 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Way Did It Move? Diagnosing and Overcoming Directional Motion Blindness in Video-LLMs
May 21, 2026Video Large Language Models (Video-LLMs) have made rapid progress on temporal video understanding, yet many fail at a basic perceptual primitive: signed image-plane motion direction. On simple videos of a single object moving left, right, up, or down, most Video-LLMs perform near chance, with above-chance cases largely attributable to prediction biases rather than genuine direction understanding. We call this failure directional motion blindness. We localize the failure by tracing motion direction information through the Video-LLM pipeline. Motion direction remains linearly accessible from the vision encoder, projector, and LLM hidden states, but the readout fails to bind this signal to the correct verbal answer option, revealing a direction binding gap. Although synthetic motion direction instruction tuning reduces this gap on the source domain, motion direction concept vector analysis shows that visual complexity weakens the signal magnitude and limits out-of-domain generalization. We introduce MoDirect, a dataset family for motion direction instruction tuning and evaluation, and DeltaDirect, a diagnosis-driven, projector-level objective that predicts normalized 2-D motion vectors from adjacent-frame feature deltas. On MoDirect-SynBench, instruction tuning with DeltaDirect improves motion direction accuracy from 25.9% to 85.4%. On MoDirect-RealBench, DeltaDirect improves real-world motion direction accuracy by 21.9 points over the vanilla baseline without real-world tuning data, while preserving standard video-understanding performance. Code: https://github.com/KHU-VLL/DeltaDirect
WebGen-R1: Incentivizing Large Language Models to Generate Functional and Aesthetic Websites with Reinforcement Learning
Apr 22, 2026While Large Language Models (LLMs) excel at function-level code generation, project-level tasks such as generating functional and visually aesthetic multi-page websites remain highly challenging. Existing works are often limited to single-page static websites, while agentic frameworks typically rely on multi-turn execution with proprietary models, leading to substantial token costs, high latency, and brittle integration. Training a small LLM end-to-end with reinforcement learning (RL) is a promising alternative, yet it faces a critical bottleneck in designing reliable and computationally feasible rewards for website generation. Unlike single-file coding tasks that can be verified by unit tests, website generation requires evaluating inherently subjective aesthetics, cross-page interactions, and functional correctness. To this end, we propose WebGen-R1, an end-to-end RL framework tailored for project-level website generation. We first introduce a scaffold-driven structured generation paradigm that constrains the large open-ended action space and preserves architectural integrity. We then design a novel cascaded multimodal reward that seamlessly couples structural guarantees with execution-grounded functional feedback and vision-based aesthetic supervision. Extensive experiments demonstrate that our WebGen-R1 substantially transforms a 7B base model from generating nearly nonfunctional websites into producing deployable, aesthetically aligned multi-page websites. Remarkably, our WebGen-R1 not only consistently outperforms heavily scaled open-source models (up to 72B), but also rivals the state-of-the-art DeepSeek-R1 (671B) in functional success, while substantially exceeding it in valid rendering and aesthetic alignment. These results position WebGen-R1 as a viable path for scaling small open models from function-level code generation to project-level web application generation.
FourierMoE: Fourier Mixture-of-Experts Adaptation of Large Language Models
Apr 02, 2026Parameter-efficient fine-tuning (PEFT) has emerged as a crucial paradigm for adapting large language models (LLMs) under constrained computational budgets. However, standard PEFT methods often struggle in multi-task fine-tuning settings, where diverse optimization objectives induce task interference and limited parameter budgets lead to representational deficiency. While recent approaches incorporate mixture-of-experts (MoE) to alleviate these issues, they predominantly operate in the spatial domain, which may introduce structural redundancy and parameter overhead. To overcome these limitations, we reformulate adaptation in the spectral domain. Our spectral analysis reveals that different tasks exhibit distinct frequency energy distributions, and that LLM layers display heterogeneous frequency sensitivities. Motivated by these insights, we propose FourierMoE, which integrates the MoE architecture with the inverse discrete Fourier transform (IDFT) for frequency-aware adaptation. Specifically, FourierMoE employs a frequency-adaptive router to dispatch tokens to experts specialized in distinct frequency bands. Each expert learns a set of conjugate-symmetric complex coefficients, preserving complete phase and amplitude information while theoretically guaranteeing lossless IDFT reconstruction into real-valued spatial weights. Extensive evaluations across 28 benchmarks, multiple model architectures, and scales demonstrate that FourierMoE consistently outperforms competitive baselines in both single-task and multi-task settings while using significantly fewer trainable parameters. These results highlight the promise of spectral-domain expert adaptation as an effective and parameter-efficient paradigm for LLM fine-tuning.
Solar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
DTRec: Learning Dynamic Reasoning Trajectories for Sequential Recommendation
Dec 16, 2025

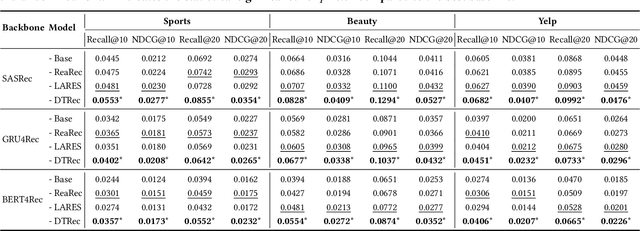

Inspired by advances in LLMs, reasoning-enhanced sequential recommendation performs multi-step deliberation before making final predictions, unlocking greater potential for capturing user preferences. However, current methods are constrained by static reasoning trajectories that are ill-suited for the diverse complexity of user behaviors. They suffer from two key limitations: (1) a static reasoning direction, which uses flat supervision signals misaligned with human-like hierarchical reasoning, and (2) a fixed reasoning depth, which inefficiently applies the same computational effort to all users, regardless of pattern complexity. These rigidity lead to suboptimal performance and significant computational waste. To overcome these challenges, we propose DTRec, a novel and effective framework that explores the Dynamic reasoning Trajectory for Sequential Recommendation along both direction and depth. To guide the direction, we develop Hierarchical Process Supervision (HPS), which provides coarse-to-fine supervisory signals to emulate the natural, progressive refinement of human cognitive processes. To optimize the depth, we introduce the Adaptive Reasoning Halting (ARH) mechanism that dynamically adjusts the number of reasoning steps by jointly monitoring three indicators. Extensive experiments on three real-world datasets demonstrate the superiority of our approach, achieving up to a 24.5% performance improvement over strong baselines while simultaneously reducing computational cost by up to 41.6%.
Objectomaly: Objectness-Aware Refinement for OoD Segmentation with Structural Consistency and Boundary Precision
Jul 10, 2025



Out-of-Distribution (OoD) segmentation is critical for safety-sensitive applications like autonomous driving. However, existing mask-based methods often suffer from boundary imprecision, inconsistent anomaly scores within objects, and false positives from background noise. We propose \textbf{\textit{Objectomaly}}, an objectness-aware refinement framework that incorporates object-level priors. Objectomaly consists of three stages: (1) Coarse Anomaly Scoring (CAS) using an existing OoD backbone, (2) Objectness-Aware Score Calibration (OASC) leveraging SAM-generated instance masks for object-level score normalization, and (3) Meticulous Boundary Precision (MBP) applying Laplacian filtering and Gaussian smoothing for contour refinement. Objectomaly achieves state-of-the-art performance on key OoD segmentation benchmarks, including SMIYC AnomalyTrack/ObstacleTrack and RoadAnomaly, improving both pixel-level (AuPRC up to 96.99, FPR$_{95}$ down to 0.07) and component-level (F1$-$score up to 83.44) metrics. Ablation studies and qualitative results on real-world driving videos further validate the robustness and generalizability of our method. Code will be released upon publication.
KaSA: Knowledge-Aware Singular-Value Adaptation of Large Language Models
Dec 08, 2024The increasing sizes of large language models (LLMs) result in significant computational overhead and memory usage when adapting these models to specific tasks or domains. Various parameter-efficient fine-tuning (PEFT) methods have been devised to mitigate these challenges by training a small set of parameters for the task-specific updates of the model weights. Among PEFT methods, LoRA stands out for its simplicity and efficiency, inspiring the development of a series of variants. However, LoRA and its successors disregard the knowledge that is noisy or irrelevant to the targeted task, detrimentally impacting model performance and leading to suboptimality. To address this limitation, we introduce Knowledge-aware Singular-value Adaptation (KaSA), a PEFT method that leverages singular value decomposition (SVD) with knowledge-aware singular values to dynamically activate knowledge based on its relevance to the task at hand. We conduct extensive experiments across a range of LLMs on tasks spanning natural language understanding (NLU), generation (NLG), instruction following, and commonsense reasoning. The experimental results demonstrate that KaSA consistently outperforms FFT and 14 popular PEFT baselines across 16 benchmarks and 4 synthetic datasets, underscoring our method's efficacy and adaptability. The source code of our method is available at https://github.com/juyongjiang/KaSA.
LlamaDuo: LLMOps Pipeline for Seamless Migration from Service LLMs to Small-Scale Local LLMs
Aug 24, 2024The widespread adoption of cloud-based proprietary large language models (LLMs) has introduced significant challenges, including operational dependencies, privacy concerns, and the necessity of continuous internet connectivity. In this work, we introduce an LLMOps pipeline, "LlamaDuo", for the seamless migration of knowledge and abilities from service-oriented LLMs to smaller, locally manageable models. This pipeline is crucial for ensuring service continuity in the presence of operational failures, strict privacy policies, or offline requirements. Our LlamaDuo involves fine-tuning a small language model against the service LLM using a synthetic dataset generated by the latter. If the performance of the fine-tuned model falls short of expectations, it is enhanced by further fine-tuning with additional similar data created by the service LLM. This iterative process guarantees that the smaller model can eventually match or even surpass the service LLM's capabilities in specific downstream tasks, offering a practical and scalable solution for managing AI deployments in constrained environments. Extensive experiments with leading edge LLMs are conducted to demonstrate the effectiveness, adaptability, and affordability of LlamaDuo across various downstream tasks. Our pipeline implementation is available at https://github.com/deep-diver/llamaduo.
A Survey on Mixture of Experts
Jun 26, 2024Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
GPT4Rec: Graph Prompt Tuning for Streaming Recommendation
Jun 12, 2024



In the realm of personalized recommender systems, the challenge of adapting to evolving user preferences and the continuous influx of new users and items is paramount. Conventional models, typically reliant on a static training-test approach, struggle to keep pace with these dynamic demands. Streaming recommendation, particularly through continual graph learning, has emerged as a novel solution. However, existing methods in this area either rely on historical data replay, which is increasingly impractical due to stringent data privacy regulations; or are inability to effectively address the over-stability issue; or depend on model-isolation and expansion strategies. To tackle these difficulties, we present GPT4Rec, a Graph Prompt Tuning method for streaming Recommendation. Given the evolving user-item interaction graph, GPT4Rec first disentangles the graph patterns into multiple views. After isolating specific interaction patterns and relationships in different views, GPT4Rec utilizes lightweight graph prompts to efficiently guide the model across varying interaction patterns within the user-item graph. Firstly, node-level prompts are employed to instruct the model to adapt to changes in the attributes or properties of individual nodes within the graph. Secondly, structure-level prompts guide the model in adapting to broader patterns of connectivity and relationships within the graph. Finally, view-level prompts are innovatively designed to facilitate the aggregation of information from multiple disentangled views. These prompt designs allow GPT4Rec to synthesize a comprehensive understanding of the graph, ensuring that all vital aspects of the user-item interactions are considered and effectively integrated. Experiments on four diverse real-world datasets demonstrate the effectiveness and efficiency of our proposal.