 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurboBoA: Faster and Exact Attention-aware Quantization without Backpropagation
Feb 04, 2026The rapid growth of large language models (LLMs) has heightened the importance of post-training quantization (PTQ) for reducing memory and computation costs. Among PTQ methods, GPTQ has gained significant attention for its efficiency, enabling billion-scale LLMs to be quantized within a few GPU hours. However, GPTQ's assumption of layer-wise independence leads to severe accuracy drops in low-bit regimes. Recently, BoA improved upon GPTQ by incorporating inter-layer dependencies within attention modules, but its reliance on sequential quantization across all out-channels makes it substantially less efficient. In this paper, we propose TurboBoA, a new backpropagation-free PTQ algorithm that preserves the accuracy benefits of BoA while significantly accelerating the process. The proposed TurboBoA introduces three key innovations: (i) joint quantization of multiple out-channels with a closed-form error compensation rule, which reduces sequential bottlenecks and yields more than a three-fold speedup; (ii) a correction mechanism for errors propagated from preceding quantized layers; and (iii) adaptive grid computation with coordinate descent refinement to maintain alignment during iterative updates. Extensive experiments demonstrate that TurboBoA delivers substantial acceleration over BoA while consistently improving accuracy. When combined with outlier suppression techniques, it achieves state-of-the-art results in both weight-only and weight-activation quantization. The code will be available at https://github.com/SamsungLabs/TurboBoA.
Two-Stage Grid Optimization for Group-wise Quantization of LLMs
Feb 02, 2026Group-wise quantization is an effective strategy for mitigating accuracy degradation in low-bit quantization of large language models (LLMs). Among existing methods, GPTQ has been widely adopted due to its efficiency; however, it neglects input statistics and inter-group correlations when determining group scales, leading to a mismatch with its goal of minimizing layer-wise reconstruction loss. In this work, we propose a two-stage optimization framework for group scales that explicitly minimizes the layer-wise reconstruction loss. In the first stage, performed prior to GPTQ, we initialize each group scale to minimize the group-wise reconstruction loss, thereby incorporating input statistics. In the second stage, we freeze the integer weights obtained via GPTQ and refine the group scales to minimize the layer-wise reconstruction loss. To this end, we employ the coordinate descent algorithm and derive a closed-form update rule, which enables efficient refinement without costly numerical optimization. Notably, our derivation incorporates the quantization errors from preceding layers to prevent error accumulation. Experimental results demonstrate that our method consistently enhances group-wise quantization, achieving higher accuracy with negligible overhead.
Attention-aware Post-training Quantization without Backpropagation
Jun 19, 2024



Quantization is a promising solution for deploying large-scale language models (LLMs) on resource-constrained devices. Existing quantization approaches, however, rely on gradient-based optimization, regardless of it being post-training quantization (PTQ) or quantization-aware training (QAT), which becomes problematic for hyper-scale LLMs with billions of parameters. This overhead can be alleviated via recently proposed backpropagation-free PTQ methods; however, their performance is somewhat limited by their lack of consideration of inter-layer dependencies. In this paper, we thus propose a novel PTQ algorithm that considers inter-layer dependencies without relying on backpropagation. The fundamental concept involved is the development of attention-aware Hessian matrices, which facilitates the consideration of inter-layer dependencies within the attention module. Extensive experiments demonstrate that the proposed algorithm significantly outperforms conventional PTQ methods, particularly for low bit-widths.
Towards Next-Level Post-Training Quantization of Hyper-Scale Transformers
Feb 14, 2024



With the increasing complexity of generative AI models, post-training quantization (PTQ) has emerged as a promising solution for deploying hyper-scale models on edge devices such as mobile devices and TVs. Existing PTQ schemes, however, consume considerable time and resources, which could be a bottleneck in real situations where frequent model updates and multiple hyper-parameter tunings are required. As a cost-effective alternative, one-shot PTQ schemes have been proposed. Still, the performance is somewhat limited because they cannot consider the inter-layer dependency within the attention module, which is a very important feature of Transformers. In this paper, we thus propose a novel PTQ algorithm that balances accuracy and efficiency. The key idea of the proposed algorithm called aespa is to perform quantization layer-wise for efficiency while considering cross-layer dependency to preserve the attention score. Through extensive experiments on various language models and complexity analysis, we demonstrate that aespa is accurate and efficient in quantizing Transformer models.
Vision Transformer-based Feature Extraction for Generalized Zero-Shot Learning
Feb 02, 2023Generalized zero-shot learning (GZSL) is a technique to train a deep learning model to identify unseen classes using the image attribute. In this paper, we put forth a new GZSL approach exploiting Vision Transformer (ViT) to maximize the attribute-related information contained in the image feature. In ViT, the entire image region is processed without the degradation of the image resolution and the local image information is preserved in patch features. To fully enjoy these benefits of ViT, we exploit patch features as well as the CLS feature in extracting the attribute-related image feature. In particular, we propose a novel attention-based module, called attribute attention module (AAM), to aggregate the attribute-related information in patch features. In AAM, the correlation between each patch feature and the synthetic image attribute is used as the importance weight for each patch. From extensive experiments on benchmark datasets, we demonstrate that the proposed technique outperforms the state-of-the-art GZSL approaches by a large margin.
Semantic Feature Extraction for Generalized Zero-shot Learning
Dec 29, 2021

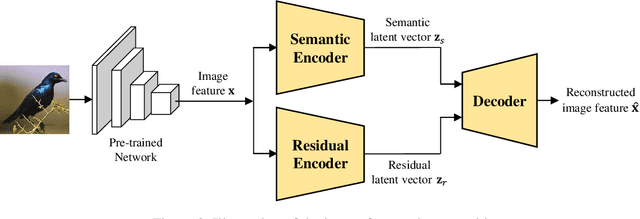
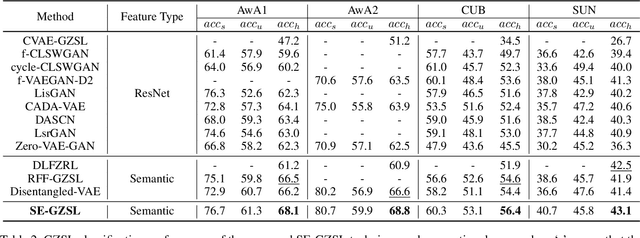
Generalized zero-shot learning (GZSL) is a technique to train a deep learning model to identify unseen classes using the attribute. In this paper, we put forth a new GZSL technique that improves the GZSL classification performance greatly. Key idea of the proposed approach, henceforth referred to as semantic feature extraction-based GZSL (SE-GZSL), is to use the semantic feature containing only attribute-related information in learning the relationship between the image and the attribute. In doing so, we can remove the interference, if any, caused by the attribute-irrelevant information contained in the image feature. To train a network extracting the semantic feature, we present two novel loss functions, 1) mutual information-based loss to capture all the attribute-related information in the image feature and 2) similarity-based loss to remove unwanted attribute-irrelevant information. From extensive experiments using various datasets, we show that the proposed SE-GZSL technique outperforms conventional GZSL approaches by a large margin.
Gradual Federated Learning with Simulated Annealing
Oct 11, 2021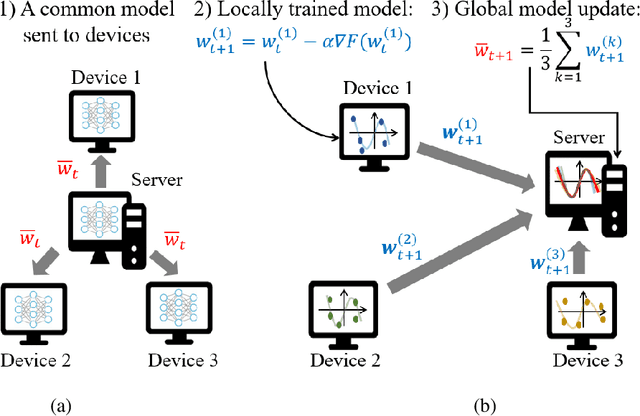
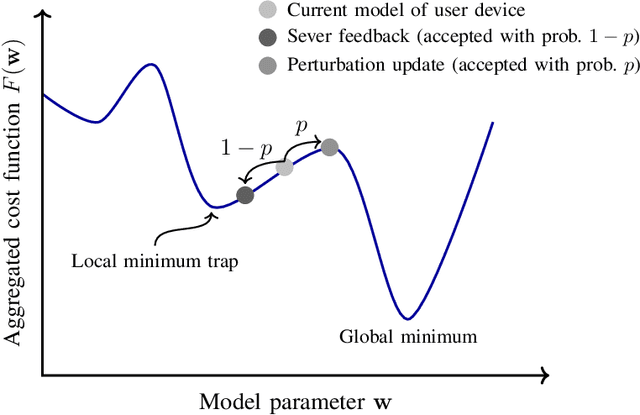
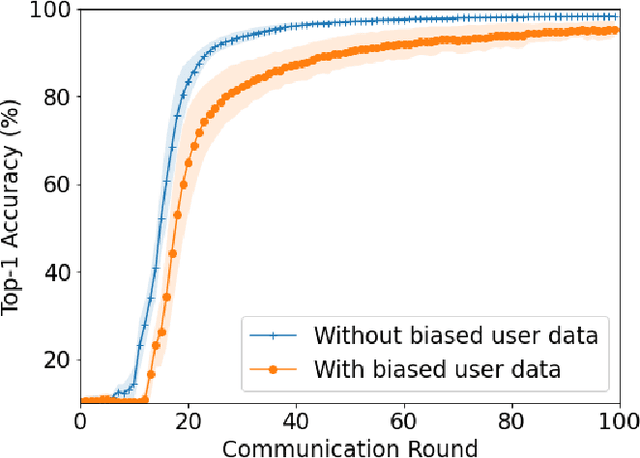
Federated averaging (FedAvg) is a popular federated learning (FL) technique that updates the global model by averaging local models and then transmits the updated global model to devices for their local model update. One main limitation of FedAvg is that the average-based global model is not necessarily better than local models in the early stage of the training process so that FedAvg might diverge in realistic scenarios, especially when the data is non-identically distributed across devices and the number of data samples varies significantly from device to device. In this paper, we propose a new FL technique based on simulated annealing. The key idea of the proposed technique, henceforth referred to as \textit{simulated annealing-based FL} (SAFL), is to allow a device to choose its local model when the global model is immature. Specifically, by exploiting the simulated annealing strategy, we make each device choose its local model with high probability in early iterations when the global model is immature. From extensive numerical experiments using various benchmark datasets, we demonstrate that SAFL outperforms the conventional FedAvg technique in terms of the convergence speed and the classification accuracy.