 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRA: Adaptive Interest-aware Representation and Alignment for Personalized Multi-interest Retrieval
Apr 24, 2025

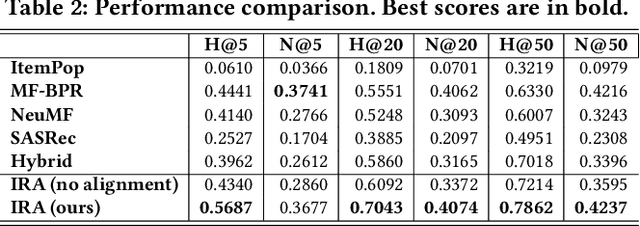
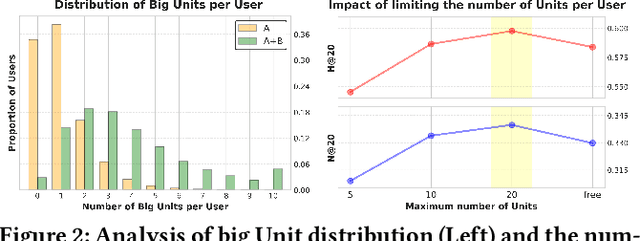
Online community platforms require dynamic personalized retrieval and recommendation that can continuously adapt to evolving user interests and new documents. However, optimizing models to handle such changes in real-time remains a major challenge in large-scale industrial settings. To address this, we propose the Interest-aware Representation and Alignment (IRA) framework, an efficient and scalable approach that dynamically adapts to new interactions through a cumulative structure. IRA leverages two key mechanisms: (1) Interest Units that capture diverse user interests as contextual texts, while reinforcing or fading over time through cumulative updates, and (2) a retrieval process that measures the relevance between Interest Units and documents based solely on semantic relationships, eliminating dependence on click signals to mitigate temporal biases. By integrating cumulative Interest Unit updates with the retrieval process, IRA continuously adapts to evolving user preferences, ensuring robust and fine-grained personalization without being constrained by past training distributions. We validate the effectiveness of IRA through extensive experiments on real-world datasets, including its deployment in the Home Section of NAVER's CAFE, South Korea's leading community platform.
Towards Proper Contrastive Self-supervised Learning Strategies For Music Audio Representation
Jul 10, 2022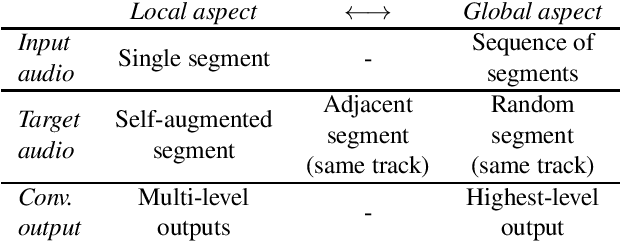

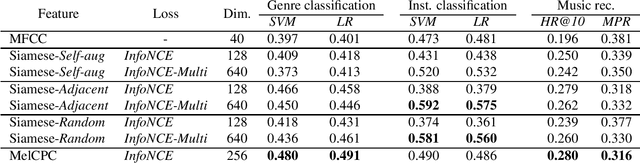
The common research goal of self-supervised learning is to extract a general representation which an arbitrary downstream task would benefit from. In this work, we investigate music audio representation learned from different contrastive self-supervised learning schemes and empirically evaluate the embedded vectors on various music information retrieval (MIR) tasks where different levels of the music perception are concerned. We analyze the results to discuss the proper direction of contrastive learning strategies for different MIR tasks. We show that these representations convey a comprehensive information about the auditory characteristics of music in general, although each of the self-supervision strategies has its own effectiveness in certain aspect of information.
Zero-shot Learning for Audio-based Music Classification and Tagging
Jul 05, 2019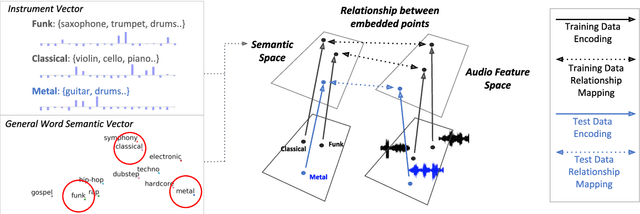
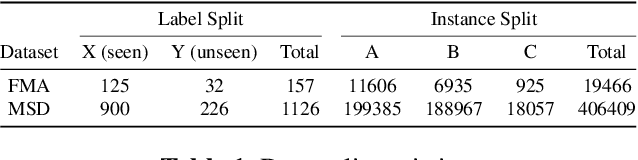
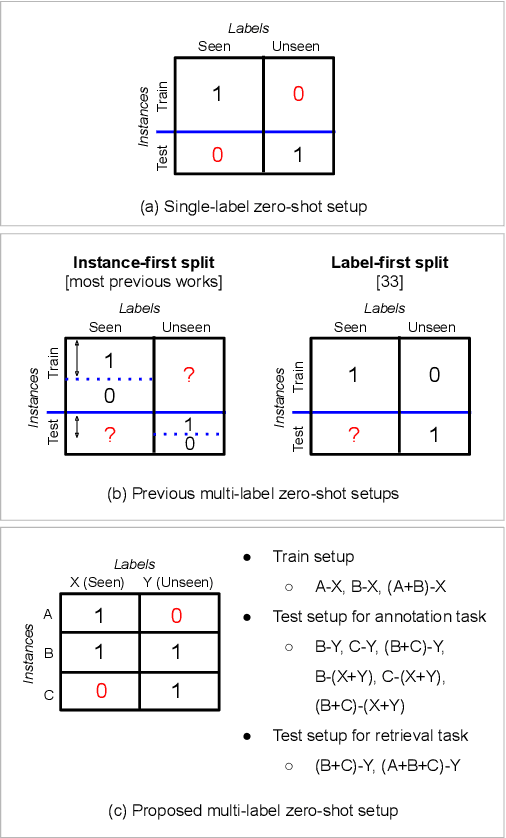
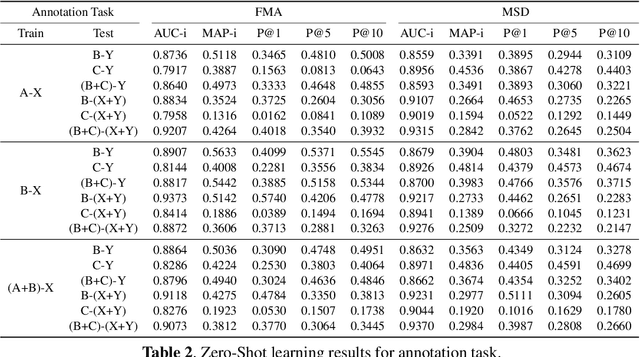
Audio-based music classification and tagging is typically based on categorical supervised learning with a fixed set of labels. This intrinsically cannot handle unseen labels such as newly added music genres or semantic words that users arbitrarily choose for music retrieval. Zero-shot learning can address this problem by leveraging an additional semantic space of labels where side information about the labels is used to unveil the relationship between each other. In this work, we investigate the zero-shot learning in the music domain and organize two different setups of side information. One is using human-labeled attribute information based on Free Music Archive and OpenMIC-2018 datasets. The other is using general word semantic information based on Million Song Dataset and Last.fm tag annotations. Considering a music track is usually multi-labeled in music classification and tagging datasets, we also propose a data split scheme and associated evaluation settings for the multi-label zero-shot learning. Finally, we report experimental results and discuss the effectiveness and new possibilities of zero-shot learning in the music domain.
Zero-shot Learning and Knowledge Transfer in Music Classification and Tagging
Jun 20, 2019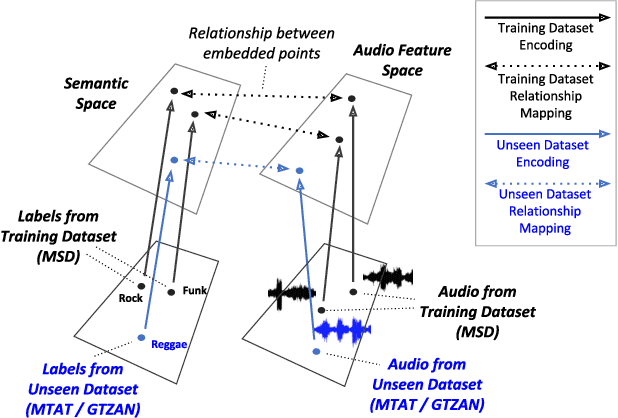
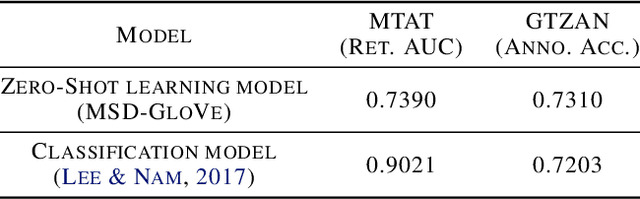
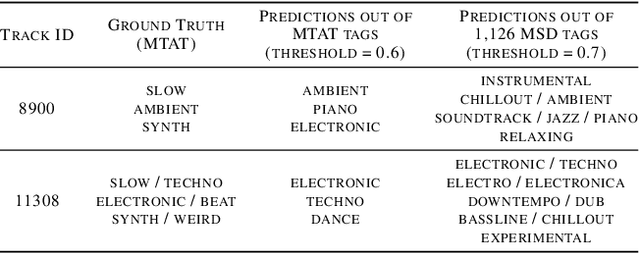

Music classification and tagging is conducted through categorical supervised learning with a fixed set of labels. In principle, this cannot make predictions on unseen labels. Zero-shot learning is an approach to solve the problem by using side information about the semantic labels. We recently investigated this concept of zero-shot learning in music classification and tagging task by projecting both audio and label space on a single semantic space. In this work, we extend the work to verify the generalization ability of zero-shot learning model by conducting knowledge transfer to different music corpora.