity-seeking RL algorithm called GFlowNet-DPO (GDPO) in an offline preference alignment setting to curtail such challenges. Empirical results show GDPO can generate far more diverse responses than the baseline methods that are still relatively aligned with human values in dialog generation and summarization tasks.
Raw Produce Quality Detection with Shifted Window Self-Attention
Dec 24, 2021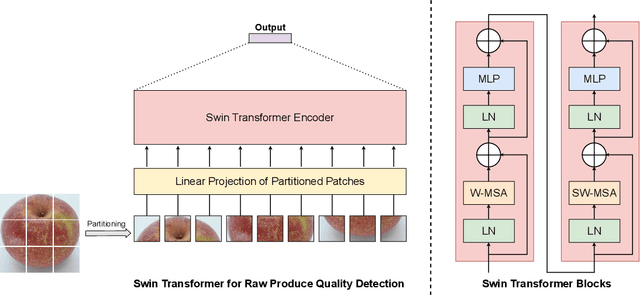
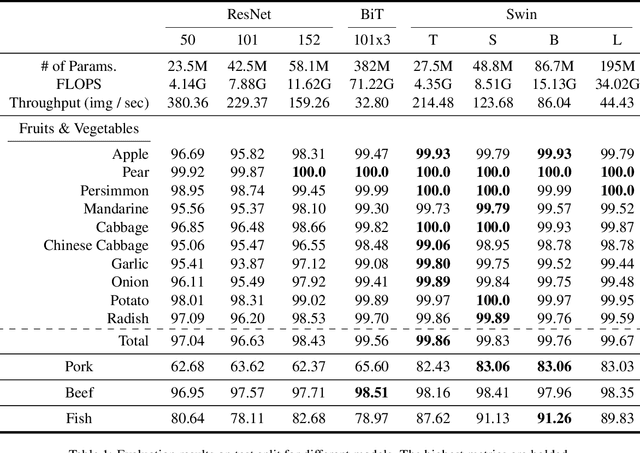
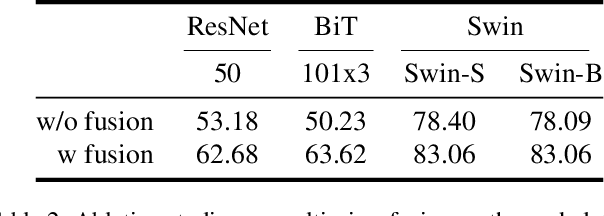
Global food insecurity is expected to worsen in the coming decades with the accelerated rate of climate change and the rapidly increasing population. In this vein, it is important to remove inefficiencies at every level of food production. The recent advances in deep learning can help reduce such inefficiencies, yet their application has not yet become mainstream throughout the industry, inducing economic costs at a massive scale. To this point, modern techniques such as CNNs (Convolutional Neural Networks) have been applied to RPQD (Raw Produce Quality Detection) tasks. On the other hand, Transformer's successful debut in the vision among other modalities led us to expect a better performance with these Transformer-based models in RPQD. In this work, we exclusively investigate the recent state-of-the-art Swin (Shifted Windows) Transformer which computes self-attention in both intra- and inter-window fashion. We compare Swin Transformer against CNN models on four RPQD image datasets, each containing different kinds of raw produce: fruits and vegetables, fish, pork, and beef. We observe that Swin Transformer not only achieves better or competitive performance but also is data- and compute-efficient, making it ideal for actual deployment in real-world setting. To the best of our knowledge, this is the first large-scale empirical study on RPQD task, which we hope will gain more attention in future works.
Augment & Valuate : A Data Enhancement Pipeline for Data-Centric AI
Dec 07, 2021



Data scarcity and noise are important issues in industrial applications of machine learning. However, it is often challenging to devise a scalable and generalized approach to address the fundamental distributional and semantic properties of dataset with black box models. For this reason, data-centric approaches are crucial for the automation of machine learning operation pipeline. In order to serve as the basis for this automation, we suggest a domain-agnostic pipeline for refining the quality of data in image classification problems. This pipeline contains data valuation, cleansing, and augmentation. With an appropriate combination of these methods, we could achieve 84.711% test accuracy (ranked #6, Honorable Mention in the Most Innovative) in the Data-Centric AI competition only with the provided dataset.
Improving Neural Networks by Adopting Amplifying and Attenuating Neurons
May 27, 2019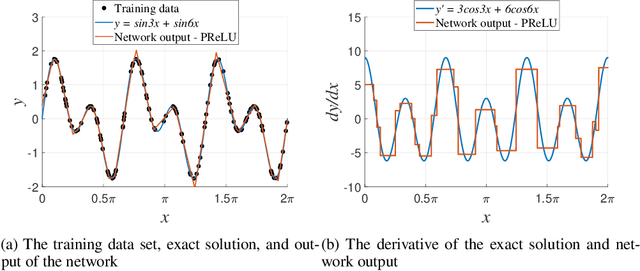
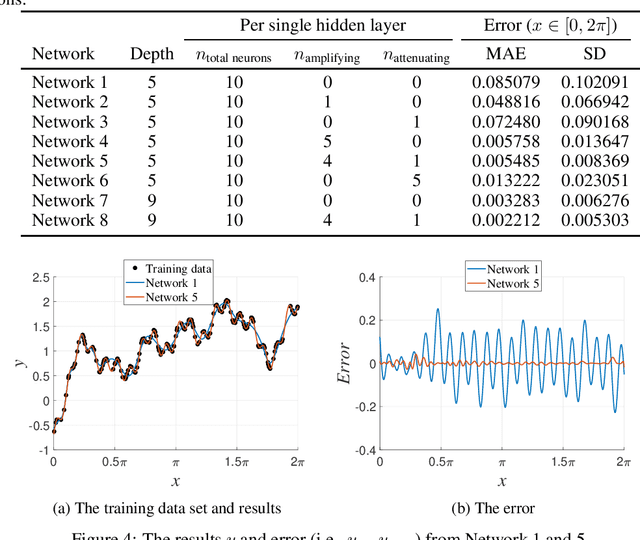
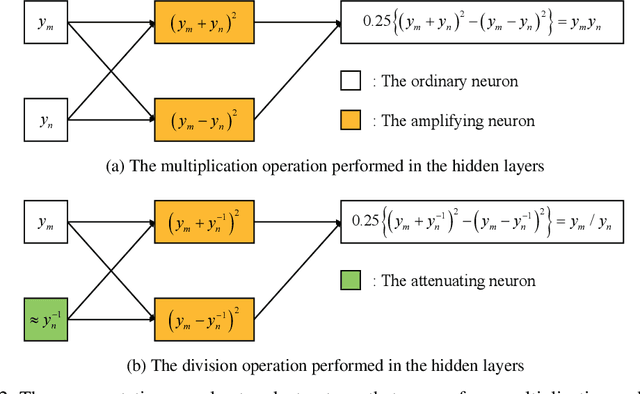

In the present study, an amplifying neuron and attenuating neuron, which can be easily implemented into neural networks without any significant additional computational effort, are proposed. The activated output value is squared for the amplifying neuron, while the value becomes its reciprocal for the attenuating one. Theoretically, the order of neural networks increases when the amplifying neuron is placed in the hidden layer. The performance assessments of neural networks were conducted to verify that the amplifying and attenuating neurons enhance the performance of neural networks. From the numerical experiments, it was revealed that the neural networks that contain the amplifying and attenuating neurons yield more accurate results, compared to those without them.