 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Contrastive Learning Necessary? A Study of Data Augmentation vs Contrastive Learning in Sequential Recommendation
Mar 17, 2024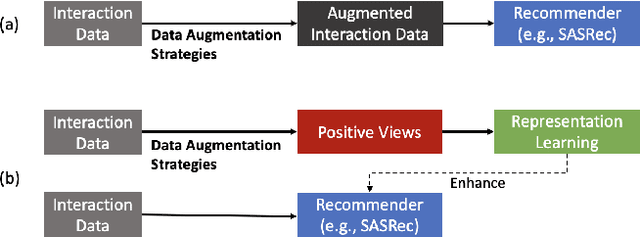
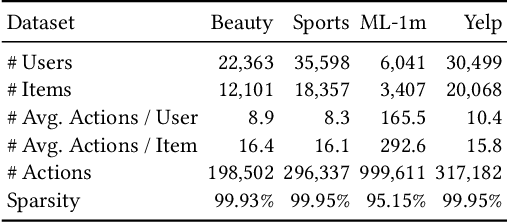
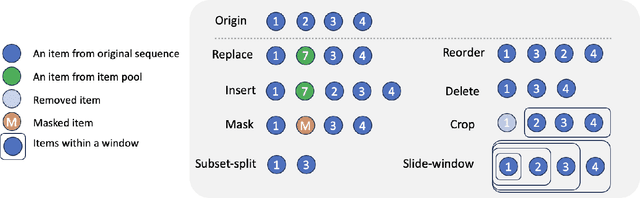
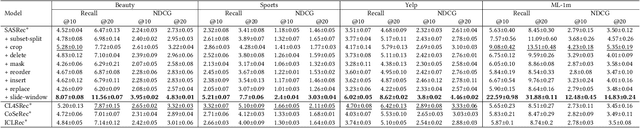
Sequential recommender systems (SRS) are designed to predict users' future behaviors based on their historical interaction data. Recent research has increasingly utilized contrastive learning (CL) to leverage unsupervised signals to alleviate the data sparsity issue in SRS. In general, CL-based SRS first augments the raw sequential interaction data by using data augmentation strategies and employs a contrastive training scheme to enforce the representations of those sequences from the same raw interaction data to be similar. Despite the growing popularity of CL, data augmentation, as a basic component of CL, has not received sufficient attention. This raises the question: Is it possible to achieve superior recommendation results solely through data augmentation? To answer this question, we benchmark eight widely used data augmentation strategies, as well as state-of-the-art CL-based SRS methods, on four real-world datasets under both warm- and cold-start settings. Intriguingly, the conclusion drawn from our study is that, certain data augmentation strategies can achieve similar or even superior performance compared with some CL-based methods, demonstrating the potential to significantly alleviate the data sparsity issue with fewer computational overhead. We hope that our study can further inspire more fundamental studies on the key functional components of complex CL techniques. Our processed datasets and codes are available at https://github.com/AIM-SE/DA4Rec.
Attention Calibration for Transformer-based Sequential Recommendation
Aug 18, 2023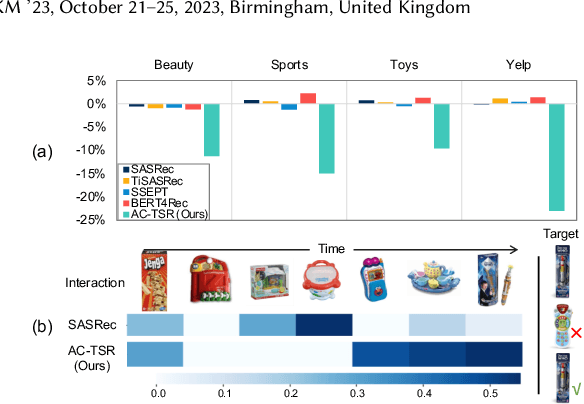
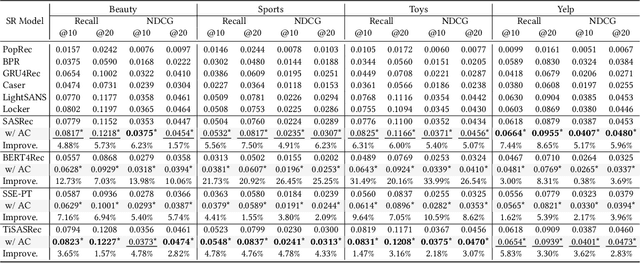
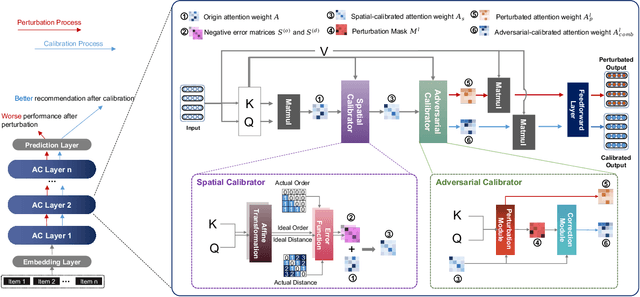
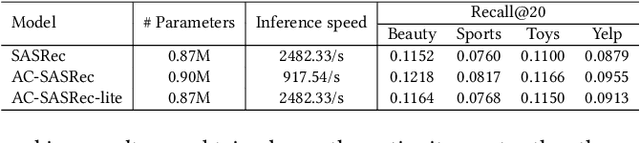
Transformer-based sequential recommendation (SR) has been booming in recent years, with the self-attention mechanism as its key component. Self-attention has been widely believed to be able to effectively select those informative and relevant items from a sequence of interacted items for next-item prediction via learning larger attention weights for these items. However, this may not always be true in reality. Our empirical analysis of some representative Transformer-based SR models reveals that it is not uncommon for large attention weights to be assigned to less relevant items, which can result in inaccurate recommendations. Through further in-depth analysis, we find two factors that may contribute to such inaccurate assignment of attention weights: sub-optimal position encoding and noisy input. To this end, in this paper, we aim to address this significant yet challenging gap in existing works. To be specific, we propose a simple yet effective framework called Attention Calibration for Transformer-based Sequential Recommendation (AC-TSR). In AC-TSR, a novel spatial calibrator and adversarial calibrator are designed respectively to directly calibrates those incorrectly assigned attention weights. The former is devised to explicitly capture the spatial relationships (i.e., order and distance) among items for more precise calculation of attention weights. The latter aims to redistribute the attention weights based on each item's contribution to the next-item prediction. AC-TSR is readily adaptable and can be seamlessly integrated into various existing transformer-based SR models. Extensive experimental results on four benchmark real-world datasets demonstrate the superiority of our proposed ACTSR via significant recommendation performance enhancements. The source code is available at https://github.com/AIM-SE/AC-TSR.
Rethinking Multi-Interest Learning for Candidate Matching in Recommender Systems
Feb 28, 2023Existing research efforts for multi-interest candidate matching in recommender systems mainly focus on improving model architecture or incorporating additional information, neglecting the importance of training schemes. This work revisits the training framework and uncovers two major problems hindering the expressiveness of learned multi-interest representations. First, the current training objective (i.e., uniformly sampled softmax) fails to effectively train discriminative representations in a multi-interest learning scenario due to the severe increase in easy negative samples. Second, a routing collapse problem is observed where each learned interest may collapse to express information only from a single item, resulting in information loss. To address these issues, we propose the REMI framework, consisting of an Interest-aware Hard Negative mining strategy (IHN) and a Routing Regularization (RR) method. IHN emphasizes interest-aware hard negatives by proposing an ideal sampling distribution and developing a Monte-Carlo strategy for efficient approximation. RR prevents routing collapse by introducing a novel regularization term on the item-to-interest routing matrices. These two components enhance the learned multi-interest representations from both the optimization objective and the composition information. REMI is a general framework that can be readily applied to various existing multi-interest candidate matching methods. Experiments on three real-world datasets show our method can significantly improve state-of-the-art methods with easy implementation and negligible computational overhead. The source code will be released.
Equivariant Contrastive Learning for Sequential Recommendation
Nov 18, 2022Contrastive learning (CL) benefits the training of sequential recommendation models with informative self-supervision signals. Existing solutions apply general sequential data augmentation strategies to generate positive pairs and encourage their representations to be invariant. However, due to the inherent properties of user behavior sequences, some augmentation strategies, such as item substitution, can lead to changes in user intent. Learning indiscriminately invariant representations for all augmentation strategies might be sub-optimal. Therefore, we propose Equivariant Contrastive Learning for Sequential Recommendation (ECL-SR), which endows SR models with great discriminative power, making the learned user behavior representations sensitive to invasive augmentations (e.g., item substitution) and insensitive to mild augmentations (e.g., feature-level dropout masking). In detail, we use the conditional discriminator to capture differences in behavior due to item substitution, which encourages the user behavior encoder to be equivariant to invasive augmentations. Comprehensive experiments on four benchmark datasets show that the proposed ECL-SR framework achieves competitive performance compared to state-of-the-art SR models. The source code will be released.