 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Latent Factors with Whitening
Paper and Code
Nov 08, 2018
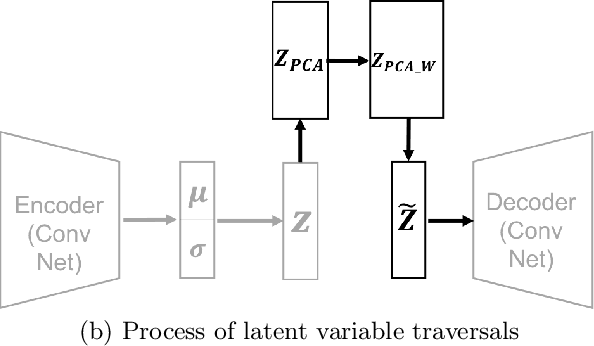
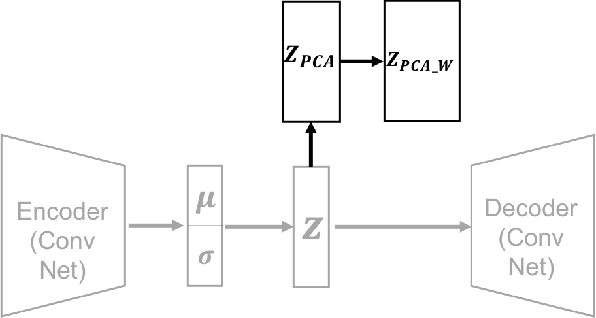

After the success of deep generative models in image generation tasks, learning disentangled latent variable of data has become a major part of deep learning research. Many models have been proposed to learn an interpretable and factorized representation of latent variable by modifying their objective function or model architecture. While disentangling the latent variable, some models show lower quality of reconstructed images and others increase the model complexity which is hard to train. In this paper, we propose a simple disentangling method with traditional principle component analysis (PCA) which is applied to the latent variables of variational auto-encoder (VAE). Our method can be applied to any generative models. In experiment, we apply our proposed method to simple VAE models and experimental results confirm that our method finds more interpretable factors from the latent space while keeping the reconstruction error the same.