 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomizing Segmentation Foundation Model via Prompt Learning for Instance Segmentation
Mar 14, 2024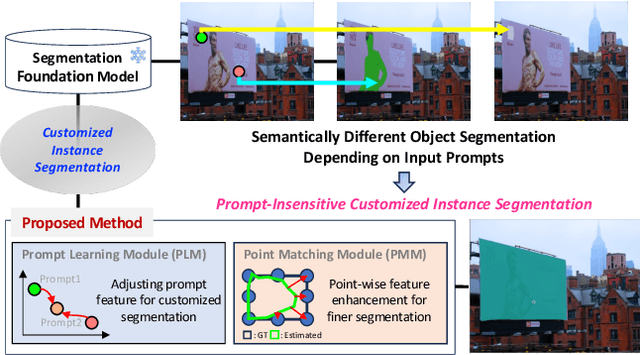


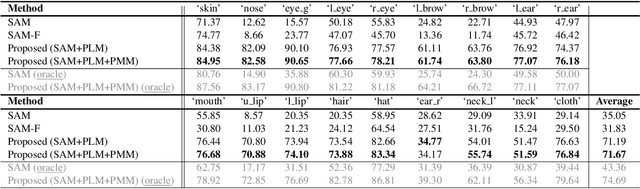
Recently, foundation models trained on massive datasets to adapt to a wide range of domains have attracted considerable attention and are actively being explored within the computer vision community. Among these, the Segment Anything Model (SAM) stands out for its remarkable progress in generalizability and flexibility for image segmentation tasks, achieved through prompt-based object mask generation. However, despite its strength, SAM faces two key limitations when applied to customized instance segmentation that segments specific objects or those in unique environments not typically present in the training data: 1) the ambiguity inherent in input prompts and 2) the necessity for extensive additional training to achieve optimal segmentation. To address these challenges, we propose a novel method, customized instance segmentation via prompt learning tailored to SAM. Our method involves a prompt learning module (PLM), which adjusts input prompts into the embedding space to better align with user intentions, thereby enabling more efficient training. Furthermore, we introduce a point matching module (PMM) to enhance the feature representation for finer segmentation by ensuring detailed alignment with ground truth boundaries. Experimental results on various customized instance segmentation scenarios demonstrate the effectiveness of the proposed method.
Adversarial Training with Stochastic Weight Average
Sep 21, 2020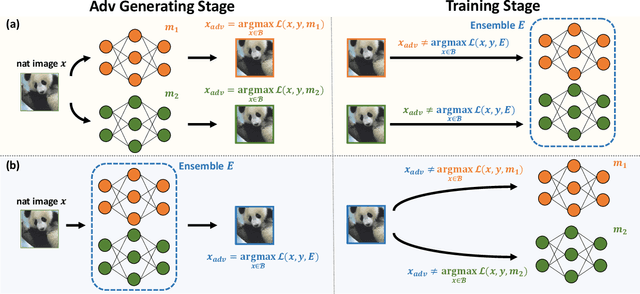
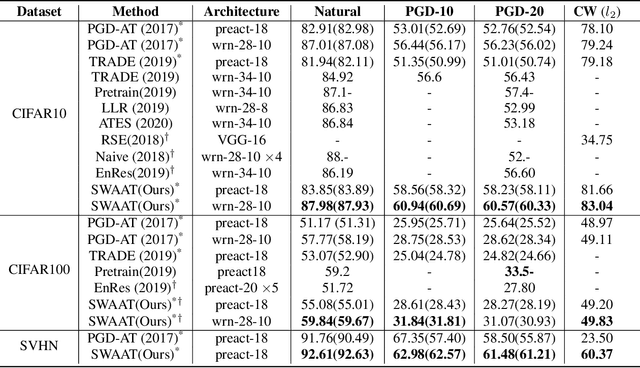
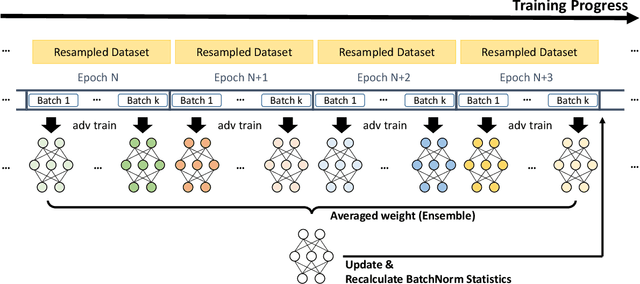

Adversarial training deep neural networks often experience serious overfitting problem. Recently, it is explained that the overfitting happens because the sample complexity of training data is insufficient to generalize robustness. In traditional machine learning, one way to relieve overfitting from the lack of data is to use ensemble methods. However, adversarial training multiple networks is extremely expensive. Moreover, we found that there is a dilemma on choosing target model to generate adversarial examples. Optimizing attack to the members of ensemble will be suboptimal attack to the ensemble and incurs covariate shift, while attack to ensemble will weaken the members and lose the benefit from ensembling. In this paper, we propose adversarial training with Stochastic weight average (SWA); while performing adversarial training, we aggregate the temporal weight states in the trajectory of training. By adopting SWA, the benefit of ensemble can be gained without tremendous computational increment and without facing the dilemma. Moreover, we further improved SWA to be adequate to adversarial training. The empirical results on CIFAR-10, CIFAR-100 and SVHN show that our method can improve the robustness of models.
An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
Apr 22, 2019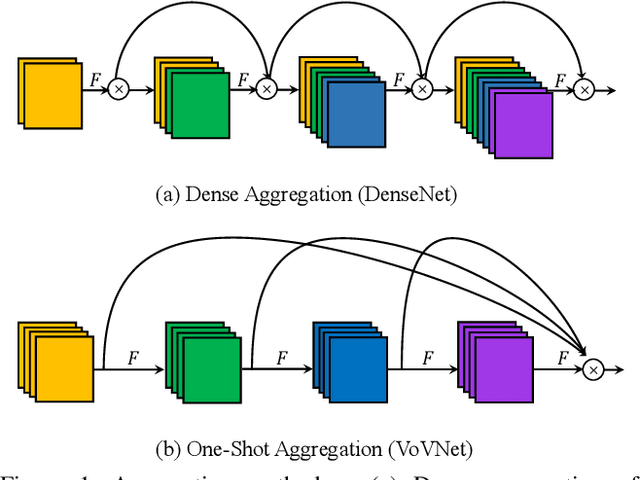
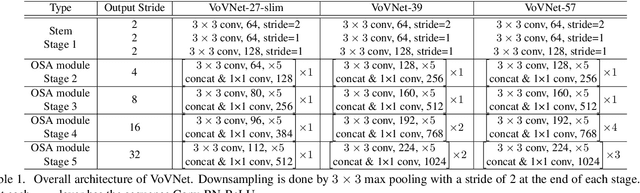
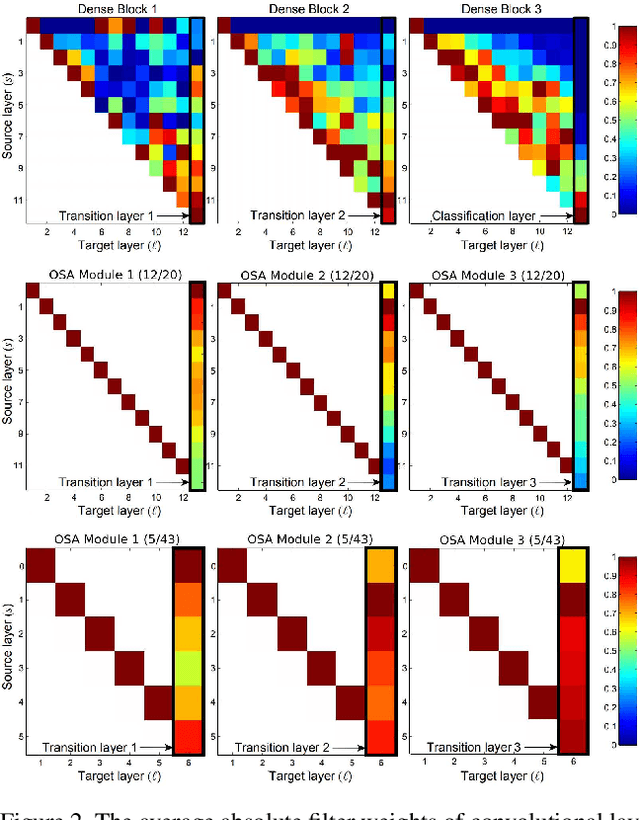
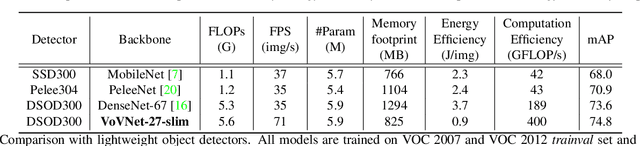
As DenseNet conserves intermediate features with diverse receptive fields by aggregating them with dense connection, it shows good performance on the object detection task. Although feature reuse enables DenseNet to produce strong features with a small number of model parameters and FLOPs, the detector with DenseNet backbone shows rather slow speed and low energy efficiency. We find the linearly increasing input channel by dense connection leads to heavy memory access cost, which causes computation overhead and more energy consumption. To solve the inefficiency of DenseNet, we propose an energy and computation efficient architecture called VoVNet comprised of One-Shot Aggregation (OSA). The OSA not only adopts the strength of DenseNet that represents diversified features with multi receptive fields but also overcomes the inefficiency of dense connection by aggregating all features only once in the last feature maps. To validate the effectiveness of VoVNet as a backbone network, we design both lightweight and large-scale VoVNet and apply them to one-stage and two-stage object detectors. Our VoVNet based detectors outperform DenseNet based ones with 2x faster speed and the energy consumptions are reduced by 1.6x - 4.1x. In addition to DenseNet, VoVNet also outperforms widely used ResNet backbone with faster speed and better energy efficiency. In particular, the small object detection performance has been significantly improved over DenseNet and ResNet.
Rank of Experts: Detection Network Ensemble
Dec 01, 2017
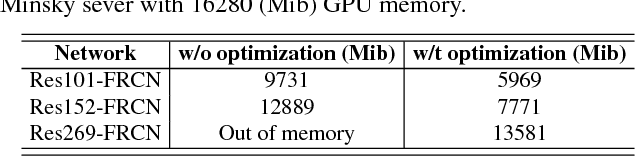
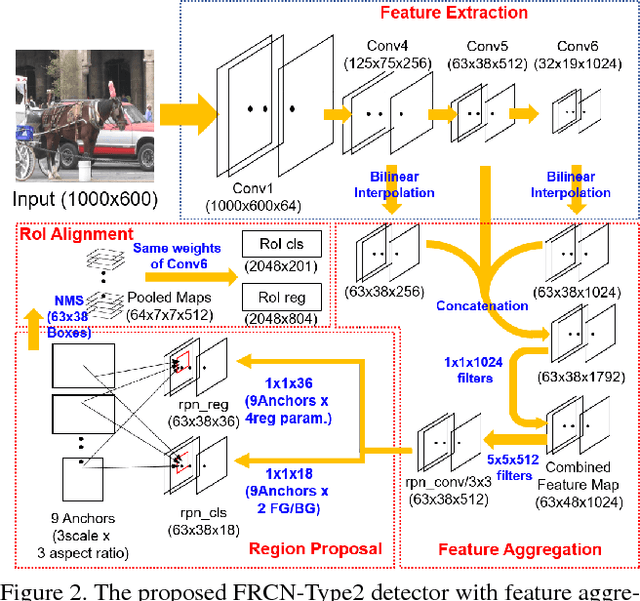
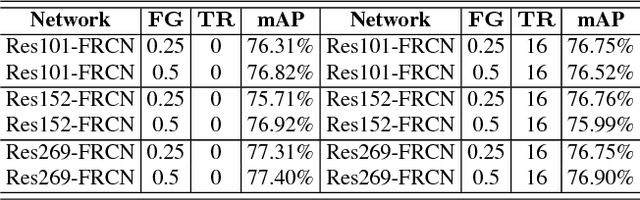
The recent advances of convolutional detectors show impressive performance improvement for large scale object detection. However, in general, the detection performance usually decreases as the object classes to be detected increases, and it is a practically challenging problem to train a dominant model for all classes due to the limitations of detection models and datasets. In most cases, therefore, there are distinct performance differences of the modern convolutional detectors for each object class detection. In this paper, in order to build an ensemble detector for large scale object detection, we present a conceptually simple but very effective class-wise ensemble detection which is named as Rank of Experts. We first decompose an intractable problem of finding the best detections for all object classes into small subproblems of finding the best ones for each object class. We then solve the detection problem by ranking detectors in order of the average precision rate for each class, and then aggregate the responses of the top ranked detectors (i.e. experts) for class-wise ensemble detection. The main benefit of our method is easy to implement and does not require any joint training of experts for ensemble. Based on the proposed Rank of Experts, we won the 2nd place in the ILSVRC 2017 object detection competition.