 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRA: Adaptive Interest-aware Representation and Alignment for Personalized Multi-interest Retrieval
Apr 24, 2025

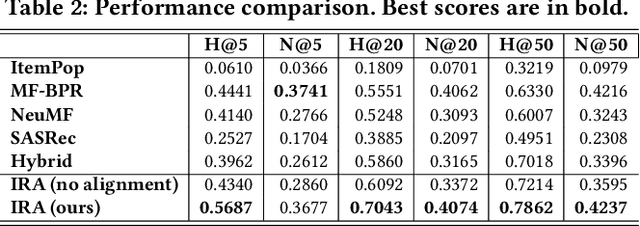
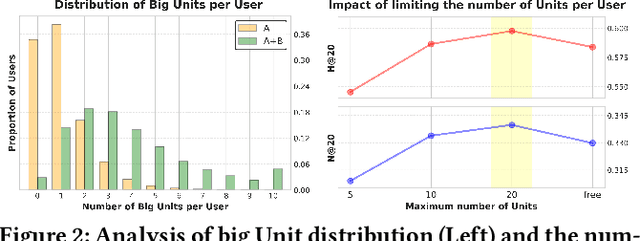
Online community platforms require dynamic personalized retrieval and recommendation that can continuously adapt to evolving user interests and new documents. However, optimizing models to handle such changes in real-time remains a major challenge in large-scale industrial settings. To address this, we propose the Interest-aware Representation and Alignment (IRA) framework, an efficient and scalable approach that dynamically adapts to new interactions through a cumulative structure. IRA leverages two key mechanisms: (1) Interest Units that capture diverse user interests as contextual texts, while reinforcing or fading over time through cumulative updates, and (2) a retrieval process that measures the relevance between Interest Units and documents based solely on semantic relationships, eliminating dependence on click signals to mitigate temporal biases. By integrating cumulative Interest Unit updates with the retrieval process, IRA continuously adapts to evolving user preferences, ensuring robust and fine-grained personalization without being constrained by past training distributions. We validate the effectiveness of IRA through extensive experiments on real-world datasets, including its deployment in the Home Section of NAVER's CAFE, South Korea's leading community platform.
MvFS: Multi-view Feature Selection for Recommender System
Sep 06, 2023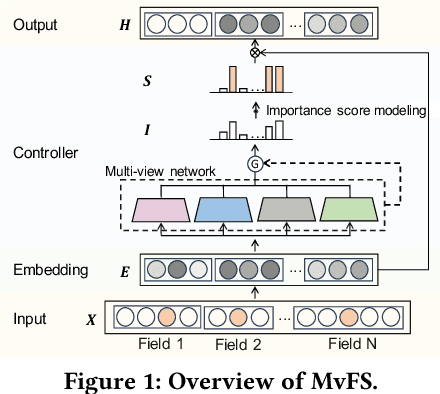
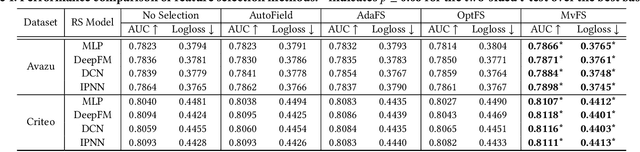
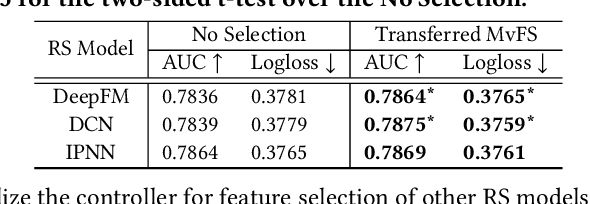
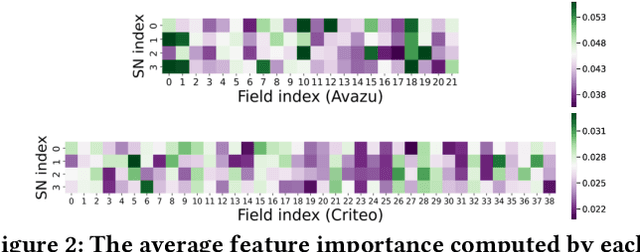
Feature selection, which is a technique to select key features in recommender systems, has received increasing research attention. Recently, Adaptive Feature Selection (AdaFS) has shown remarkable performance by adaptively selecting features for each data instance, considering that the importance of a given feature field can vary significantly across data. However, this method still has limitations in that its selection process could be easily biased to major features that frequently occur. To address these problems, we propose Multi-view Feature Selection (MvFS), which selects informative features for each instance more effectively. Most importantly, MvFS employs a multi-view network consisting of multiple sub-networks, each of which learns to measure the feature importance of a part of data with different feature patterns. By doing so, MvFS mitigates the bias problem towards dominant patterns and promotes a more balanced feature selection process. Moreover, MvFS adopts an effective importance score modeling strategy which is applied independently to each field without incurring dependency among features. Experimental results on real-world datasets demonstrate the effectiveness of MvFS compared to state-of-the-art baselines.
Augment & Valuate : A Data Enhancement Pipeline for Data-Centric AI
Dec 07, 2021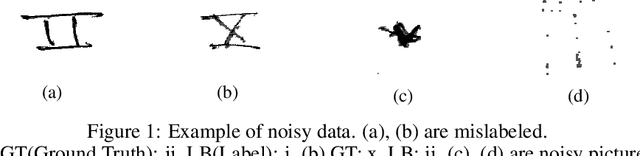



Data scarcity and noise are important issues in industrial applications of machine learning. However, it is often challenging to devise a scalable and generalized approach to address the fundamental distributional and semantic properties of dataset with black box models. For this reason, data-centric approaches are crucial for the automation of machine learning operation pipeline. In order to serve as the basis for this automation, we suggest a domain-agnostic pipeline for refining the quality of data in image classification problems. This pipeline contains data valuation, cleansing, and augmentation. With an appropriate combination of these methods, we could achieve 84.711% test accuracy (ranked #6, Honorable Mention in the Most Innovative) in the Data-Centric AI competition only with the provided dataset.
Dual Correction Strategy for Ranking Distillation in Top-N Recommender System
Sep 08, 2021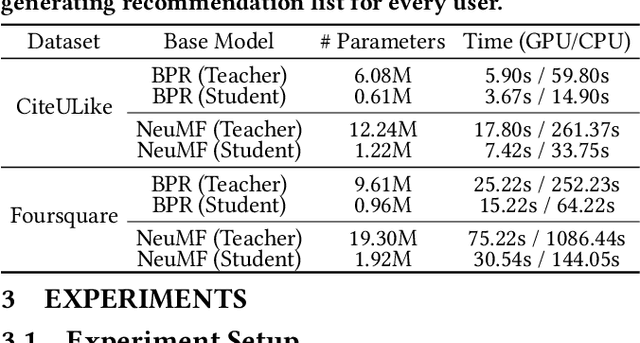
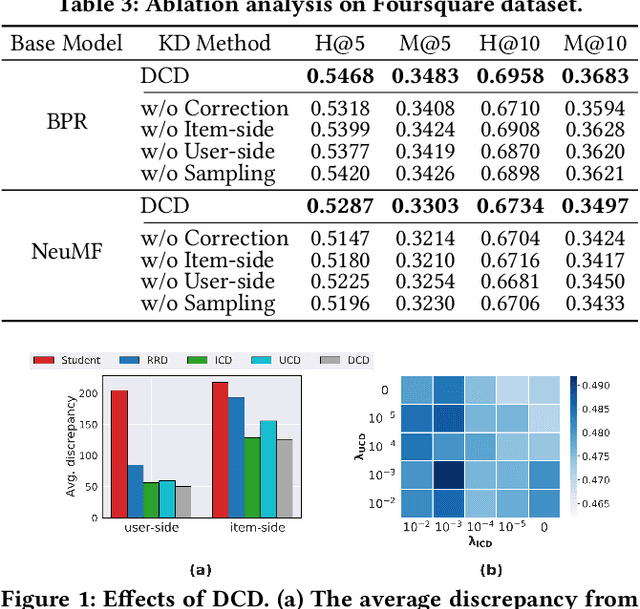
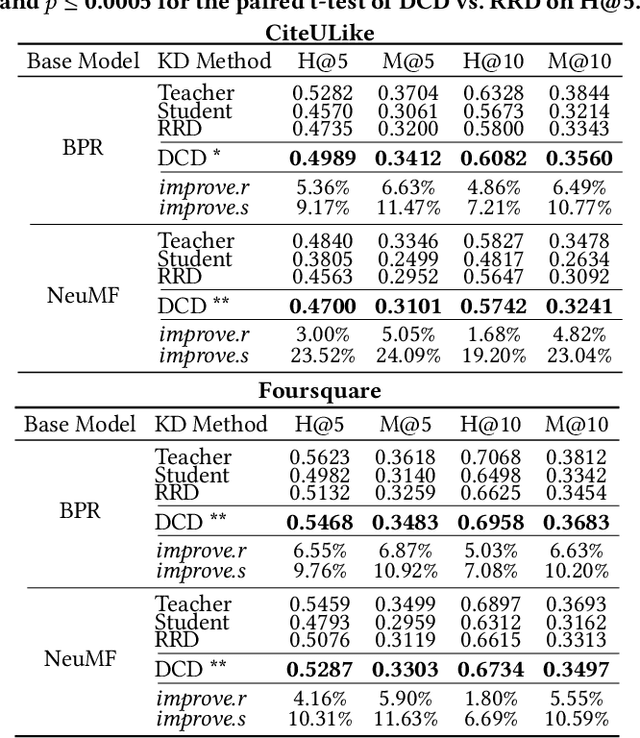
Knowledge Distillation (KD), which transfers the knowledge of a well-trained large model (teacher) to a small model (student), has become an important area of research for practical deployment of recommender systems. Recently, Relaxed Ranking Distillation (RRD) has shown that distilling the ranking information in the recommendation list significantly improves the performance. However, the method still has limitations in that 1) it does not fully utilize the prediction errors of the student model, which makes the training not fully efficient, and 2) it only distills the user-side ranking information, which provides an insufficient view under the sparse implicit feedback. This paper presents Dual Correction strategy for Distillation (DCD), which transfers the ranking information from the teacher model to the student model in a more efficient manner. Most importantly, DCD uses the discrepancy between the teacher model and the student model predictions to decide which knowledge to be distilled. By doing so, DCD essentially provides the learning guidance tailored to "correcting" what the student model has failed to accurately predict. This process is applied for transferring the ranking information from the user-side as well as the item-side to address sparse implicit user feedback. Our experiments show that the proposed method outperforms the state-of-the-art baselines, and ablation studies validate the effectiveness of each component.