 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeltaSHAP: Explaining Prediction Evolutions in Online Patient Monitoring with Shapley Values
Jul 03, 2025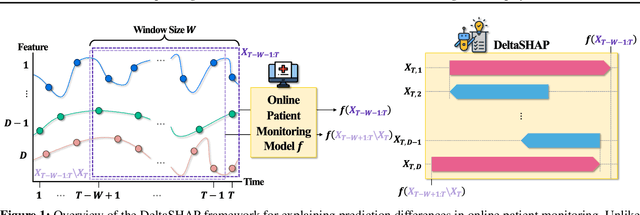
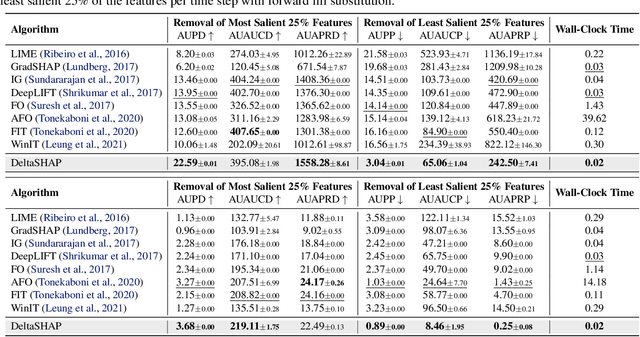
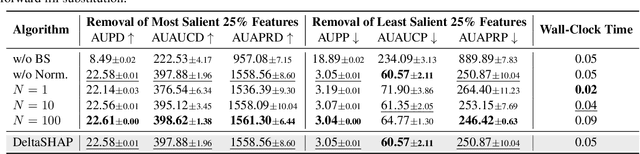
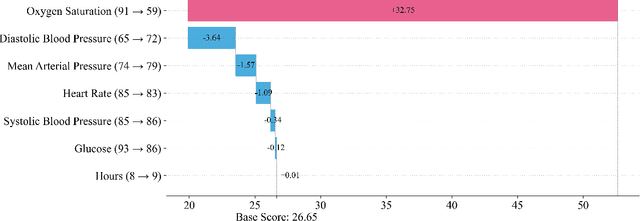
This study proposes DeltaSHAP, a novel explainable artificial intelligence (XAI) algorithm specifically designed for online patient monitoring systems. In clinical environments, discovering the causes driving patient risk evolution is critical for timely intervention, yet existing XAI methods fail to address the unique requirements of clinical time series explanation tasks. To this end, DeltaSHAP addresses three key clinical needs: explaining the changes in the consecutive predictions rather than isolated prediction scores, providing both magnitude and direction of feature attributions, and delivering these insights in real time. By adapting Shapley values to temporal settings, our approach accurately captures feature coalition effects. It further attributes prediction changes using only the actually observed feature combinations, making it efficient and practical for time-sensitive clinical applications. We also introduce new evaluation metrics to evaluate the faithfulness of the attributions for online time series, and demonstrate through experiments on online patient monitoring tasks that DeltaSHAP outperforms state-of-the-art XAI methods in both explanation quality as 62% and computational efficiency as 33% time reduction on the MIMIC-III decompensation benchmark. We release our code at https://github.com/AITRICS/DeltaSHAP.
Compact and De-biased Negative Instance Embedding for Multi-Instance Learning on Whole-Slide Image Classification
Feb 16, 2024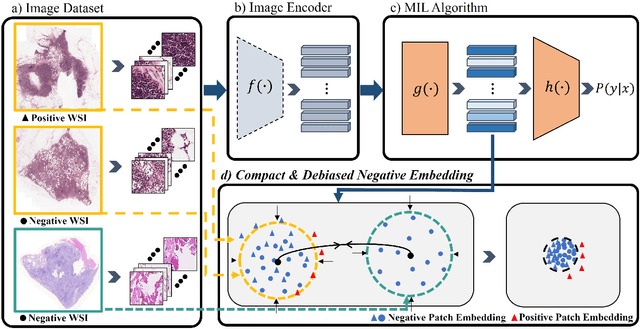
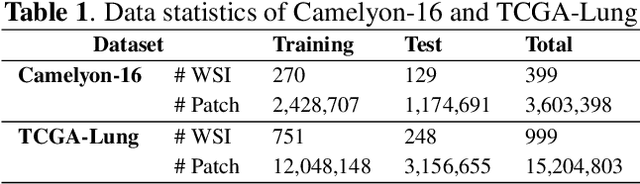
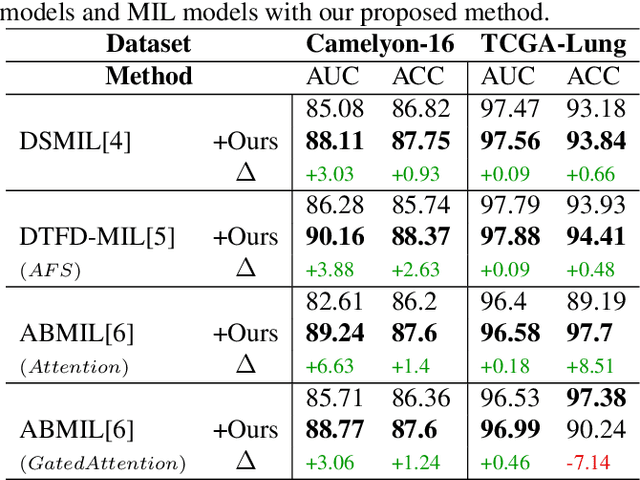
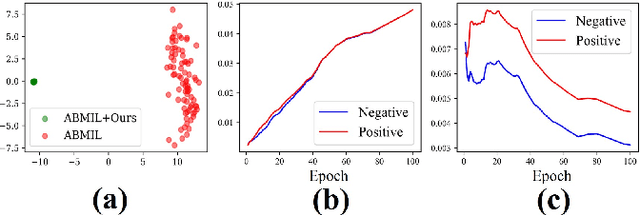
Whole-slide image (WSI) classification is a challenging task because 1) patches from WSI lack annotation, and 2) WSI possesses unnecessary variability, e.g., stain protocol. Recently, Multiple-Instance Learning (MIL) has made significant progress, allowing for classification based on slide-level, rather than patch-level, annotations. However, existing MIL methods ignore that all patches from normal slides are normal. Using this free annotation, we introduce a semi-supervision signal to de-bias the inter-slide variability and to capture the common factors of variation within normal patches. Because our method is orthogonal to the MIL algorithm, we evaluate our method on top of the recently proposed MIL algorithms and also compare the performance with other semi-supervised approaches. We evaluate our method on two public WSI datasets including Camelyon-16 and TCGA lung cancer and demonstrate that our approach significantly improves the predictive performance of existing MIL algorithms and outperforms other semi-supervised algorithms. We release our code at https://github.com/AITRICS/pathology_mil.
Learning Missing Modal Electronic Health Records with Unified Multi-modal Data Embedding and Modality-Aware Attention
May 04, 2023Electronic Health Record (EHR) provides abundant information through various modalities. However, learning multi-modal EHR is currently facing two major challenges, namely, 1) data embedding and 2) cases with missing modality. A lack of shared embedding function across modalities can discard the temporal relationship between different EHR modalities. On the other hand, most EHR studies are limited to relying only on EHR Times-series, and therefore, missing modality in EHR has not been well-explored. Therefore, in this study, we introduce a Unified Multi-modal Set Embedding (UMSE) and Modality-Aware Attention (MAA) with Skip Bottleneck (SB). UMSE treats all EHR modalities without a separate imputation module or error-prone carry-forward, whereas MAA with SB learns missing modal EHR with effective modality-aware attention. Our model outperforms other baseline models in mortality, vasopressor need, and intubation need prediction with the MIMIC-IV dataset.
Self-supervised predictive coding and multimodal fusion advance patient deterioration prediction in fine-grained time resolution
Oct 29, 2022In the Emergency Department (ED), accurate prediction of critical events using Electronic Health Records (EHR) allows timely intervention and effective resource allocation. Though many studies have suggested automatic prediction methods, their coarse-grained time resolutions limit their practical usage. Therefore, in this study, we propose an hourly prediction method of critical events in ED, i.e., mortality and vasopressor need. Through extensive experiments, we show that both 1) bi-modal fusion between EHR text and time-series data and 2) self-supervised predictive regularization using L2 loss between normalized context vector and EHR future time-series data improve predictive performance, especially the far-future prediction. Our uni-modal/bi-modal/bi-modal self-supervision scored 0.846/0.877/0.897 (0.824/0.855/0.886) and 0.817/0.820/0.858 (0.807/0.81/0.855) with mortality (far-future mortality) and with vasopressor need (far-future vasopressor need) prediction data in AUROC, respectively.
Self-Knowledge Distillation in Natural Language Processing
Aug 02, 2019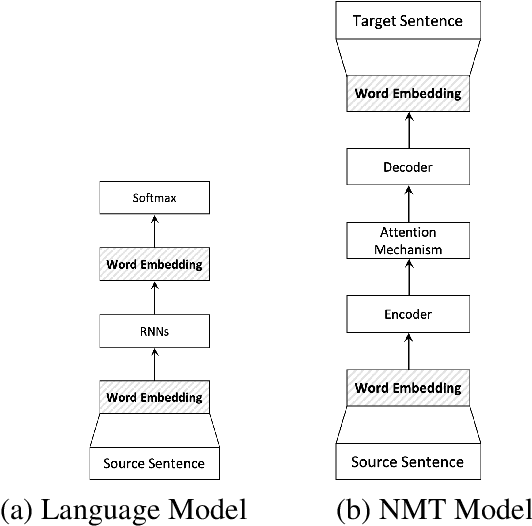

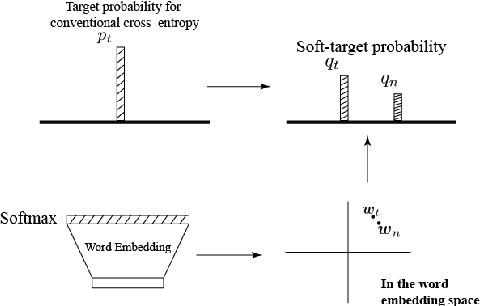
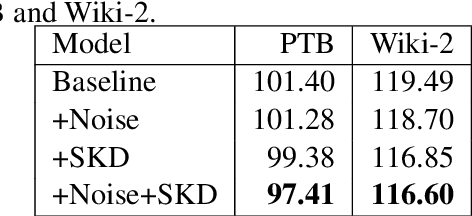
Since deep learning became a key player in natural language processing (NLP), many deep learning models have been showing remarkable performances in a variety of NLP tasks, and in some cases, they are even outperforming humans. Such high performance can be explained by efficient knowledge representation of deep learning models. While many methods have been proposed to learn more efficient representation, knowledge distillation from pretrained deep networks suggest that we can use more information from the soft target probability to train other neural networks. In this paper, we propose a new knowledge distillation method self-knowledge distillation, based on the soft target probabilities of the training model itself, where multimode information is distilled from the word embedding space right below the softmax layer. Due to the time complexity, our method approximates the soft target probabilities. In experiments, we applied the proposed method to two different and fundamental NLP tasks: language model and neural machine translation. The experiment results show that our proposed method improves performance on the tasks.
Disentangling Latent Factors with Whitening
Nov 08, 2018
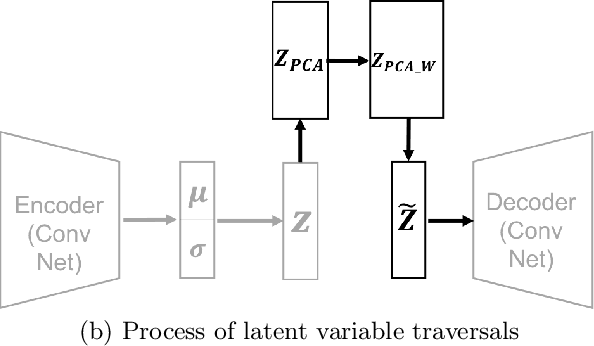
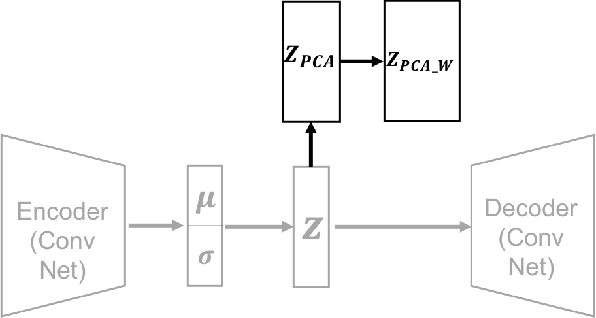

After the success of deep generative models in image generation tasks, learning disentangled latent variable of data has become a major part of deep learning research. Many models have been proposed to learn an interpretable and factorized representation of latent variable by modifying their objective function or model architecture. While disentangling the latent variable, some models show lower quality of reconstructed images and others increase the model complexity which is hard to train. In this paper, we propose a simple disentangling method with traditional principle component analysis (PCA) which is applied to the latent variables of variational auto-encoder (VAE). Our method can be applied to any generative models. In experiment, we apply our proposed method to simple VAE models and experimental results confirm that our method finds more interpretable factors from the latent space while keeping the reconstruction error the same.
Gradient Acceleration in Activation Functions
Jun 26, 2018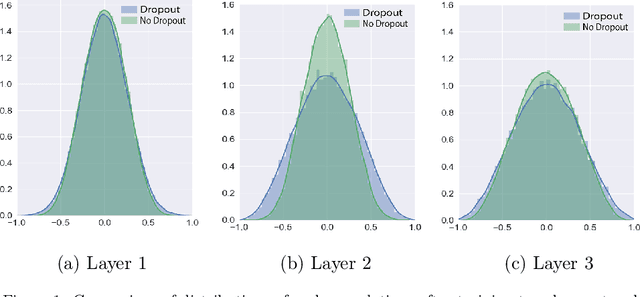

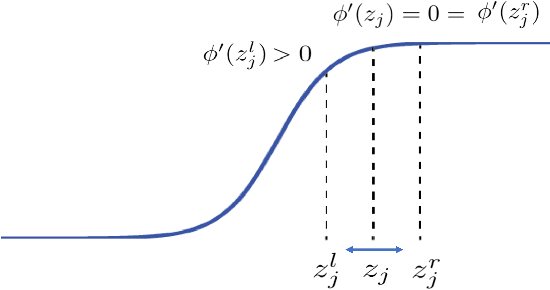
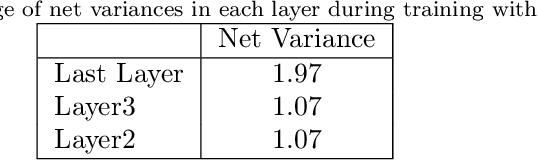
Dropout has been one of standard approaches to train deep neural networks, and it is known to regularize large models to avoid overfitting. The effect of dropout has been explained by avoiding co-adaptation. In this paper, however, we propose a new explanation of why dropout works and propose a new technique to design better activation functions. First, we show that dropout is an optimization technique to push the input towards the saturation area of nonlinear activation function by accelerating gradient information flowing even in the saturation area in backpropagation. Based on this explanation, we propose a new technique for activation functions, gradient acceleration in activation function (GAAF), that accelerates gradients to flow even in the saturation area. Then, input to the activation function can climb onto the saturation area which makes the network more robust because the model converges on a flat region. Experiment results support our explanation of dropout and confirm that the proposed GAAF technique improves performances with expected properties.