 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Optimal Video Moment without Training: Gaussian Boundary Optimization for Weakly Supervised Video Grounding
Feb 03, 2026Weakly supervised temporal video grounding aims to localize query-relevant segments in untrimmed videos using only video-sentence pairs, without requiring ground-truth segment annotations that specify exact temporal boundaries. Recent approaches tackle this task by utilizing Gaussian-based temporal proposals to represent query-relevant segments. However, their inference strategies rely on heuristic mappings from Gaussian parameters to segment boundaries, resulting in suboptimal localization performance. To address this issue, we propose Gaussian Boundary Optimization (GBO), a novel inference framework that predicts segment boundaries by solving a principled optimization problem that balances proposal coverage and segment compactness. We derive a closed-form solution for this problem and rigorously analyze the optimality conditions under varying penalty regimes. Beyond its theoretical foundations, GBO offers several practical advantages: it is training-free and compatible with both single-Gaussian and mixture-based proposal architectures. Our experiments show that GBO significantly improves localization, achieving state-of-the-art results across standard benchmarks. Extensive experiments demonstrate the efficiency and generalizability of GBO across various proposal schemes. The code is available at \href{https://github.com/sunoh-kim/gbo}{https://github.com/sunoh-kim/gbo}.
Distributional Uncertainty for Out-of-Distribution Detection
Jul 24, 2025



Estimating uncertainty from deep neural networks is a widely used approach for detecting out-of-distribution (OoD) samples, which typically exhibit high predictive uncertainty. However, conventional methods such as Monte Carlo (MC) Dropout often focus solely on either model or data uncertainty, failing to align with the semantic objective of OoD detection. To address this, we propose the Free-Energy Posterior Network, a novel framework that jointly models distributional uncertainty and identifying OoD and misclassified regions using free energy. Our method introduces two key contributions: (1) a free-energy-based density estimator parameterized by a Beta distribution, which enables fine-grained uncertainty estimation near ambiguous or unseen regions; and (2) a loss integrated within a posterior network, allowing direct uncertainty estimation from learned parameters without requiring stochastic sampling. By integrating our approach with the residual prediction branch (RPL) framework, the proposed method goes beyond post-hoc energy thresholding and enables the network to learn OoD regions by leveraging the variance of the Beta distribution, resulting in a semantically meaningful and computationally efficient solution for uncertainty-aware segmentation. We validate the effectiveness of our method on challenging real-world benchmarks, including Fishyscapes, RoadAnomaly, and Segment-Me-If-You-Can.
Customizing Segmentation Foundation Model via Prompt Learning for Instance Segmentation
Mar 14, 2024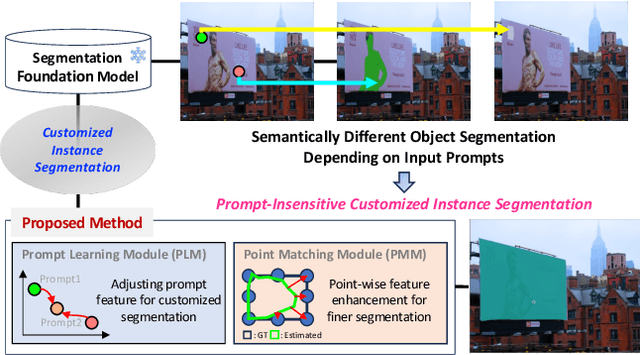


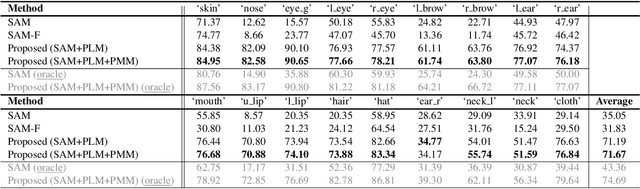
Recently, foundation models trained on massive datasets to adapt to a wide range of domains have attracted considerable attention and are actively being explored within the computer vision community. Among these, the Segment Anything Model (SAM) stands out for its remarkable progress in generalizability and flexibility for image segmentation tasks, achieved through prompt-based object mask generation. However, despite its strength, SAM faces two key limitations when applied to customized instance segmentation that segments specific objects or those in unique environments not typically present in the training data: 1) the ambiguity inherent in input prompts and 2) the necessity for extensive additional training to achieve optimal segmentation. To address these challenges, we propose a novel method, customized instance segmentation via prompt learning tailored to SAM. Our method involves a prompt learning module (PLM), which adjusts input prompts into the embedding space to better align with user intentions, thereby enabling more efficient training. Furthermore, we introduce a point matching module (PMM) to enhance the feature representation for finer segmentation by ensuring detailed alignment with ground truth boundaries. Experimental results on various customized instance segmentation scenarios demonstrate the effectiveness of the proposed method.
Face Shape-Guided Deep Feature Alignment for Face Recognition Robust to Face Misalignment
Sep 15, 2022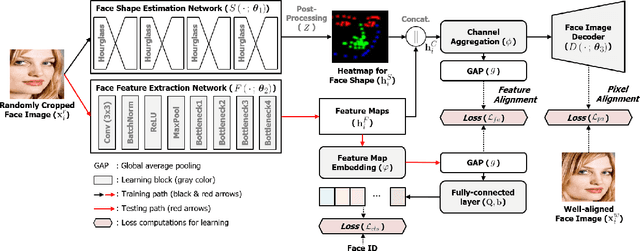
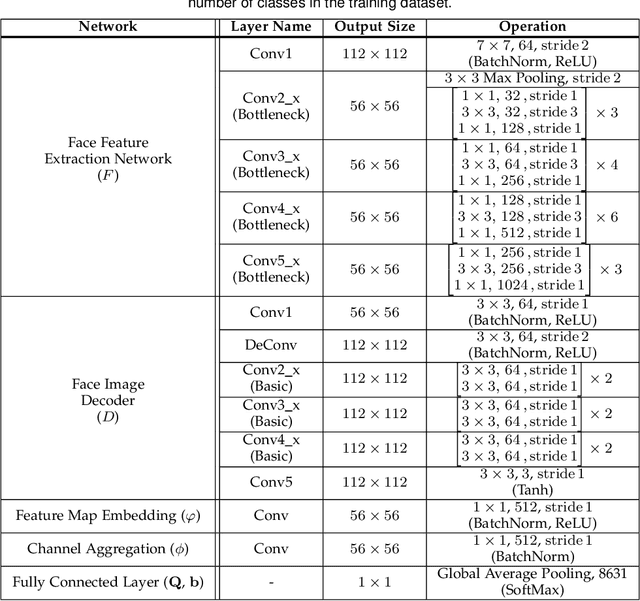
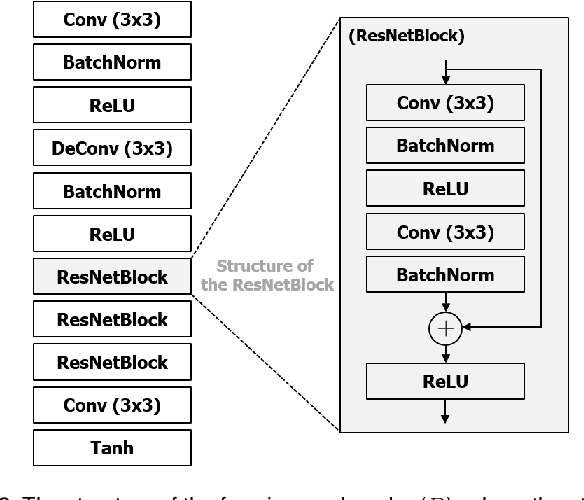
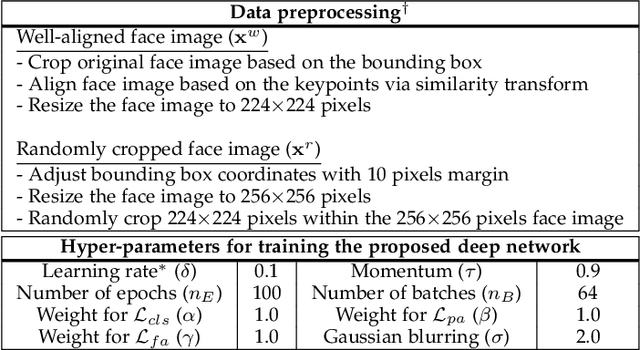
For the past decades, face recognition (FR) has been actively studied in computer vision and pattern recognition society. Recently, due to the advances in deep learning, the FR technology shows high performance for most of the benchmark datasets. However, when the FR algorithm is applied to a real-world scenario, the performance has been known to be still unsatisfactory. This is mainly attributed to the mismatch between training and testing sets. Among such mismatches, face misalignment between training and testing faces is one of the factors that hinder successful FR. To address this limitation, we propose a face shape-guided deep feature alignment framework for FR robust to the face misalignment. Based on a face shape prior (e.g., face keypoints), we train the proposed deep network by introducing alignment processes, i.e., pixel and feature alignments, between well-aligned and misaligned face images. Through the pixel alignment process that decodes the aggregated feature extracted from a face image and face shape prior, we add the auxiliary task to reconstruct the well-aligned face image. Since the aggregated features are linked to the face feature extraction network as a guide via the feature alignment process, we train the robust face feature to the face misalignment. Even if the face shape estimation is required in the training stage, the additional face alignment process, which is usually incorporated in the conventional FR pipeline, is not necessarily needed in the testing phase. Through the comparative experiments, we validate the effectiveness of the proposed method for the face misalignment with the FR datasets.
Position-aware Location Regression Network for Temporal Video Grounding
Apr 12, 2022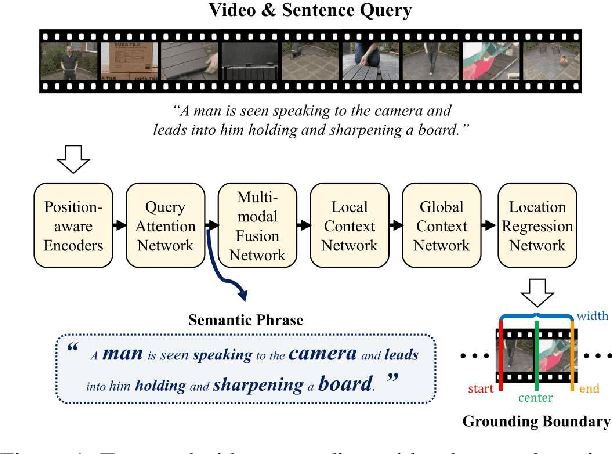
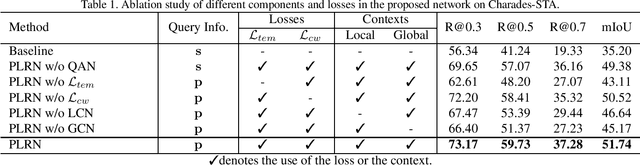
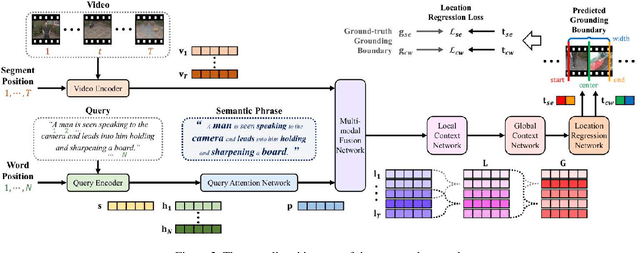

The key to successful grounding for video surveillance is to understand a semantic phrase corresponding to important actors and objects. Conventional methods ignore comprehensive contexts for the phrase or require heavy computation for multiple phrases. To understand comprehensive contexts with only one semantic phrase, we propose Position-aware Location Regression Network (PLRN) which exploits position-aware features of a query and a video. Specifically, PLRN first encodes both the video and query using positional information of words and video segments. Then, a semantic phrase feature is extracted from an encoded query with attention. The semantic phrase feature and encoded video are merged and made into a context-aware feature by reflecting local and global contexts. Finally, PLRN predicts start, end, center, and width values of a grounding boundary. Our experiments show that PLRN achieves competitive performance over existing methods with less computation time and memory.
Robust Pedestrian Attribute Recognition Using Group Sparsity for Occlusion Videos
Oct 17, 2021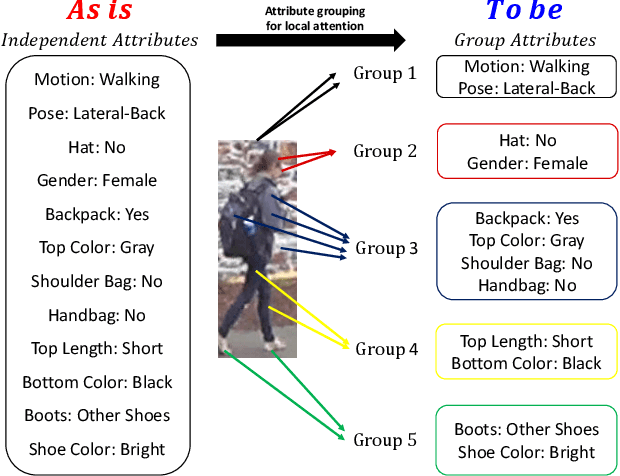
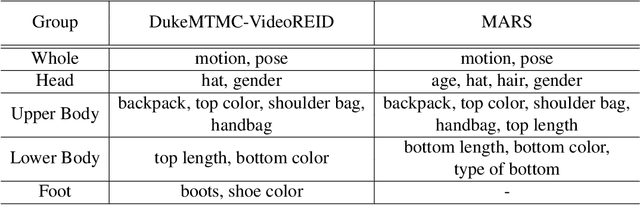
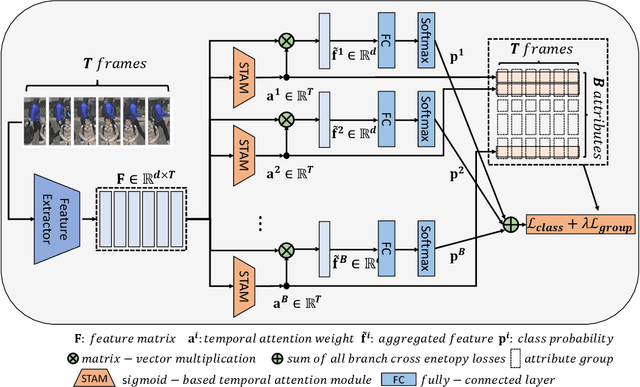
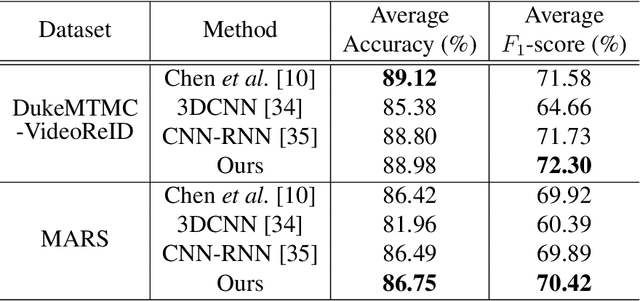
Occlusion processing is a key issue in pedestrian attribute recognition (PAR). Nevertheless, several existing video-based PAR methods have not yet considered occlusion handling in depth. In this paper, we formulate finding non-occluded frames as sparsity-based temporal attention of a crowded video. In this manner, a model is guided not to pay attention to the occluded frame. However, temporal sparsity cannot include a correlation between attributes when occlusion occurs. For example, "boots" and "shoe color" cannot be recognized when the foot is invisible. To solve the uncorrelated attention issue, we also propose a novel group sparsity-based temporal attention module. Group sparsity is applied across attention weights in correlated attributes. Thus, attention weights in a group are forced to pay attention to the same frames. Experimental results showed that the proposed method achieved a higher F1-score than the state-of-the-art methods on two video-based PAR datasets and five occlusion scenarios.
Diverse Temporal Aggregation and Depthwise Spatiotemporal Factorization for Efficient Video Classification
Dec 28, 2020

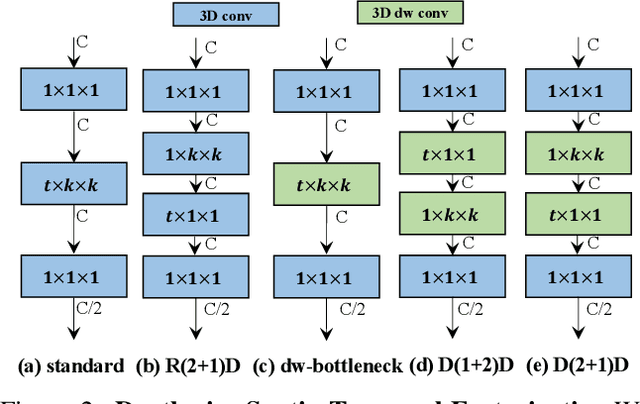

Video classification researches that have recently attracted attention are the fields of temporal modeling and 3D efficient architecture. However, the temporal modeling methods are not efficient or the 3D efficient architecture is less interested in temporal modeling. For bridging the gap between them, we propose an efficient temporal modeling 3D architecture, called VoV3D, that consists of a temporal one-shot aggregation (T-OSA) module and depthwise factorized component, D(2+1)D. The T-OSA is devised to build a feature hierarchy by aggregating temporal features with different temporal receptive fields. Stacking this T-OSA enables the network itself to model short-range as well as long-range temporal relationships across frames without any external modules. Inspired by kernel factorization and channel factorization, we also design a depthwise spatiotemporal factorization module, named, D(2+1)D that decomposes a 3D depthwise convolution into two spatial and temporal depthwise convolutions for making our network more lightweight and efficient. By using the proposed temporal modeling method (T-OSA), and the efficient factorized component (D(2+1)D), we construct two types of VoV3D networks, VoV3D-M and VoV3D-L. Thanks to its efficiency and effectiveness of temporal modeling, VoV3D-L has 6x fewer model parameters and 16x less computation, surpassing a state-of-the-art temporal modeling method on both Something-Something and Kinetics-400. Furthermore, VoV3D shows better temporal modeling ability than a state-of-the-art efficient 3D architecture, X3D having comparable model capacity. We hope that VoV3D can serve as a baseline for efficient video classification.
Localization Uncertainty Estimation for Anchor-Free Object Detection
Jun 28, 2020

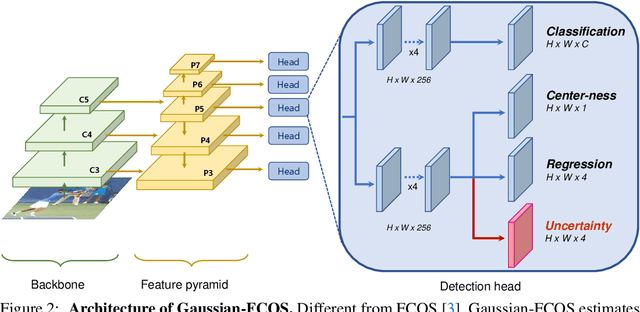
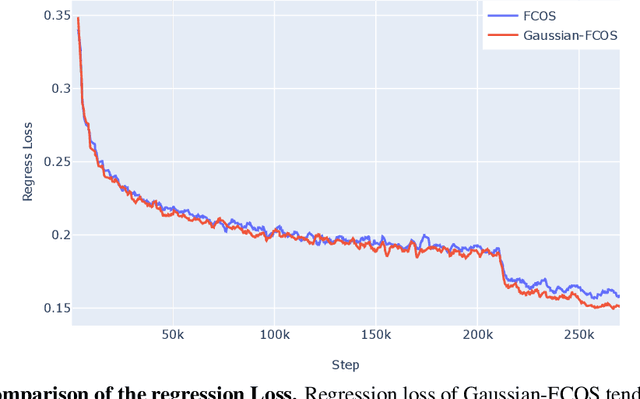
Since many safety-critical systems such as surgical robots and autonomous driving cars are in unstable environments with sensor noise or incomplete data, it is desirable for object detectors to take the confidence of the localization prediction into account. Recent attempts to estimate localization uncertainty for object detection focus only anchor-based method that captures the uncertainty of different characteristics such as location (center point) and scale (width, height). Also, anchor-based methods need to adjust sensitive anchor-box settings. Therefore, we propose a new object detector called Gaussian-FCOS that estimates the localization uncertainty based on an anchor-free detector that captures the uncertainty of similar property with four directions of box offsets (left, right, top, bottom) and avoids the anchor tuning. For this purpose, we design a new loss function, uncertainty loss, to measure how uncertain the estimated object location is by modeling the uncertainty as a Gaussian distribution. Then, the detection score is calibrated through the estimated uncertainty. Experiments on challenging COCO datasets demonstrate that the proposed new loss function not only enables the network to estimate the uncertainty but produces a synergy effect with regression loss. In addition, our Gaussian-FCOS reduces false positives with the estimated localization uncertainty and finds more missing-objects, boosting both Average Precision (AP) and Recall (AR). We hope Gaussian-FCOS serve as a baseline for the reliability-required task.
Skeleton-based Action Recognition of People Handling Objects
Jan 21, 2019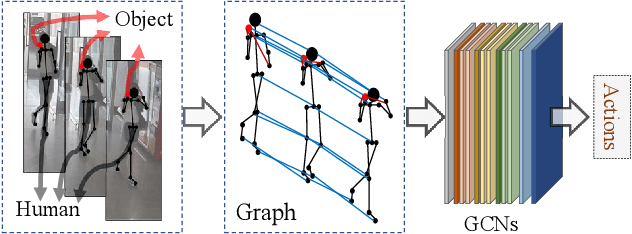


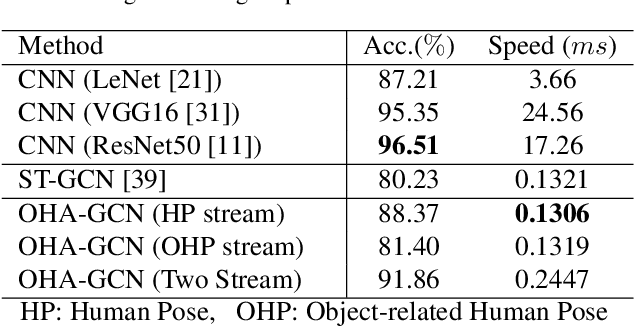
In visual surveillance systems, it is necessary to recognize the behavior of people handling objects such as a phone, a cup, or a plastic bag. In this paper, to address this problem, we propose a new framework for recognizing object-related human actions by graph convolutional networks using human and object poses. In this framework, we construct skeletal graphs of reliable human poses by selectively sampling the informative frames in a video, which include human joints with high confidence scores obtained in pose estimation. The skeletal graphs generated from the sampled frames represent human poses related to the object position in both the spatial and temporal domains, and these graphs are used as inputs to the graph convolutional networks. Through experiments over an open benchmark and our own data sets, we verify the validity of our framework in that our method outperforms the state-of-the-art method for skeleton-based action recognition.