 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Pose Consensus Networks
Paper and Code
Mar 22, 2018
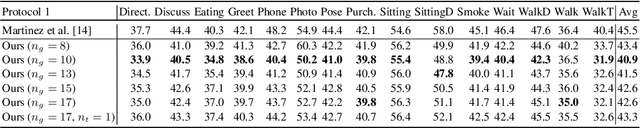
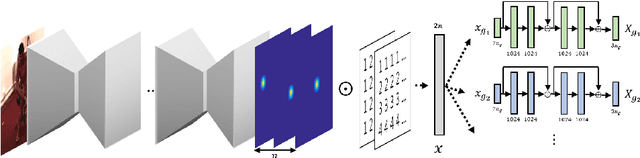
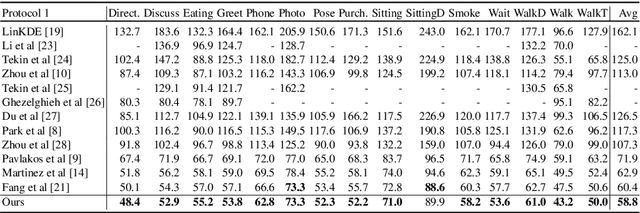
In this paper, we address the problem of estimating a 3D human pose from a single image, which is important but difficult to solve due to many reasons, such as self-occlusions, wild appearance changes, and inherent ambiguities of 3D estimation from a 2D cue. These difficulties make the problem ill-posed, which have become requiring increasingly complex estimators to enhance the performance. On the other hand, most existing methods try to handle this problem based on a single complex estimator, which might not be good solutions. In this paper, to resolve this issue, we propose a multiple-partial-hypothesis-based framework for the problem of estimating 3D human pose from a single image, which can be fine-tuned in an end-to-end fashion. We first select several joint groups from a human joint model using the proposed sampling scheme, and estimate the 3D poses of each joint group separately based on deep neural networks. After that, they are aggregated to obtain the final 3D poses using the proposed robust optimization formula. The overall procedure can be fine-tuned in an end-to-end fashion, resulting in better performance. In the experiments, the proposed framework shows the state-of-the-art performances on popular benchmark data sets, namely Human3.6M and HumanEva, which demonstrate the effectiveness of the proposed framework.