 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Acceleration in Activation Functions
Paper and Code
Jun 26, 2018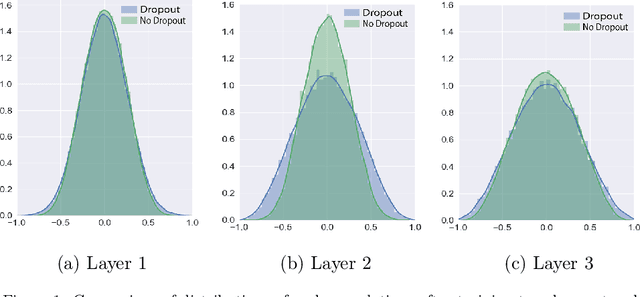

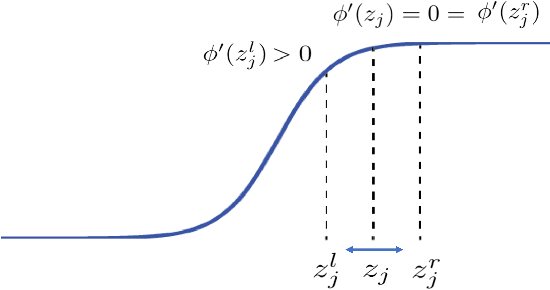
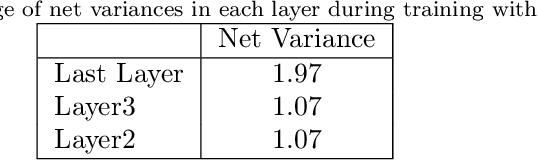
Dropout has been one of standard approaches to train deep neural networks, and it is known to regularize large models to avoid overfitting. The effect of dropout has been explained by avoiding co-adaptation. In this paper, however, we propose a new explanation of why dropout works and propose a new technique to design better activation functions. First, we show that dropout is an optimization technique to push the input towards the saturation area of nonlinear activation function by accelerating gradient information flowing even in the saturation area in backpropagation. Based on this explanation, we propose a new technique for activation functions, gradient acceleration in activation function (GAAF), that accelerates gradients to flow even in the saturation area. Then, input to the activation function can climb onto the saturation area which makes the network more robust because the model converges on a flat region. Experiment results support our explanation of dropout and confirm that the proposed GAAF technique improves performances with expected properties.