 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton-based Action Recognition of People Handling Objects
Paper and Code
Jan 21, 2019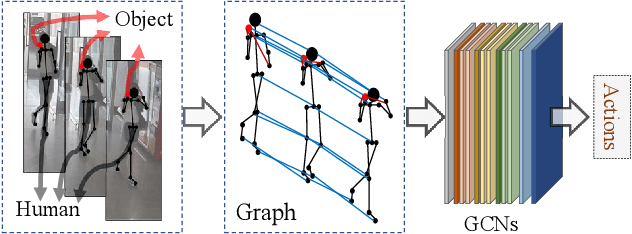


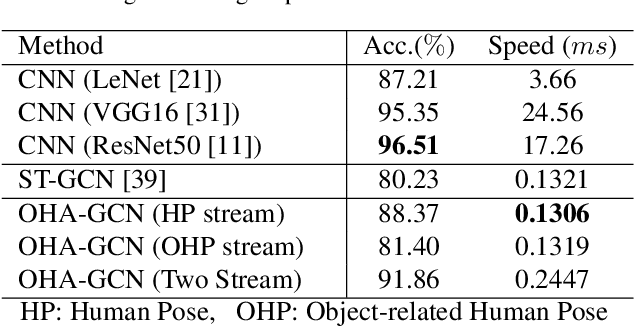
In visual surveillance systems, it is necessary to recognize the behavior of people handling objects such as a phone, a cup, or a plastic bag. In this paper, to address this problem, we propose a new framework for recognizing object-related human actions by graph convolutional networks using human and object poses. In this framework, we construct skeletal graphs of reliable human poses by selectively sampling the informative frames in a video, which include human joints with high confidence scores obtained in pose estimation. The skeletal graphs generated from the sampled frames represent human poses related to the object position in both the spatial and temporal domains, and these graphs are used as inputs to the graph convolutional networks. Through experiments over an open benchmark and our own data sets, we verify the validity of our framework in that our method outperforms the state-of-the-art method for skeleton-based action recognition.