 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDE: Temporal Incremental Draft Engine for Self-Improving LLM Inference
Feb 05, 2026Speculative decoding can substantially accelerate LLM inference, but realizing its benefits in practice is challenging due to evolving workloads and system-level constraints. We present TIDE (Temporal Incremental Draft Engine), a serving-engine-native framework that integrates online draft adaptation directly into high-performance LLM inference systems. TIDE reuses target model hidden states generated during inference as training signals, enabling zero-overhead draft adaptation without reloading the target model, and employs adaptive runtime control to activate speculation and training only when beneficial. TIDE exploits heterogeneous clusters by mapping decoupled inference and training to appropriate GPU classes. Across diverse real-world workloads, TIDE achieves up to 1.15x throughput improvement over static speculative decoding while reducing draft training time by 1.67x compared to approaches that recompute training signals.
Expanding Foundational Language Capabilities in Open-Source LLMs through a Korean Case Study
Sep 04, 2025We introduce Llama-3-Motif, a language model consisting of 102 billion parameters, specifically designed to enhance Korean capabilities while retaining strong performance in English. Developed on the Llama 3 architecture, Llama-3-Motif employs advanced training techniques, including LlamaPro and Masked Structure Growth, to effectively scale the model without altering its core Transformer architecture. Using the MoAI platform for efficient training across hyperscale GPU clusters, we optimized Llama-3-Motif using a carefully curated dataset that maintains a balanced ratio of Korean and English data. Llama-3-Motif shows decent performance on Korean-specific benchmarks, outperforming existing models and achieving results comparable to GPT-4.
Robust Estimation in metric spaces: Achieving Exponential Concentration with a Fréchet Median
Apr 19, 2025There is growing interest in developing statistical estimators that achieve exponential concentration around a population target even when the data distribution has heavier than exponential tails. More recent activity has focused on extending such ideas beyond Euclidean spaces to Hilbert spaces and Riemannian manifolds. In this work, we show that such exponential concentration in presence of heavy tails can be achieved over a broader class of parameter spaces called CAT($\kappa$) spaces, a very general metric space equipped with the minimal essential geometric structure for our purpose, while being sufficiently broad to encompass most typical examples encountered in statistics and machine learning. The key technique is to develop and exploit a general concentration bound for the Fr\'echet median in CAT($\kappa$) spaces. We illustrate our theory through a number of examples, and provide empirical support through simulation studies.
Probabilistic U-Net with Kendall Shape Spaces for Geometry-Aware Segmentations of Images
Oct 17, 2024


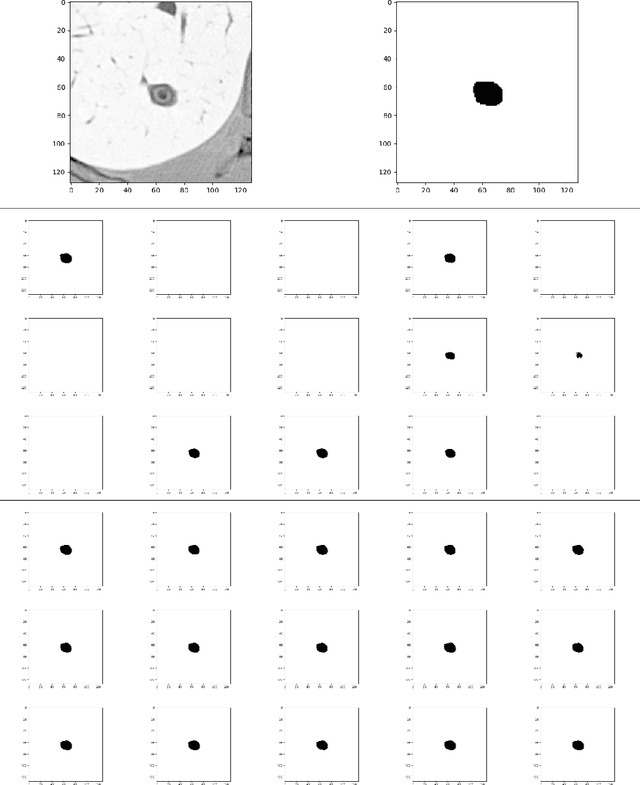
One of the fundamental problems in computer vision is image segmentation, the task of detecting distinct regions or objects in given images. Deep Neural Networks (DNN) have been shown to be very effective in segmenting challenging images, producing convincing segmentations. There is further need for probabilistic DNNs that can reflect the uncertainties from the input images and the models into the computed segmentations, in other words, new DNNs that can generate multiple plausible segmentations and their distributions depending on the input or the model uncertainties. While there are existing probabilistic segmentation models, many of them do not take into account the geometry or shape underlying the segmented regions. In this paper, we propose a probabilistic image segmentation model that can incorporate the geometry of a segmentation. Our proposed model builds on the Probabilistic U-Net of \cite{kohl2018probabilistic} to generate probabilistic segmentations, i.e.\! multiple likely segmentations for an input image. Our model also adopts the Kendall Shape Variational Auto-Encoder of \cite{vadgama2023kendall} to encode a Kendall shape space in the latent variable layers of the prior and posterior networks of the Probabilistic U-Net. Incorporating the shape space in this manner leads to a more robust segmentation with spatially coherent regions, respecting the underlying geometry in the input images.
Minimum norm interpolation by perceptra: Explicit regularization and implicit bias
Nov 10, 2023We investigate how shallow ReLU networks interpolate between known regions. Our analysis shows that empirical risk minimizers converge to a minimum norm interpolant as the number of data points and parameters tends to infinity when a weight decay regularizer is penalized with a coefficient which vanishes at a precise rate as the network width and the number of data points grow. With and without explicit regularization, we numerically study the implicit bias of common optimization algorithms towards known minimum norm interpolants.
Zero-shot Learning for Audio-based Music Classification and Tagging
Jul 05, 2019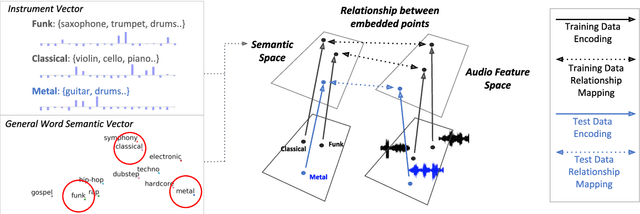
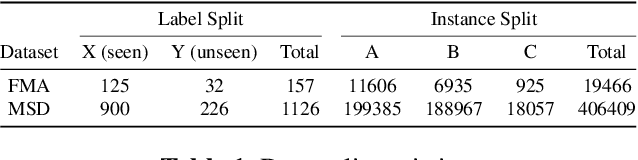
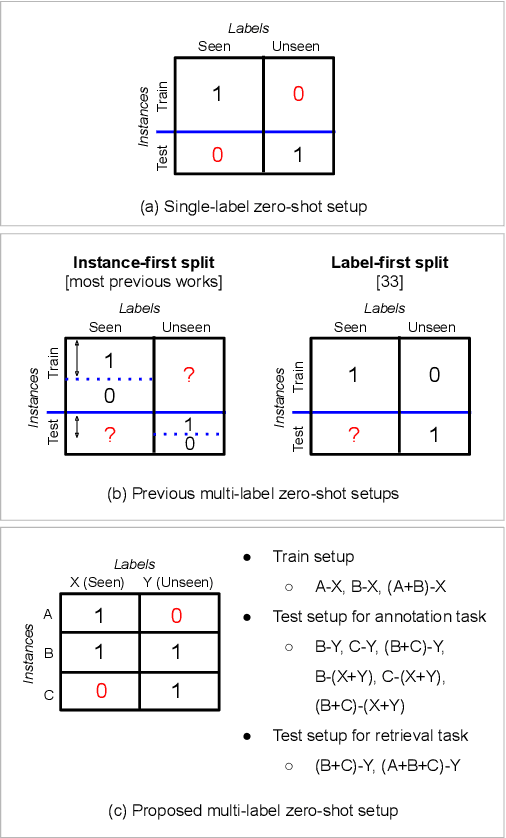
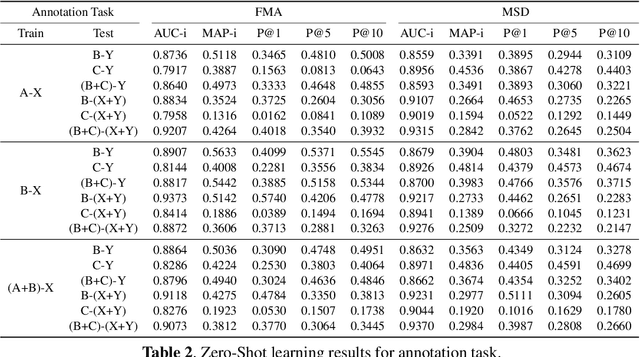
Audio-based music classification and tagging is typically based on categorical supervised learning with a fixed set of labels. This intrinsically cannot handle unseen labels such as newly added music genres or semantic words that users arbitrarily choose for music retrieval. Zero-shot learning can address this problem by leveraging an additional semantic space of labels where side information about the labels is used to unveil the relationship between each other. In this work, we investigate the zero-shot learning in the music domain and organize two different setups of side information. One is using human-labeled attribute information based on Free Music Archive and OpenMIC-2018 datasets. The other is using general word semantic information based on Million Song Dataset and Last.fm tag annotations. Considering a music track is usually multi-labeled in music classification and tagging datasets, we also propose a data split scheme and associated evaluation settings for the multi-label zero-shot learning. Finally, we report experimental results and discuss the effectiveness and new possibilities of zero-shot learning in the music domain.
Zero-shot Learning and Knowledge Transfer in Music Classification and Tagging
Jun 20, 2019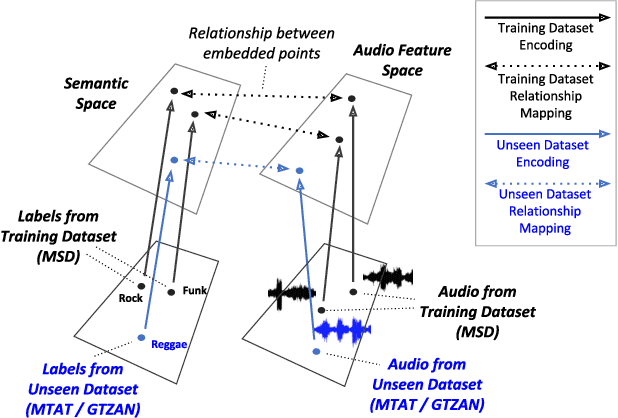
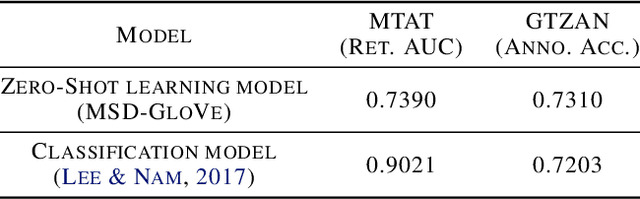
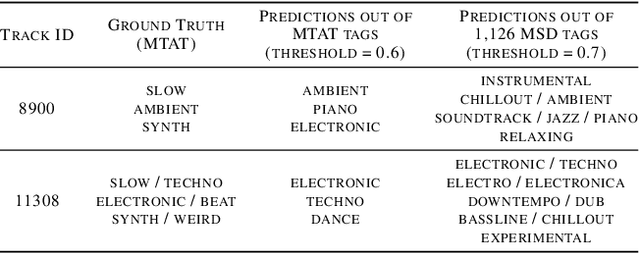

Music classification and tagging is conducted through categorical supervised learning with a fixed set of labels. In principle, this cannot make predictions on unseen labels. Zero-shot learning is an approach to solve the problem by using side information about the semantic labels. We recently investigated this concept of zero-shot learning in music classification and tagging task by projecting both audio and label space on a single semantic space. In this work, we extend the work to verify the generalization ability of zero-shot learning model by conducting knowledge transfer to different music corpora.
Deep Content-User Embedding Model for Music Recommendation
Jul 18, 2018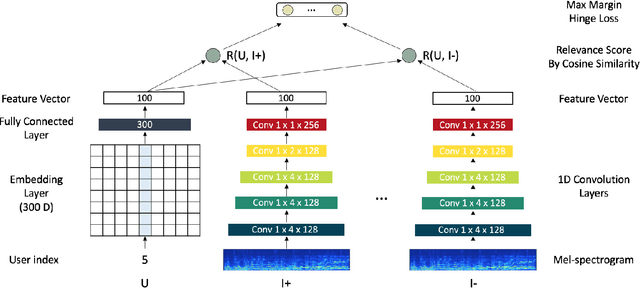


Recently deep learning based recommendation systems have been actively explored to solve the cold-start problem using a hybrid approach. However, the majority of previous studies proposed a hybrid model where collaborative filtering and content-based filtering modules are independently trained. The end-to-end approach that takes different modality data as input and jointly trains the model can provide better optimization but it has not been fully explored yet. In this work, we propose deep content-user embedding model, a simple and intuitive architecture that combines the user-item interaction and music audio content. We evaluate the model on music recommendation and music auto-tagging tasks. The results show that the proposed model significantly outperforms the previous work. We also discuss various directions to improve the proposed model further.
Raw Waveform-based Audio Classification Using Sample-level CNN Architectures
Dec 04, 2017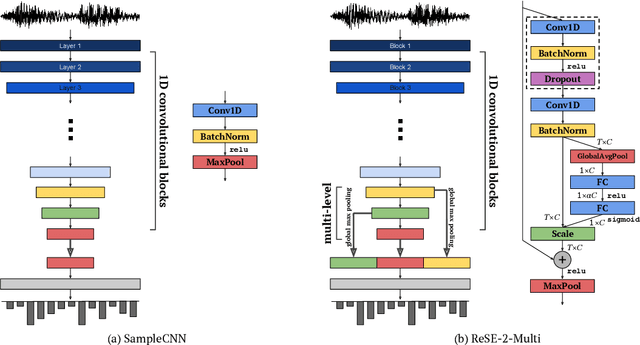
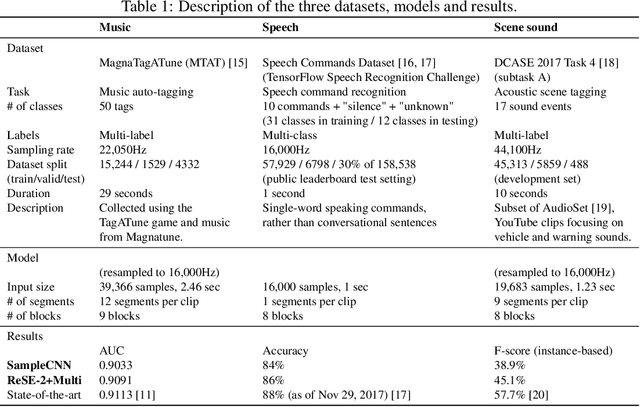
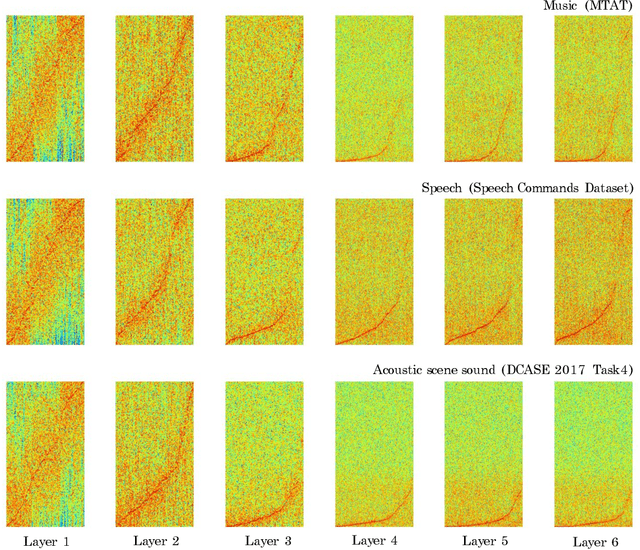
Music, speech, and acoustic scene sound are often handled separately in the audio domain because of their different signal characteristics. However, as the image domain grows rapidly by versatile image classification models, it is necessary to study extensible classification models in the audio domain as well. In this study, we approach this problem using two types of sample-level deep convolutional neural networks that take raw waveforms as input and uses filters with small granularity. One is a basic model that consists of convolution and pooling layers. The other is an improved model that additionally has residual connections, squeeze-and-excitation modules and multi-level concatenation. We show that the sample-level models reach state-of-the-art performance levels for the three different categories of sound. Also, we visualize the filters along layers and compare the characteristics of learned filters.
Sample-level Deep Convolutional Neural Networks for Music Auto-tagging Using Raw Waveforms
May 22, 2017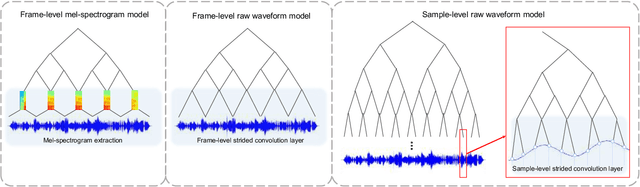
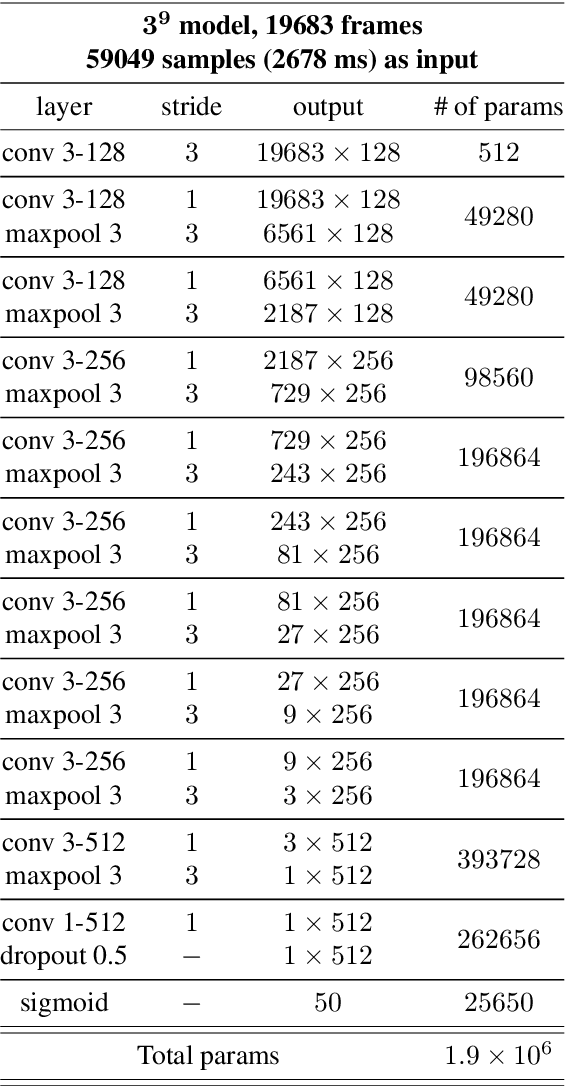

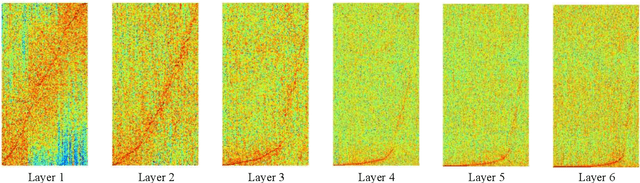
Recently, the end-to-end approach that learns hierarchical representations from raw data using deep convolutional neural networks has been successfully explored in the image, text and speech domains. This approach was applied to musical signals as well but has been not fully explored yet. To this end, we propose sample-level deep convolutional neural networks which learn representations from very small grains of waveforms (e.g. 2 or 3 samples) beyond typical frame-level input representations. Our experiments show how deep architectures with sample-level filters improve the accuracy in music auto-tagging and they provide results comparable to previous state-of-the-art performances for the Magnatagatune dataset and Million Song Dataset. In addition, we visualize filters learned in a sample-level DCNN in each layer to identify hierarchically learned features and show that they are sensitive to log-scaled frequency along layer, such as mel-frequency spectrogram that is widely used in music classification systems.