 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurboBoA: Faster and Exact Attention-aware Quantization without Backpropagation
Feb 04, 2026The rapid growth of large language models (LLMs) has heightened the importance of post-training quantization (PTQ) for reducing memory and computation costs. Among PTQ methods, GPTQ has gained significant attention for its efficiency, enabling billion-scale LLMs to be quantized within a few GPU hours. However, GPTQ's assumption of layer-wise independence leads to severe accuracy drops in low-bit regimes. Recently, BoA improved upon GPTQ by incorporating inter-layer dependencies within attention modules, but its reliance on sequential quantization across all out-channels makes it substantially less efficient. In this paper, we propose TurboBoA, a new backpropagation-free PTQ algorithm that preserves the accuracy benefits of BoA while significantly accelerating the process. The proposed TurboBoA introduces three key innovations: (i) joint quantization of multiple out-channels with a closed-form error compensation rule, which reduces sequential bottlenecks and yields more than a three-fold speedup; (ii) a correction mechanism for errors propagated from preceding quantized layers; and (iii) adaptive grid computation with coordinate descent refinement to maintain alignment during iterative updates. Extensive experiments demonstrate that TurboBoA delivers substantial acceleration over BoA while consistently improving accuracy. When combined with outlier suppression techniques, it achieves state-of-the-art results in both weight-only and weight-activation quantization. The code will be available at https://github.com/SamsungLabs/TurboBoA.
Attention-aware Post-training Quantization without Backpropagation
Jun 19, 2024



Quantization is a promising solution for deploying large-scale language models (LLMs) on resource-constrained devices. Existing quantization approaches, however, rely on gradient-based optimization, regardless of it being post-training quantization (PTQ) or quantization-aware training (QAT), which becomes problematic for hyper-scale LLMs with billions of parameters. This overhead can be alleviated via recently proposed backpropagation-free PTQ methods; however, their performance is somewhat limited by their lack of consideration of inter-layer dependencies. In this paper, we thus propose a novel PTQ algorithm that considers inter-layer dependencies without relying on backpropagation. The fundamental concept involved is the development of attention-aware Hessian matrices, which facilitates the consideration of inter-layer dependencies within the attention module. Extensive experiments demonstrate that the proposed algorithm significantly outperforms conventional PTQ methods, particularly for low bit-widths.
Towards Next-Level Post-Training Quantization of Hyper-Scale Transformers
Feb 14, 2024



With the increasing complexity of generative AI models, post-training quantization (PTQ) has emerged as a promising solution for deploying hyper-scale models on edge devices such as mobile devices and TVs. Existing PTQ schemes, however, consume considerable time and resources, which could be a bottleneck in real situations where frequent model updates and multiple hyper-parameter tunings are required. As a cost-effective alternative, one-shot PTQ schemes have been proposed. Still, the performance is somewhat limited because they cannot consider the inter-layer dependency within the attention module, which is a very important feature of Transformers. In this paper, we thus propose a novel PTQ algorithm that balances accuracy and efficiency. The key idea of the proposed algorithm called aespa is to perform quantization layer-wise for efficiency while considering cross-layer dependency to preserve the attention score. Through extensive experiments on various language models and complexity analysis, we demonstrate that aespa is accurate and efficient in quantizing Transformer models.
Intuitive Access to Smartphone Settings Using Relevance Model Trained by Contrastive Learning
Jul 15, 2023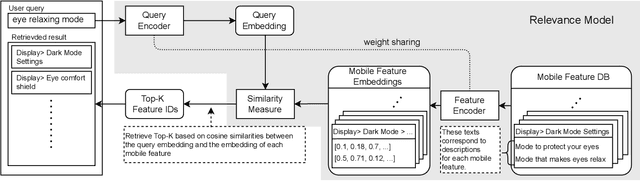
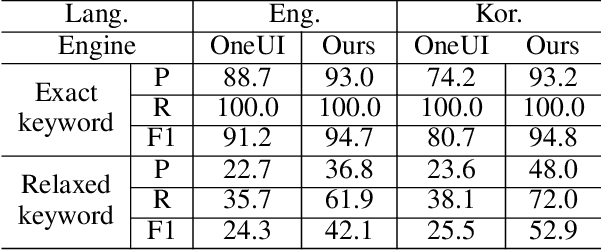
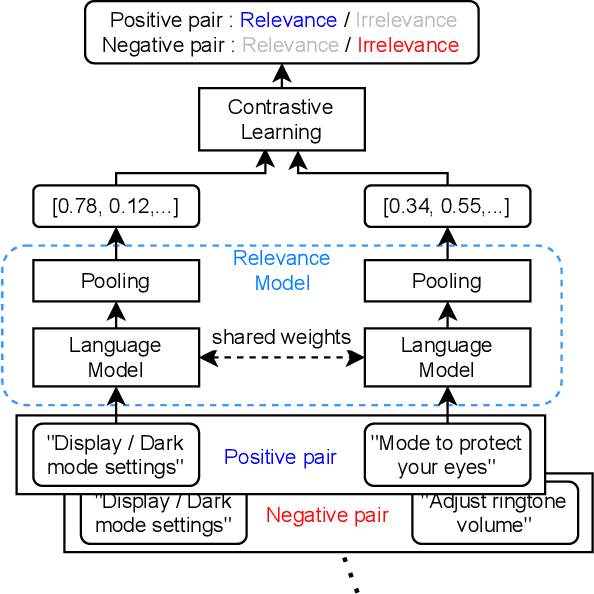

The more new features that are being added to smartphones, the harder it becomes for users to find them. This is because the feature names are usually short, and there are just too many to remember. In such a case, the users may want to ask contextual queries that describe the features they are looking for, but the standard term frequency-based search cannot process them. This paper presents a novel retrieval system for mobile features that accepts intuitive and contextual search queries. We trained a relevance model via contrastive learning from a pre-trained language model to perceive the contextual relevance between query embeddings and indexed mobile features. Also, to make it run efficiently on-device using minimal resources, we applied knowledge distillation to compress the model without degrading much performance. To verify the feasibility of our method, we collected test queries and conducted comparative experiments with the currently deployed search baselines. The results show that our system outperforms the others on contextual sentence queries and even on usual keyword-based queries.
Augment & Valuate : A Data Enhancement Pipeline for Data-Centric AI
Dec 07, 2021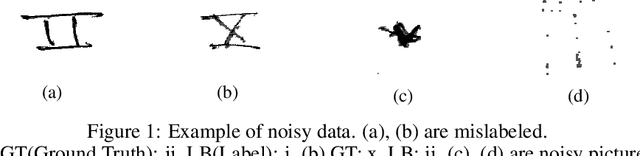



Data scarcity and noise are important issues in industrial applications of machine learning. However, it is often challenging to devise a scalable and generalized approach to address the fundamental distributional and semantic properties of dataset with black box models. For this reason, data-centric approaches are crucial for the automation of machine learning operation pipeline. In order to serve as the basis for this automation, we suggest a domain-agnostic pipeline for refining the quality of data in image classification problems. This pipeline contains data valuation, cleansing, and augmentation. With an appropriate combination of these methods, we could achieve 84.711% test accuracy (ranked #6, Honorable Mention in the Most Innovative) in the Data-Centric AI competition only with the provided dataset.
Neural Sequence-to-grid Module for Learning Symbolic Rules
Jan 13, 2021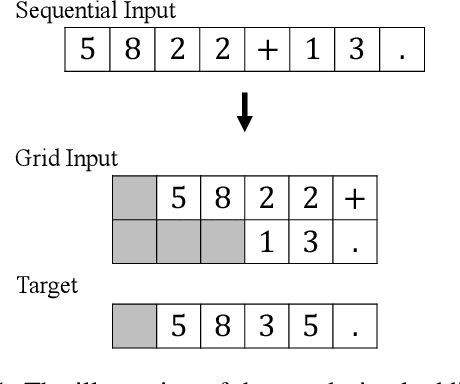
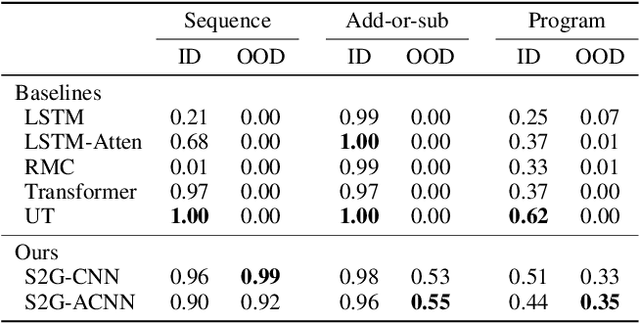
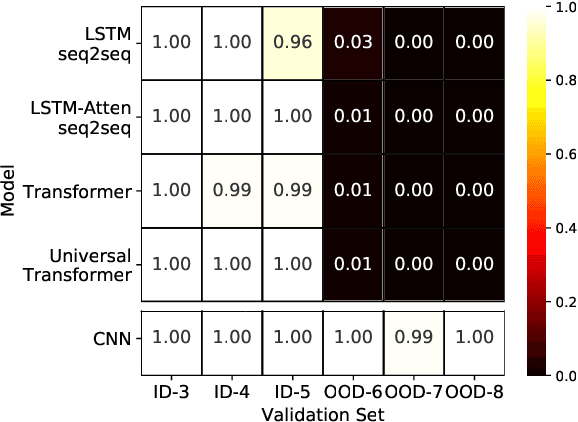
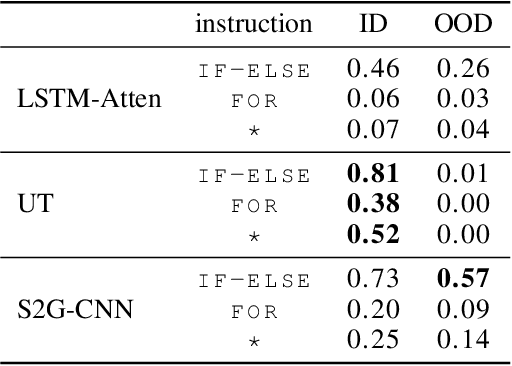
Logical reasoning tasks over symbols, such as learning arithmetic operations and computer program evaluations, have become challenges to deep learning. In particular, even state-of-the-art neural networks fail to achieve \textit{out-of-distribution} (OOD) generalization of symbolic reasoning tasks, whereas humans can easily extend learned symbolic rules. To resolve this difficulty, we propose a neural sequence-to-grid (seq2grid) module, an input preprocessor that automatically segments and aligns an input sequence into a grid. As our module outputs a grid via a novel differentiable mapping, any neural network structure taking a grid input, such as ResNet or TextCNN, can be jointly trained with our module in an end-to-end fashion. Extensive experiments show that neural networks having our module as an input preprocessor achieve OOD generalization on various arithmetic and algorithmic problems including number sequence prediction problems, algebraic word problems, and computer program evaluation problems while other state-of-the-art sequence transduction models cannot. Moreover, we verify that our module enhances TextCNN to solve the bAbI QA tasks without external memory.