 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Feedback Convolutional Recurrent Neural Networks for Keyword Spotting
Paper and Code
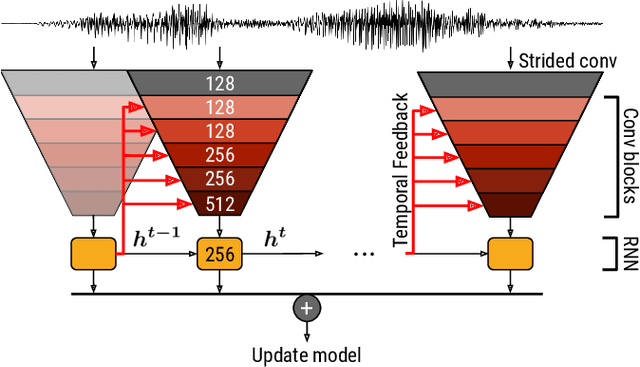
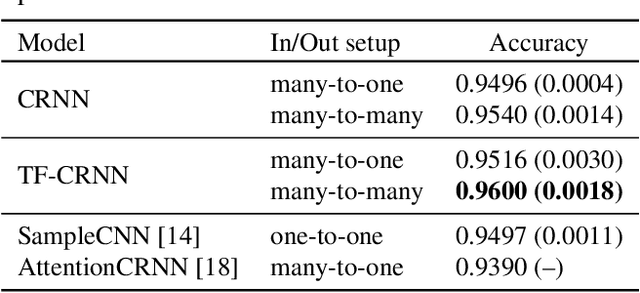
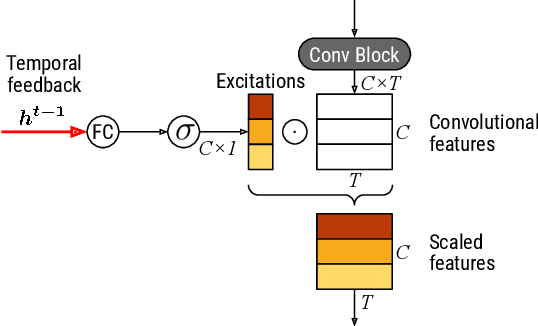
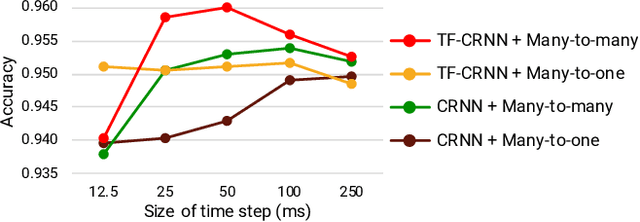
While end-to-end learning has become a trend in deep learning, the model architecture is often designed to incorporate domain knowledge. We propose a novel convolutional recurrent neural network (CRNN) architecture with temporal feedback connections, inspired by the feedback pathways from the brain to ears in the human auditory system. The proposed architecture uses a hidden state of the RNN module at the previous time to control the sensitivity of channel-wise feature activations in the CNN blocks at the current time, which is analogous to the mechanism of the outer hair-cell. We apply the proposed model to keyword spotting where the speech commands have sequential nature. We show the proposed model consistently outperforms the compared model without temporal feedback for different input/output settings in the CRNN framework. We also investigate the details of the performance improvement by conducting a failure analysis of the keyword spotting task and a visualization of the channel-wise feature scaling in each CNN block.