 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiFiGaze: Improving Eye Tracking Accuracy Using Screen Content Knowledge
Mar 20, 2026We present a new and accurate approach for gaze estimation on consumer computing devices. We take advantage of continued strides in the quality of user-facing cameras found in e.g., smartphones, laptops, and desktops - 4K or greater in high-end devices - such that it is now possible to capture the 2D reflection of a device's screen in the user's eyes. This alone is insufficient for accurate gaze tracking due to the near-infinite variety of screen content. Crucially, however, the device knows what is being displayed on its own screen - in this work, we show this information allows for robust segmentation of the reflection, the location and size of which encodes the user's screen-relative gaze target. We explore several strategies to leverage this useful signal, quantifying performance in a user study. Our best performing model reduces mean tracking error by ~8% compared to a baseline appearance-based model. A supplemental study reveals an additional 10-20% improvement if the gaze-tracking camera is located at the bottom of the device.
All-In-One Metrical And Functional Structure Analysis With Neighborhood Attentions on Demixed Audio
Jul 31, 2023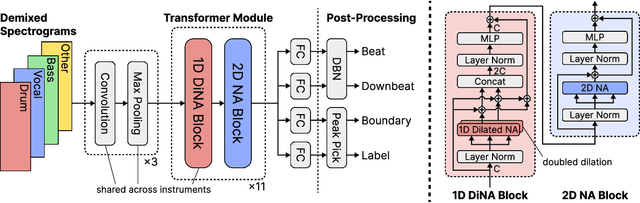
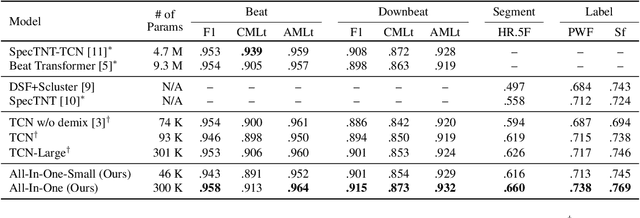
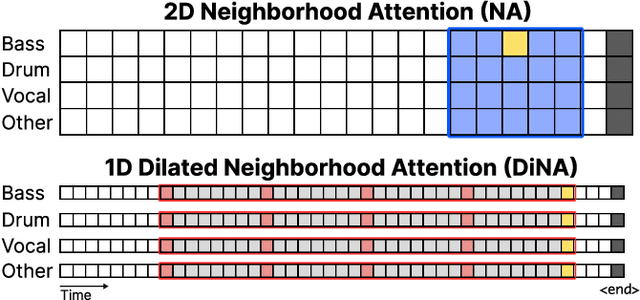
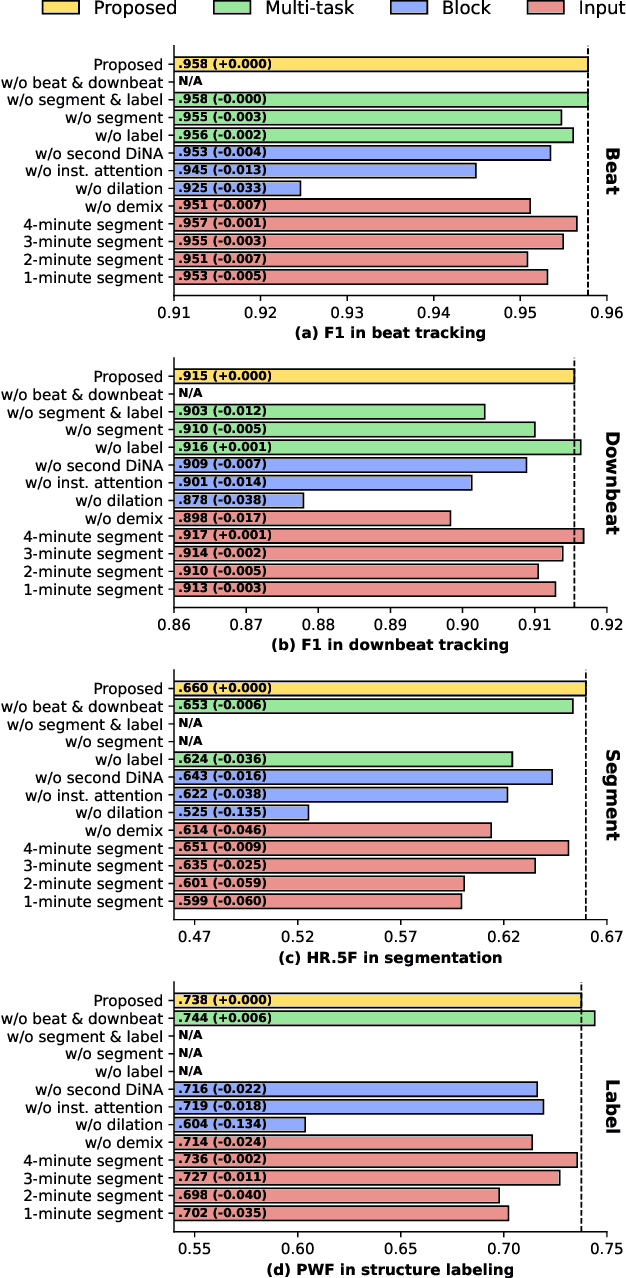
Music is characterized by complex hierarchical structures. Developing a comprehensive model to capture these structures has been a significant challenge in the field of Music Information Retrieval (MIR). Prior research has mainly focused on addressing individual tasks for specific hierarchical levels, rather than providing a unified approach. In this paper, we introduce a versatile, all-in-one model that jointly performs beat and downbeat tracking as well as functional structure segmentation and labeling. The model leverages source-separated spectrograms as inputs and employs dilated neighborhood attentions to capture temporal long-term dependencies, along with non-dilated attentions for local instrumental dependencies. Consequently, the proposed model achieves state-of-the-art performance in all four tasks on the Harmonix Set while maintaining a relatively lower number of parameters compared to recent state-of-the-art models. Furthermore, our ablation study demonstrates that the concurrent learning of beats, downbeats, and segments can lead to enhanced performance, with each task mutually benefiting from the others.
Temporal Feedback Convolutional Recurrent Neural Networks for Keyword Spotting
Oct 30, 2019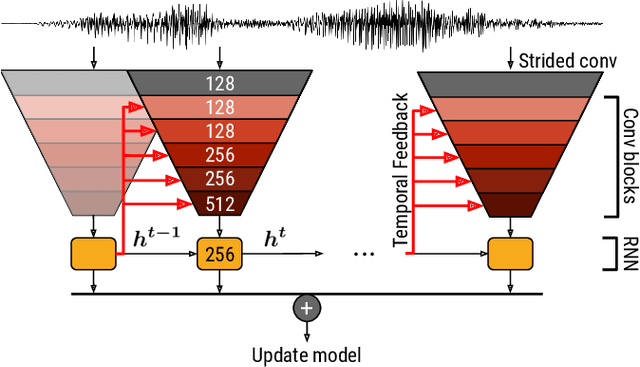
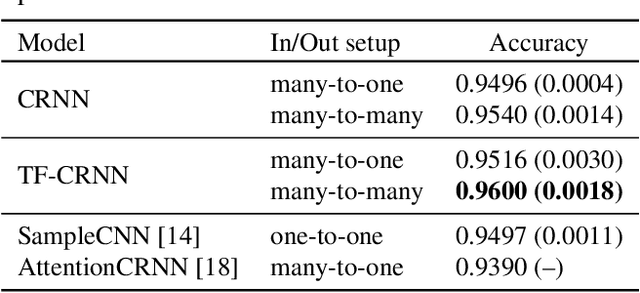
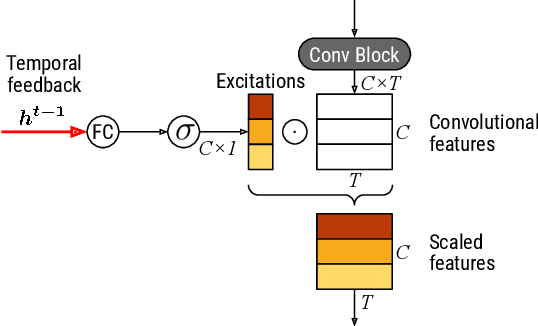
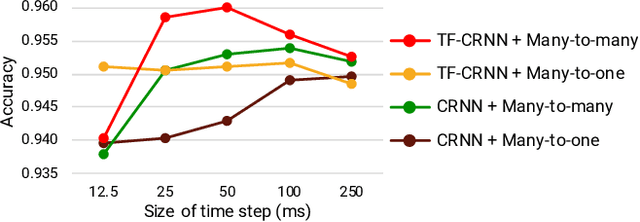
While end-to-end learning has become a trend in deep learning, the model architecture is often designed to incorporate domain knowledge. We propose a novel convolutional recurrent neural network (CRNN) architecture with temporal feedback connections, inspired by the feedback pathways from the brain to ears in the human auditory system. The proposed architecture uses a hidden state of the RNN module at the previous time to control the sensitivity of channel-wise feature activations in the CNN blocks at the current time, which is analogous to the mechanism of the outer hair-cell. We apply the proposed model to keyword spotting where the speech commands have sequential nature. We show the proposed model consistently outperforms the compared model without temporal feedback for different input/output settings in the CRNN framework. We also investigate the details of the performance improvement by conducting a failure analysis of the keyword spotting task and a visualization of the channel-wise feature scaling in each CNN block.
Sample-level CNN Architectures for Music Auto-tagging Using Raw Waveforms
Feb 14, 2018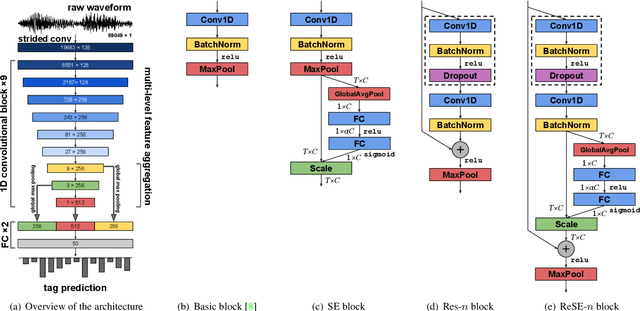
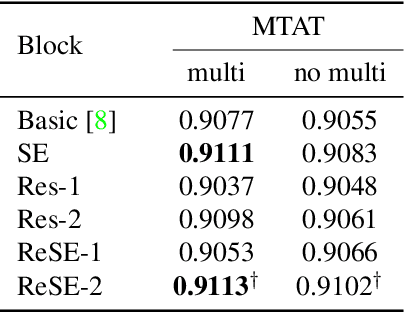
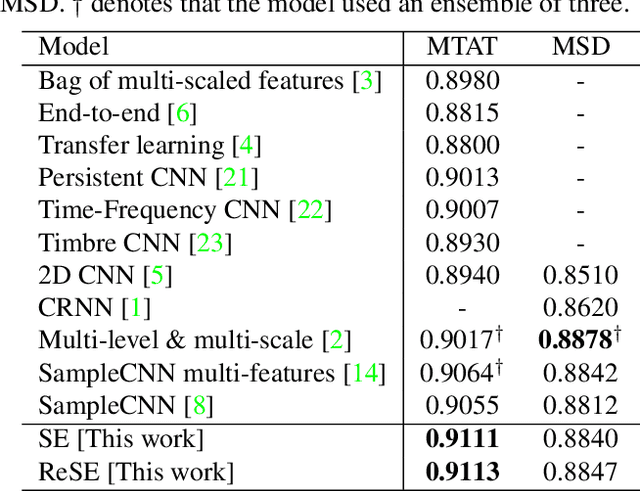
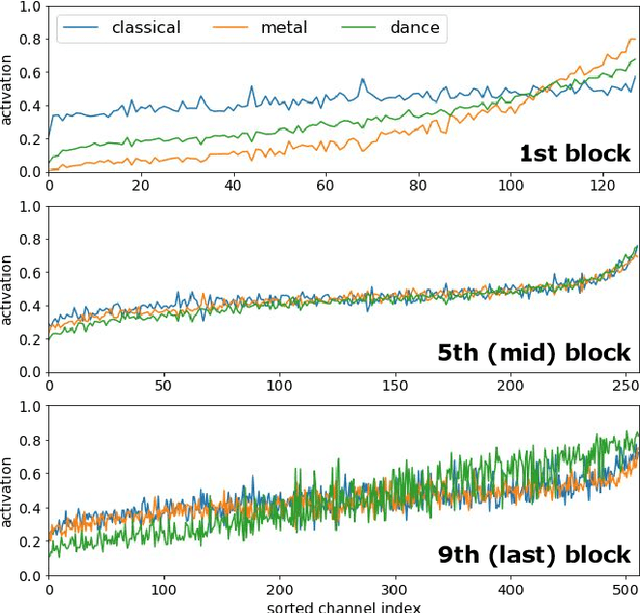
Recent work has shown that the end-to-end approach using convolutional neural network (CNN) is effective in various types of machine learning tasks. For audio signals, the approach takes raw waveforms as input using an 1-D convolution layer. In this paper, we improve the 1-D CNN architecture for music auto-tagging by adopting building blocks from state-of-the-art image classification models, ResNets and SENets, and adding multi-level feature aggregation to it. We compare different combinations of the modules in building CNN architectures. The results show that they achieve significant improvements over previous state-of-the-art models on the MagnaTagATune dataset and comparable results on Million Song Dataset. Furthermore, we analyze and visualize our model to show how the 1-D CNN operates.
Raw Waveform-based Audio Classification Using Sample-level CNN Architectures
Dec 04, 2017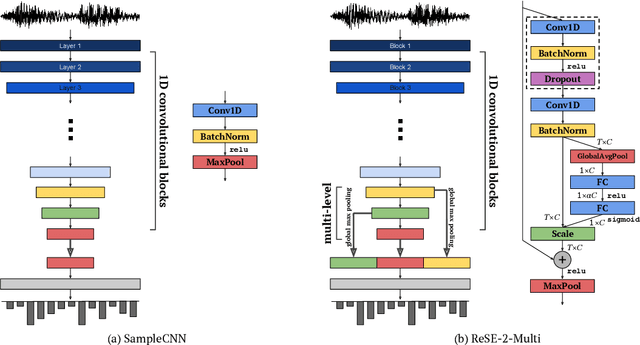
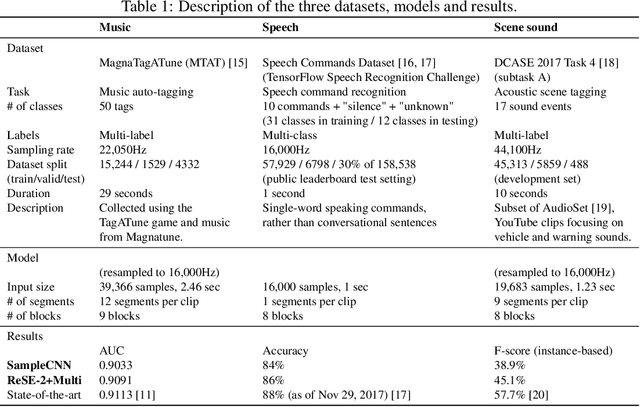
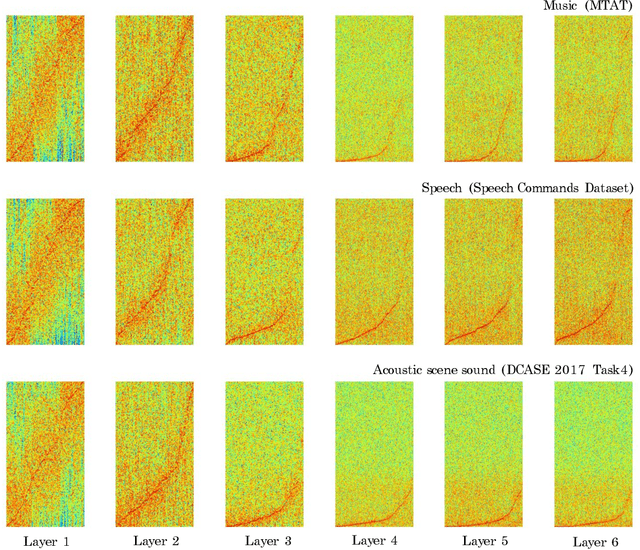
Music, speech, and acoustic scene sound are often handled separately in the audio domain because of their different signal characteristics. However, as the image domain grows rapidly by versatile image classification models, it is necessary to study extensible classification models in the audio domain as well. In this study, we approach this problem using two types of sample-level deep convolutional neural networks that take raw waveforms as input and uses filters with small granularity. One is a basic model that consists of convolution and pooling layers. The other is an improved model that additionally has residual connections, squeeze-and-excitation modules and multi-level concatenation. We show that the sample-level models reach state-of-the-art performance levels for the three different categories of sound. Also, we visualize the filters along layers and compare the characteristics of learned filters.