 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentLens: Adaptive Visual Modalities for Human-Agent Interaction in Mobile GUI Agents
Apr 22, 2026Mobile GUI agents can automate smartphone tasks by interacting directly with app interfaces, but how they should communicate with users during execution remains underexplored. Existing systems rely on two extremes: foreground execution, which maximizes transparency but prevents multitasking, and background execution, which supports multitasking but provides little visual awareness. Through iterative formative studies, we found that users prefer a hybrid model with just-in-time visual interaction, but the most effective visualization modality depends on the task. Motivated by this, we present AgentLens, a mobile GUI agent that adaptively uses three visual modalities during human-agent interaction: Full UI, Partial UI, and GenUI. AgentLens extends a standard mobile agent with adaptive communication actions and uses Virtual Display to enable background execution with selective visual overlays. In a controlled study with 21 participants, AgentLens was preferred by 85.7% of participants and achieved the highest usability (1.94 Overall PSSUQ) and adoption-intent (6.43/7).
Fuzzy Propositional Formulas under the Stable Model Semantics
Jun 15, 2025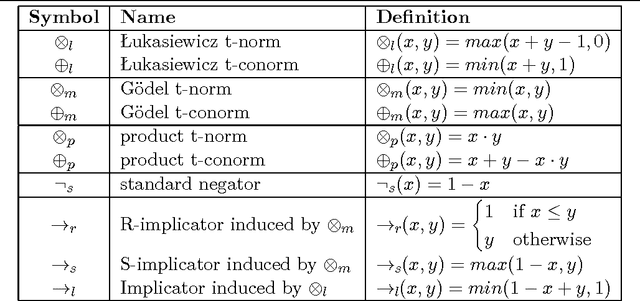
We define a stable model semantics for fuzzy propositional formulas, which generalizes both fuzzy propositional logic and the stable model semantics of classical propositional formulas. The syntax of the language is the same as the syntax of fuzzy propositional logic, but its semantics distinguishes stable models from non-stable models. The generality of the language allows for highly configurable nonmonotonic reasoning for dynamic domains involving graded truth degrees. We show that several properties of Boolean stable models are naturally extended to this many-valued setting, and discuss how it is related to other approaches to combining fuzzy logic and the stable model semantics.
LPMLN, Weak Constraints, and P-log
Jun 15, 2025LPMLN is a recently introduced formalism that extends answer set programs by adopting the log-linear weight scheme of Markov Logic. This paper investigates the relationships between LPMLN and two other extensions of answer set programs: weak constraints to express a quantitative preference among answer sets, and P-log to incorporate probabilistic uncertainty. We present a translation of LPMLN into programs with weak constraints and a translation of P-log into LPMLN, which complement the existing translations in the opposite directions. The first translation allows us to compute the most probable stable models (i.e., MAP estimates) of LPMLN programs using standard ASP solvers. This result can be extended to other formalisms, such as Markov Logic, ProbLog, and Pearl's Causal Models, that are shown to be translatable into LPMLN. The second translation tells us how probabilistic nonmonotonicity (the ability of the reasoner to change his probabilistic model as a result of new information) of P-log can be represented in LPMLN, which yields a way to compute P-log using standard ASP solvers and MLN solvers.
Think before You Simulate: Symbolic Reasoning to Orchestrate Neural Computation for Counterfactual Question Answering
Jun 12, 2025Causal and temporal reasoning about video dynamics is a challenging problem. While neuro-symbolic models that combine symbolic reasoning with neural-based perception and prediction have shown promise, they exhibit limitations, especially in answering counterfactual questions. This paper introduces a method to enhance a neuro-symbolic model for counterfactual reasoning, leveraging symbolic reasoning about causal relations among events. We define the notion of a causal graph to represent such relations and use Answer Set Programming (ASP), a declarative logic programming method, to find how to coordinate perception and simulation modules. We validate the effectiveness of our approach on two benchmarks, CLEVRER and CRAFT. Our enhancement achieves state-of-the-art performance on the CLEVRER challenge, significantly outperforming existing models. In the case of the CRAFT benchmark, we leverage a large pre-trained language model, such as GPT-3.5 and GPT-4, as a proxy for a dynamics simulator. Our findings show that this method can further improve its performance on counterfactual questions by providing alternative prompts instructed by symbolic causal reasoning.
System ASPMT2SMT:Computing ASPMT Theories by SMT Solvers
Jun 12, 2025Answer Set Programming Modulo Theories (ASPMT) is an approach to combining answer set programming and satisfiability modulo theories based on the functional stable model semantics. It is shown that the tight fragment of ASPMT programs can be turned into SMT instances, thereby allowing SMT solvers to compute stable models of ASPMT programs. In this paper we present a compiler called {\sc aspsmt2smt}, which implements this translation. The system uses ASP grounder {\sc gringo} and SMT solver {\sc z3}. {\sc gringo} partially grounds input programs while leaving some variables to be processed by {\sc z3}. We demonstrate that the system can effectively handle real number computations for reasoning about continuous changes.
LLM+AL: Bridging Large Language Models and Action Languages for Complex Reasoning about Actions
Jan 01, 2025



Large Language Models (LLMs) have made significant strides in various intelligent tasks but still struggle with complex action reasoning tasks that require systematic search. To address this limitation, we propose a method that bridges the natural language understanding capabilities of LLMs with the symbolic reasoning strengths of action languages. Our approach, termed "LLM+AL," leverages the LLM's strengths in semantic parsing and commonsense knowledge generation alongside the action language's proficiency in automated reasoning based on encoded knowledge. We compare LLM+AL against state-of-the-art LLMs, including ChatGPT-4, Claude 3 Opus, Gemini Ultra 1.0, and o1-preview, using benchmarks for complex reasoning about actions. Our findings indicate that, although all methods exhibit errors, LLM+AL, with relatively minimal human corrections, consistently leads to correct answers, whereas standalone LLMs fail to improve even with human feedback. LLM+AL also contributes to automated generation of action languages.
Game-Theoretic Joint Incentive and Cut Layer Selection Mechanism in Split Federated Learning
Dec 10, 2024



To alleviate the training burden in federated learning while enhancing convergence speed, Split Federated Learning (SFL) has emerged as a promising approach by combining the advantages of federated and split learning. However, recent studies have largely overlooked competitive situations. In this framework, the SFL model owner can choose the cut layer to balance the training load between the server and clients, ensuring the necessary level of privacy for the clients. Additionally, the SFL model owner sets incentives to encourage client participation in the SFL process. The optimization strategies employed by the SFL model owner influence clients' decisions regarding the amount of data they contribute, taking into account the shared incentives over clients and anticipated energy consumption during SFL. To address this framework, we model the problem using a hierarchical decision-making approach, formulated as a single-leader multi-follower Stackelberg game. We demonstrate the existence and uniqueness of the Nash equilibrium among clients and analyze the Stackelberg equilibrium by examining the leader's game. Furthermore, we discuss privacy concerns related to differential privacy and the criteria for selecting the minimum required cut layer. Our findings show that the Stackelberg equilibrium solution maximizes the utility for both the clients and the SFL model owner.
Compact and De-biased Negative Instance Embedding for Multi-Instance Learning on Whole-Slide Image Classification
Feb 16, 2024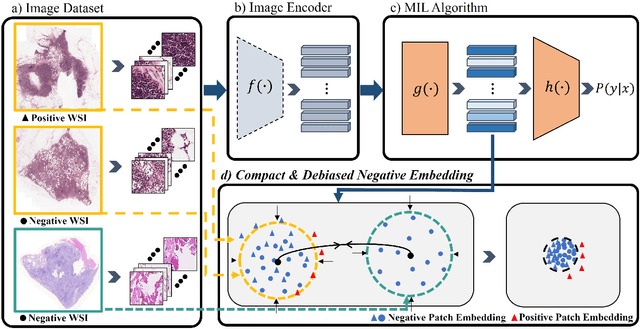
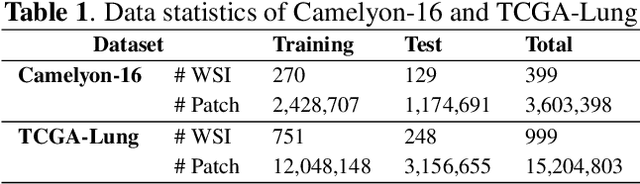
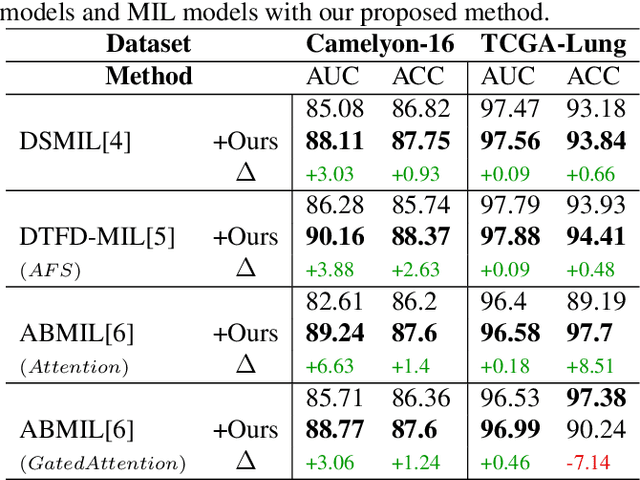
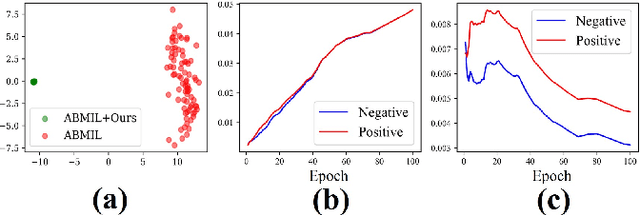
Whole-slide image (WSI) classification is a challenging task because 1) patches from WSI lack annotation, and 2) WSI possesses unnecessary variability, e.g., stain protocol. Recently, Multiple-Instance Learning (MIL) has made significant progress, allowing for classification based on slide-level, rather than patch-level, annotations. However, existing MIL methods ignore that all patches from normal slides are normal. Using this free annotation, we introduce a semi-supervision signal to de-bias the inter-slide variability and to capture the common factors of variation within normal patches. Because our method is orthogonal to the MIL algorithm, we evaluate our method on top of the recently proposed MIL algorithms and also compare the performance with other semi-supervised approaches. We evaluate our method on two public WSI datasets including Camelyon-16 and TCGA lung cancer and demonstrate that our approach significantly improves the predictive performance of existing MIL algorithms and outperforms other semi-supervised algorithms. We release our code at https://github.com/AITRICS/pathology_mil.
Exploring the Privacy-Energy Consumption Tradeoff for Split Federated Learning
Nov 15, 2023



Split Federated Learning (SFL) has recently emerged as a promising distributed learning technology, leveraging the strengths of both federated learning and split learning. It emphasizes the advantages of rapid convergence while addressing privacy concerns. As a result, this innovation has received significant attention from both industry and academia. However, since the model is split at a specific layer, known as a cut layer, into both client-side and server-side models for the SFL, the choice of the cut layer in SFL can have a substantial impact on the energy consumption of clients and their privacy, as it influences the training burden and the output of the client-side models. Moreover, the design challenge of determining the cut layer is highly intricate, primarily due to the inherent heterogeneity in the computing and networking capabilities of clients. In this article, we provide a comprehensive overview of the SFL process and conduct a thorough analysis of energy consumption and privacy. This analysis takes into account the influence of various system parameters on the cut layer selection strategy. Additionally, we provide an illustrative example of the cut layer selection, aiming to minimize the risk of clients from reconstructing the raw data at the server while sustaining energy consumption within the required energy budget, which involve trade-offs. Finally, we address open challenges in this field including their applications to 6G technology. These directions represent promising avenues for future research and development.
Elementary Sets for Logic Programs
Jul 15, 2023By introducing the concepts of a loop and a loop formula, Lin and Zhao showed that the answer sets of a nondisjunctive logic program are exactly the models of its Clark's completion that satisfy the loop formulas of all loops. Recently, Gebser and Schaub showed that the Lin-Zhao theorem remains correct even if we restrict loop formulas to a special class of loops called ``elementary loops.'' In this paper, we simplify and generalize the notion of an elementary loop, and clarify its role. We propose the notion of an elementary set, which is almost equivalent to the notion of an elementary loop for nondisjunctive programs, but is simpler, and, unlike elementary loops, can be extended to disjunctive programs without producing unintuitive results. We show that the maximal unfounded elementary sets for the ``relevant'' part of a program are exactly the minimal sets among the nonempty unfounded sets. We also present a graph-theoretic characterization of elementary sets for nondisjunctive programs, which is simpler than the one proposed in (Gebser & Schaub 2005). Unlike the case of nondisjunctive programs, we show that the problem of deciding an elementary set is coNP-complete for disjunctive programs.