 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Temporal Aggregation and Depthwise Spatiotemporal Factorization for Efficient Video Classification
Paper and Code
Dec 28, 2020

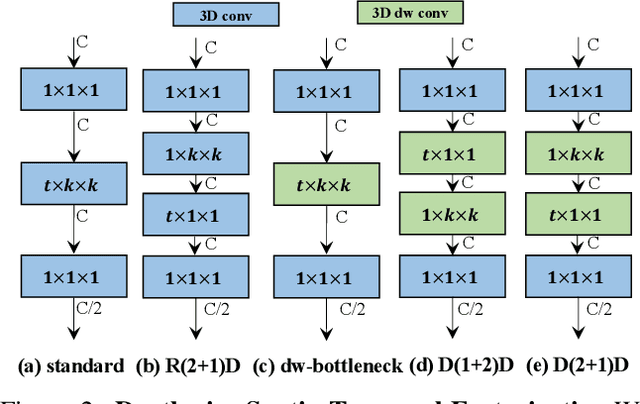

Video classification researches that have recently attracted attention are the fields of temporal modeling and 3D efficient architecture. However, the temporal modeling methods are not efficient or the 3D efficient architecture is less interested in temporal modeling. For bridging the gap between them, we propose an efficient temporal modeling 3D architecture, called VoV3D, that consists of a temporal one-shot aggregation (T-OSA) module and depthwise factorized component, D(2+1)D. The T-OSA is devised to build a feature hierarchy by aggregating temporal features with different temporal receptive fields. Stacking this T-OSA enables the network itself to model short-range as well as long-range temporal relationships across frames without any external modules. Inspired by kernel factorization and channel factorization, we also design a depthwise spatiotemporal factorization module, named, D(2+1)D that decomposes a 3D depthwise convolution into two spatial and temporal depthwise convolutions for making our network more lightweight and efficient. By using the proposed temporal modeling method (T-OSA), and the efficient factorized component (D(2+1)D), we construct two types of VoV3D networks, VoV3D-M and VoV3D-L. Thanks to its efficiency and effectiveness of temporal modeling, VoV3D-L has 6x fewer model parameters and 16x less computation, surpassing a state-of-the-art temporal modeling method on both Something-Something and Kinetics-400. Furthermore, VoV3D shows better temporal modeling ability than a state-of-the-art efficient 3D architecture, X3D having comparable model capacity. We hope that VoV3D can serve as a baseline for efficient video classification.