 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Model-Driven Framework for Human-Object Interaction Prediction with Segmentation Mask Integration
Apr 28, 2025In this work, we introduce Segmentation to Human-Object Interaction (\textit{\textbf{Seg2HOI}}) approach, a novel framework that integrates segmentation-based vision foundation models with the human-object interaction task, distinguished from traditional detection-based Human-Object Interaction (HOI) methods. Our approach enhances HOI detection by not only predicting the standard triplets but also introducing quadruplets, which extend HOI triplets by including segmentation masks for human-object pairs. More specifically, Seg2HOI inherits the properties of the vision foundation model (e.g., promptable and interactive mechanisms) and incorporates a decoder that applies these attributes to HOI task. Despite training only for HOI, without additional training mechanisms for these properties, the framework demonstrates that such features still operate efficiently. Extensive experiments on two public benchmark datasets demonstrate that Seg2HOI achieves performance comparable to state-of-the-art methods, even in zero-shot scenarios. Lastly, we propose that Seg2HOI can generate HOI quadruplets and interactive HOI segmentation from novel text and visual prompts that were not used during training, making it versatile for a wide range of applications by leveraging this flexibility.
Game-Theoretic Joint Incentive and Cut Layer Selection Mechanism in Split Federated Learning
Dec 10, 2024



To alleviate the training burden in federated learning while enhancing convergence speed, Split Federated Learning (SFL) has emerged as a promising approach by combining the advantages of federated and split learning. However, recent studies have largely overlooked competitive situations. In this framework, the SFL model owner can choose the cut layer to balance the training load between the server and clients, ensuring the necessary level of privacy for the clients. Additionally, the SFL model owner sets incentives to encourage client participation in the SFL process. The optimization strategies employed by the SFL model owner influence clients' decisions regarding the amount of data they contribute, taking into account the shared incentives over clients and anticipated energy consumption during SFL. To address this framework, we model the problem using a hierarchical decision-making approach, formulated as a single-leader multi-follower Stackelberg game. We demonstrate the existence and uniqueness of the Nash equilibrium among clients and analyze the Stackelberg equilibrium by examining the leader's game. Furthermore, we discuss privacy concerns related to differential privacy and the criteria for selecting the minimum required cut layer. Our findings show that the Stackelberg equilibrium solution maximizes the utility for both the clients and the SFL model owner.
Gaussian Mixture Proposals with Pull-Push Learning Scheme to Capture Diverse Events for Weakly Supervised Temporal Video Grounding
Dec 27, 2023



In the weakly supervised temporal video grounding study, previous methods use predetermined single Gaussian proposals which lack the ability to express diverse events described by the sentence query. To enhance the expression ability of a proposal, we propose a Gaussian mixture proposal (GMP) that can depict arbitrary shapes by learning importance, centroid, and range of every Gaussian in the mixture. In learning GMP, each Gaussian is not trained in a feature space but is implemented over a temporal location. Thus the conventional feature-based learning for Gaussian mixture model is not valid for our case. In our special setting, to learn moderately coupled Gaussian mixture capturing diverse events, we newly propose a pull-push learning scheme using pulling and pushing losses, each of which plays an opposite role to the other. The effects of components in our scheme are verified in-depth with extensive ablation studies and the overall scheme achieves state-of-the-art performance. Our code is available at https://github.com/sunoh-kim/pps.
Exploring the Privacy-Energy Consumption Tradeoff for Split Federated Learning
Nov 15, 2023



Split Federated Learning (SFL) has recently emerged as a promising distributed learning technology, leveraging the strengths of both federated learning and split learning. It emphasizes the advantages of rapid convergence while addressing privacy concerns. As a result, this innovation has received significant attention from both industry and academia. However, since the model is split at a specific layer, known as a cut layer, into both client-side and server-side models for the SFL, the choice of the cut layer in SFL can have a substantial impact on the energy consumption of clients and their privacy, as it influences the training burden and the output of the client-side models. Moreover, the design challenge of determining the cut layer is highly intricate, primarily due to the inherent heterogeneity in the computing and networking capabilities of clients. In this article, we provide a comprehensive overview of the SFL process and conduct a thorough analysis of energy consumption and privacy. This analysis takes into account the influence of various system parameters on the cut layer selection strategy. Additionally, we provide an illustrative example of the cut layer selection, aiming to minimize the risk of clients from reconstructing the raw data at the server while sustaining energy consumption within the required energy budget, which involve trade-offs. Finally, we address open challenges in this field including their applications to 6G technology. These directions represent promising avenues for future research and development.
Texture Generation Using Dual-Domain Feature Flow with Multi-View Hallucinations
Mar 14, 2022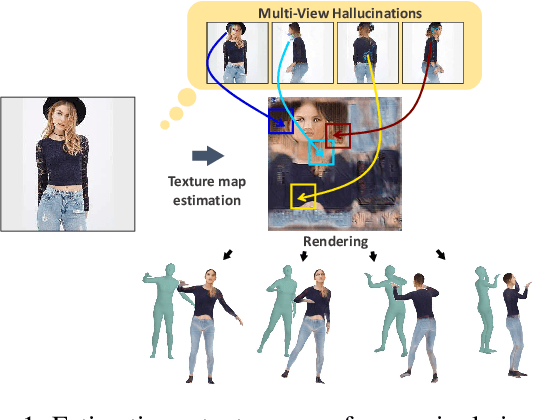
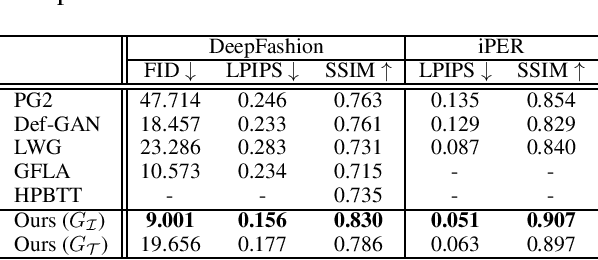
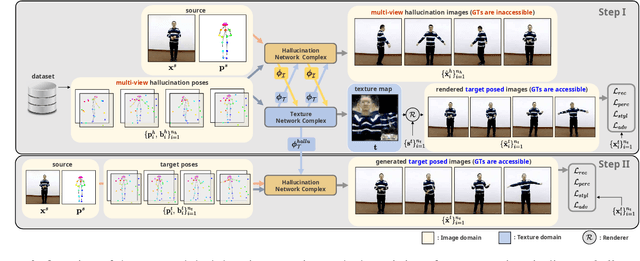
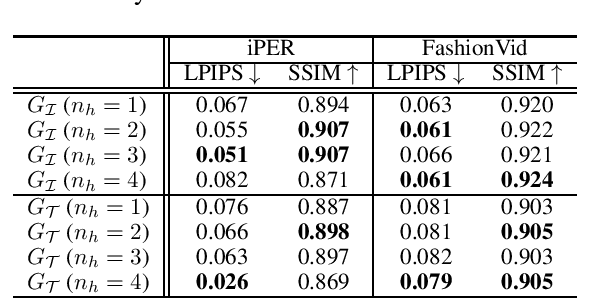
We propose a dual-domain generative model to estimate a texture map from a single image for colorizing a 3D human model. When estimating a texture map, a single image is insufficient as it reveals only one facet of a 3D object. To provide sufficient information for estimating a complete texture map, the proposed model simultaneously generates multi-view hallucinations in the image domain and an estimated texture map in the texture domain. During the generating process, each domain generator exchanges features to the other by a flow-based local attention mechanism. In this manner, the proposed model can estimate a texture map utilizing abundant multi-view image features from which multiview hallucinations are generated. As a result, the estimated texture map contains consistent colors and patterns over the entire region. Experiments show the superiority of our model for estimating a directly render-able texture map, which is applicable to 3D animation rendering. Furthermore, our model also improves an overall generation quality in the image domain for pose and viewpoint transfer tasks.
Robust Pedestrian Attribute Recognition Using Group Sparsity for Occlusion Videos
Oct 17, 2021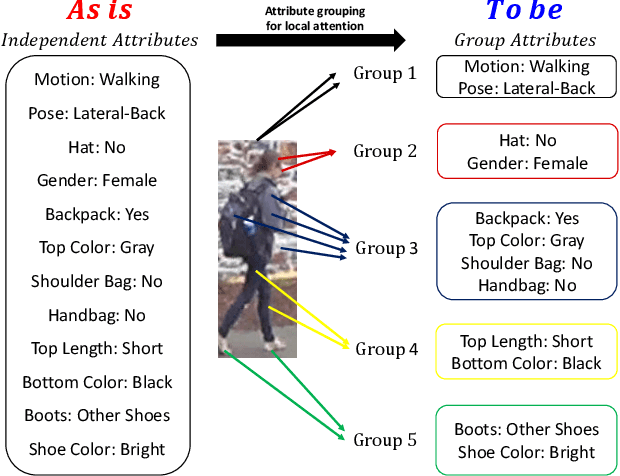
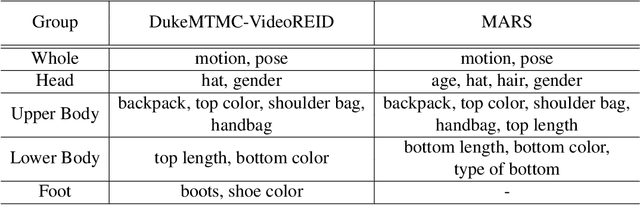
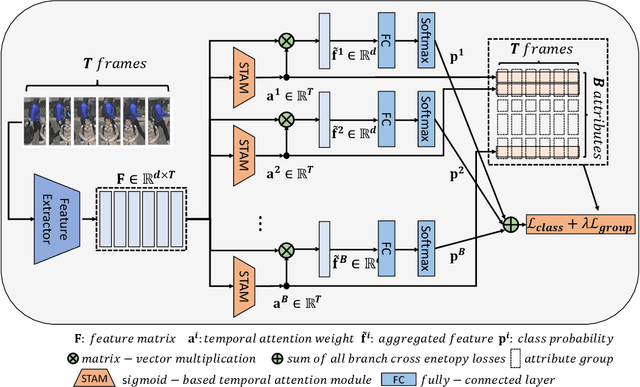
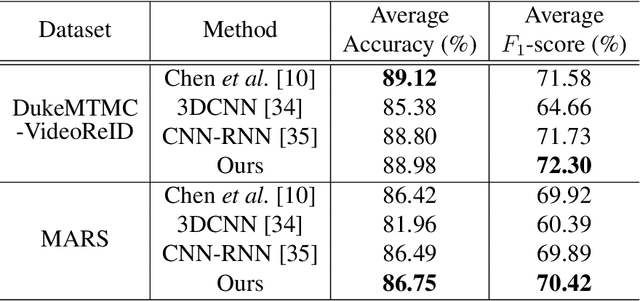
Occlusion processing is a key issue in pedestrian attribute recognition (PAR). Nevertheless, several existing video-based PAR methods have not yet considered occlusion handling in depth. In this paper, we formulate finding non-occluded frames as sparsity-based temporal attention of a crowded video. In this manner, a model is guided not to pay attention to the occluded frame. However, temporal sparsity cannot include a correlation between attributes when occlusion occurs. For example, "boots" and "shoe color" cannot be recognized when the foot is invisible. To solve the uncorrelated attention issue, we also propose a novel group sparsity-based temporal attention module. Group sparsity is applied across attention weights in correlated attributes. Thus, attention weights in a group are forced to pay attention to the same frames. Experimental results showed that the proposed method achieved a higher F1-score than the state-of-the-art methods on two video-based PAR datasets and five occlusion scenarios.
Deep Pose Consensus Networks
Mar 22, 2018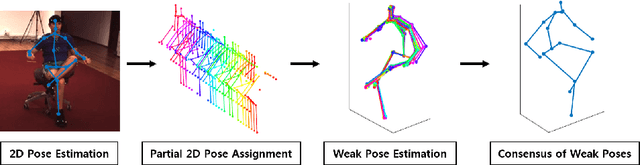
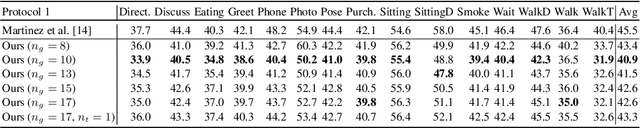
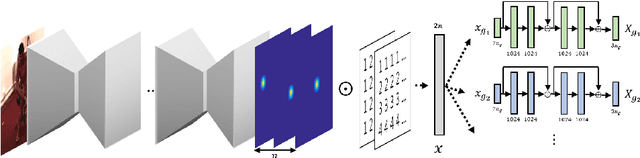
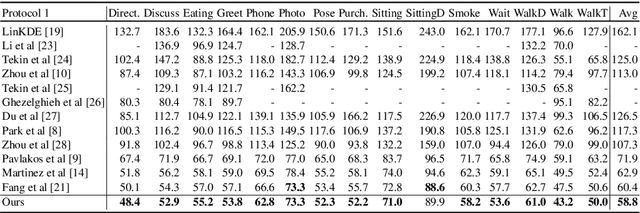
In this paper, we address the problem of estimating a 3D human pose from a single image, which is important but difficult to solve due to many reasons, such as self-occlusions, wild appearance changes, and inherent ambiguities of 3D estimation from a 2D cue. These difficulties make the problem ill-posed, which have become requiring increasingly complex estimators to enhance the performance. On the other hand, most existing methods try to handle this problem based on a single complex estimator, which might not be good solutions. In this paper, to resolve this issue, we propose a multiple-partial-hypothesis-based framework for the problem of estimating 3D human pose from a single image, which can be fine-tuned in an end-to-end fashion. We first select several joint groups from a human joint model using the proposed sampling scheme, and estimate the 3D poses of each joint group separately based on deep neural networks. After that, they are aggregated to obtain the final 3D poses using the proposed robust optimization formula. The overall procedure can be fine-tuned in an end-to-end fashion, resulting in better performance. In the experiments, the proposed framework shows the state-of-the-art performances on popular benchmark data sets, namely Human3.6M and HumanEva, which demonstrate the effectiveness of the proposed framework.