 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Contrastive Learning Necessary? A Study of Data Augmentation vs Contrastive Learning in Sequential Recommendation
Paper and Code
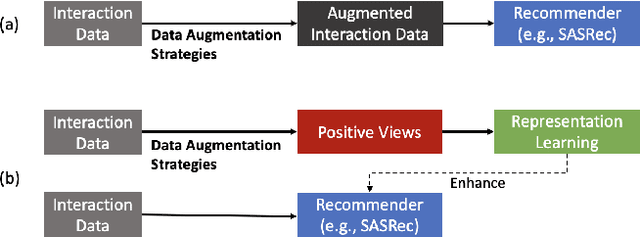
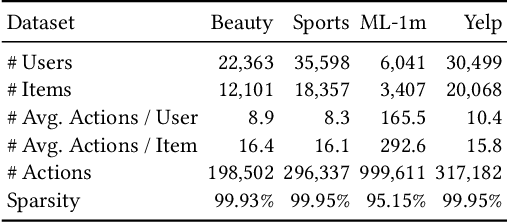
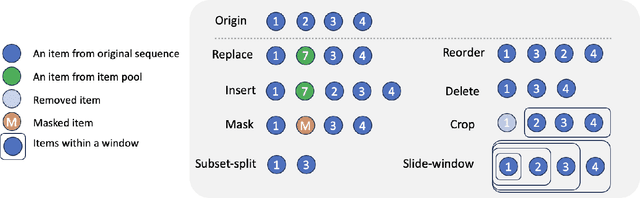
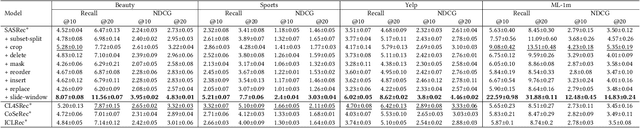
Sequential recommender systems (SRS) are designed to predict users' future behaviors based on their historical interaction data. Recent research has increasingly utilized contrastive learning (CL) to leverage unsupervised signals to alleviate the data sparsity issue in SRS. In general, CL-based SRS first augments the raw sequential interaction data by using data augmentation strategies and employs a contrastive training scheme to enforce the representations of those sequences from the same raw interaction data to be similar. Despite the growing popularity of CL, data augmentation, as a basic component of CL, has not received sufficient attention. This raises the question: Is it possible to achieve superior recommendation results solely through data augmentation? To answer this question, we benchmark eight widely used data augmentation strategies, as well as state-of-the-art CL-based SRS methods, on four real-world datasets under both warm- and cold-start settings. Intriguingly, the conclusion drawn from our study is that, certain data augmentation strategies can achieve similar or even superior performance compared with some CL-based methods, demonstrating the potential to significantly alleviate the data sparsity issue with fewer computational overhead. We hope that our study can further inspire more fundamental studies on the key functional components of complex CL techniques. Our processed datasets and codes are available at https://github.com/AIM-SE/DA4Rec.