 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Content-User Embedding Model for Music Recommendation
Jul 18, 2018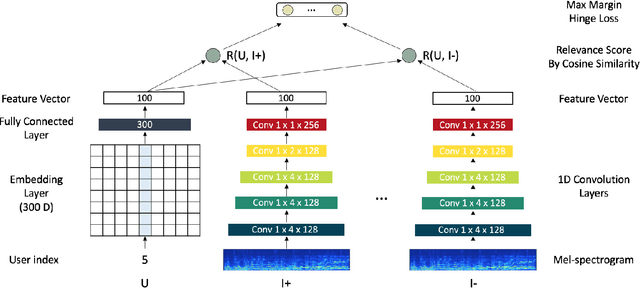


Recently deep learning based recommendation systems have been actively explored to solve the cold-start problem using a hybrid approach. However, the majority of previous studies proposed a hybrid model where collaborative filtering and content-based filtering modules are independently trained. The end-to-end approach that takes different modality data as input and jointly trains the model can provide better optimization but it has not been fully explored yet. In this work, we propose deep content-user embedding model, a simple and intuitive architecture that combines the user-item interaction and music audio content. We evaluate the model on music recommendation and music auto-tagging tasks. The results show that the proposed model significantly outperforms the previous work. We also discuss various directions to improve the proposed model further.
Automatic Music Highlight Extraction using Convolutional Recurrent Attention Networks
Dec 16, 2017
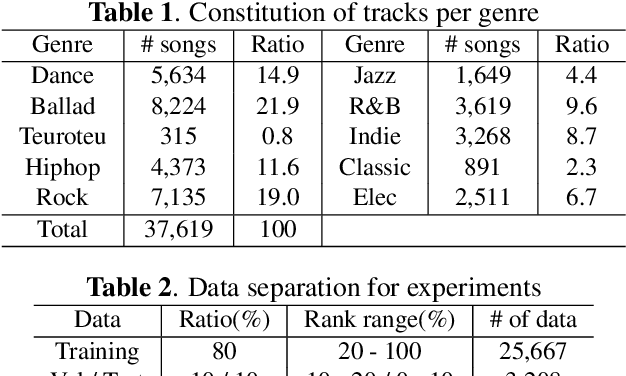

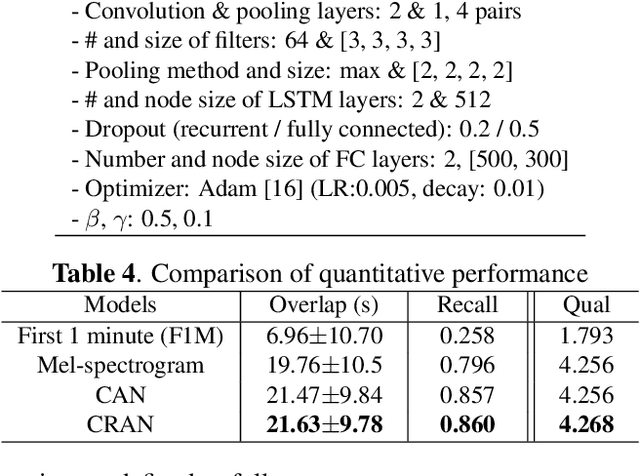
Music highlights are valuable contents for music services. Most methods focused on low-level signal features. We propose a method for extracting highlights using high-level features from convolutional recurrent attention networks (CRAN). CRAN utilizes convolution and recurrent layers for sequential learning with an attention mechanism. The attention allows CRAN to capture significant snippets for distinguishing between genres, thus being used as a high-level feature. CRAN was evaluated on over 32,000 popular tracks in Korea for two months. Experimental results show our method outperforms three baseline methods through quantitative and qualitative evaluations. Also, we analyze the effects of attention and sequence information on performance.