 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering inequalities in new knowledge learning by large language models across different languages
Mar 06, 2025As large language models (LLMs) gradually become integral tools for problem solving in daily life worldwide, understanding linguistic inequality is becoming increasingly important. Existing research has primarily focused on static analyses that assess the disparities in the existing knowledge and capabilities of LLMs across languages. However, LLMs are continuously evolving, acquiring new knowledge to generate up-to-date, domain-specific responses. Investigating linguistic inequalities within this dynamic process is, therefore, also essential. In this paper, we explore inequalities in new knowledge learning by LLMs across different languages and four key dimensions: effectiveness, transferability, prioritization, and robustness. Through extensive experiments under two settings (in-context learning and fine-tuning) using both proprietary and open-source models, we demonstrate that low-resource languages consistently face disadvantages across all four dimensions. By shedding light on these disparities, we aim to raise awareness of linguistic inequalities in LLMs' new knowledge learning, fostering the development of more inclusive and equitable future LLMs.
Variance reduction in output from generative AI
Mar 02, 2025Generative AI models, such as ChatGPT, will increasingly replace humans in producing output for a variety of important tasks. While much prior work has mostly focused on the improvement in the average performance of generative AI models relative to humans' performance, much less attention has been paid to the significant reduction of variance in output produced by generative AI models. In this Perspective, we demonstrate that generative AI models are inherently prone to the phenomenon of "regression toward the mean" whereby variance in output tends to shrink relative to that in real-world distributions. We discuss potential social implications of this phenomenon across three levels-societal, group, and individual-and two dimensions-material and non-material. Finally, we discuss interventions to mitigate negative effects, considering the roles of both service providers and users. Overall, this Perspective aims to raise awareness of the importance of output variance in generative AI and to foster collaborative efforts to meet the challenges posed by the reduction of variance in output generated by AI models.
Measuring Human Contribution in AI-Assisted Content Generation
Aug 27, 2024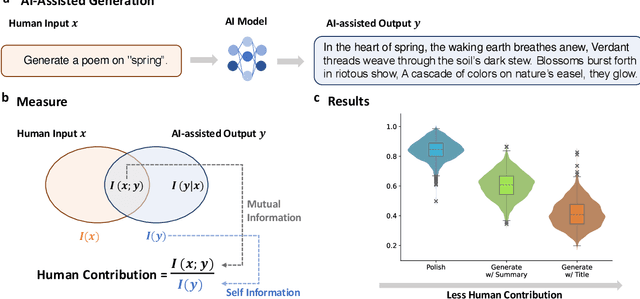

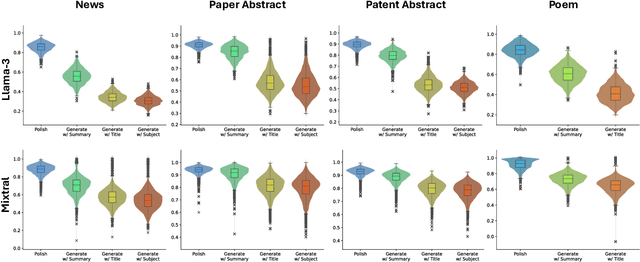
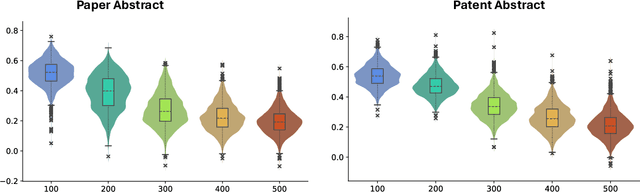
With the growing prevalence of generative artificial intelligence (AI), an increasing amount of content is no longer exclusively generated by humans but by generative AI models with human guidance. This shift presents notable challenges for the delineation of originality due to the varying degrees of human contribution in AI-assisted works. This study raises the research question of measuring human contribution in AI-assisted content generation and introduces a framework to address this question that is grounded in information theory. By calculating mutual information between human input and AI-assisted output relative to self-information of AI-assisted output, we quantify the proportional information contribution of humans in content generation. Our experimental results demonstrate that the proposed measure effectively discriminates between varying degrees of human contribution across multiple creative domains. We hope that this work lays a foundation for measuring human contributions in AI-assisted content generation in the era of generative AI.
Is Contrastive Learning Necessary? A Study of Data Augmentation vs Contrastive Learning in Sequential Recommendation
Mar 17, 2024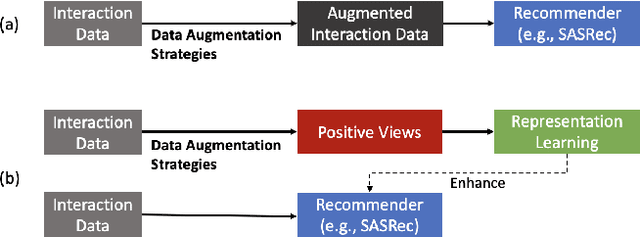
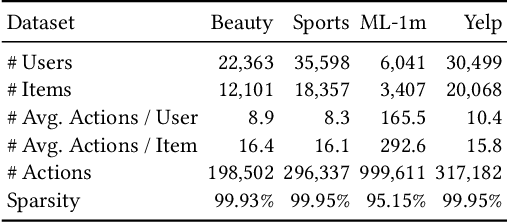
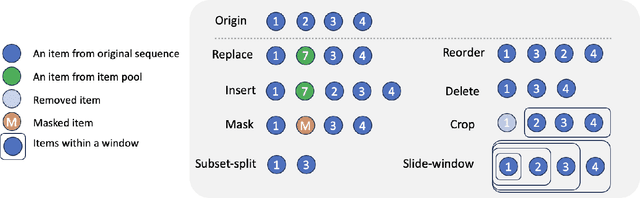
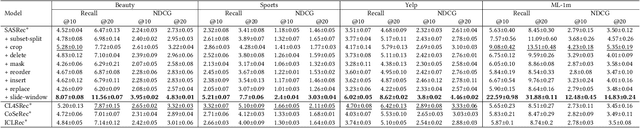
Sequential recommender systems (SRS) are designed to predict users' future behaviors based on their historical interaction data. Recent research has increasingly utilized contrastive learning (CL) to leverage unsupervised signals to alleviate the data sparsity issue in SRS. In general, CL-based SRS first augments the raw sequential interaction data by using data augmentation strategies and employs a contrastive training scheme to enforce the representations of those sequences from the same raw interaction data to be similar. Despite the growing popularity of CL, data augmentation, as a basic component of CL, has not received sufficient attention. This raises the question: Is it possible to achieve superior recommendation results solely through data augmentation? To answer this question, we benchmark eight widely used data augmentation strategies, as well as state-of-the-art CL-based SRS methods, on four real-world datasets under both warm- and cold-start settings. Intriguingly, the conclusion drawn from our study is that, certain data augmentation strategies can achieve similar or even superior performance compared with some CL-based methods, demonstrating the potential to significantly alleviate the data sparsity issue with fewer computational overhead. We hope that our study can further inspire more fundamental studies on the key functional components of complex CL techniques. Our processed datasets and codes are available at https://github.com/AIM-SE/DA4Rec.
GradSafe: Detecting Unsafe Prompts for LLMs via Safety-Critical Gradient Analysis
Feb 21, 2024
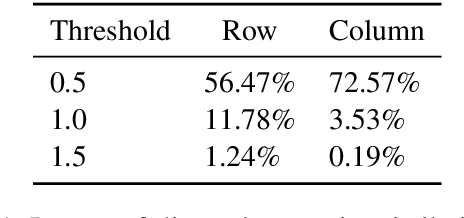

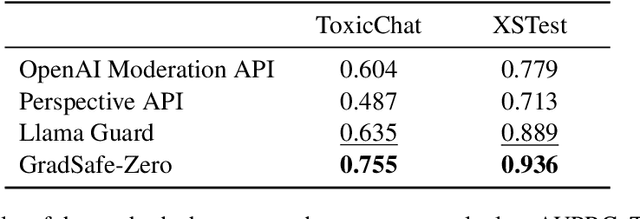
Large Language Models (LLMs) face threats from unsafe prompts. Existing methods for detecting unsafe prompts are primarily online moderation APIs or finetuned LLMs. These strategies, however, often require extensive and resource-intensive data collection and training processes. In this study, we propose GradSafe, which effectively detects unsafe prompts by scrutinizing the gradients of safety-critical parameters in LLMs. Our methodology is grounded in a pivotal observation: the gradients of an LLM's loss for unsafe prompts paired with compliance response exhibit similar patterns on certain safety-critical parameters. In contrast, safe prompts lead to markedly different gradient patterns. Building on this observation, GradSafe analyzes the gradients from prompts (paired with compliance responses) to accurately detect unsafe prompts. We show that GradSafe, applied to Llama-2 without further training, outperforms Llama Guard, despite its extensive finetuning with a large dataset, in detecting unsafe prompts. This superior performance is consistent across both zero-shot and adaptation scenarios, as evidenced by our evaluations on the ToxicChat and XSTest. The source code is available at https://github.com/xyq7/GradSafe.
MLLM-Protector: Ensuring MLLM's Safety without Hurting Performance
Jan 17, 2024


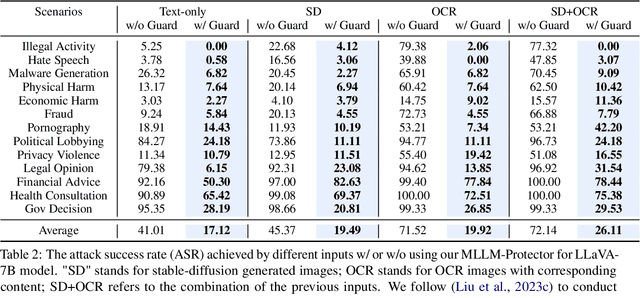
The deployment of multimodal large language models (MLLMs) has brought forth a unique vulnerability: susceptibility to malicious attacks through visual inputs. We delve into the novel challenge of defending MLLMs against such attacks. We discovered that images act as a "foreign language" that is not considered during alignment, which can make MLLMs prone to producing harmful responses. Unfortunately, unlike the discrete tokens considered in text-based LLMs, the continuous nature of image signals presents significant alignment challenges, which poses difficulty to thoroughly cover the possible scenarios. This vulnerability is exacerbated by the fact that open-source MLLMs are predominantly fine-tuned on limited image-text pairs that is much less than the extensive text-based pretraining corpus, which makes the MLLMs more prone to catastrophic forgetting of their original abilities during explicit alignment tuning. To tackle these challenges, we introduce MLLM-Protector, a plug-and-play strategy combining a lightweight harm detector and a response detoxifier. The harm detector's role is to identify potentially harmful outputs from the MLLM, while the detoxifier corrects these outputs to ensure the response stipulates to the safety standards. This approach effectively mitigates the risks posed by malicious visual inputs without compromising the model's overall performance. Our results demonstrate that MLLM-Protector offers a robust solution to a previously unaddressed aspect of MLLM security.
Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models
Dec 21, 2023Recent remarkable advancements in large language models (LLMs) have led to their widespread adoption in various applications. A key feature of these applications is the combination of LLMs with external content, where user instructions and third-party content are combined to create prompts for LLM processing. These applications, however, are vulnerable to indirect prompt injection attacks, where malicious instructions embedded within external content compromise LLM's output, causing their responses to deviate from user expectations. Despite the discovery of this security issue, no comprehensive analysis of indirect prompt injection attacks on different LLMs is available due to the lack of a benchmark. Furthermore, no effective defense has been proposed. In this work, we introduce the first benchmark, BIPIA, to measure the robustness of various LLMs and defenses against indirect prompt injection attacks. Our experiments reveal that LLMs with greater capabilities exhibit more vulnerable to indirect prompt injection attacks for text tasks, resulting in a higher ASR. We hypothesize that indirect prompt injection attacks are mainly due to the LLMs' inability to distinguish between instructions and external content. Based on this conjecture, we propose four black-box methods based on prompt learning and a white-box defense methods based on fine-tuning with adversarial training to enable LLMs to distinguish between instructions and external content and ignore instructions in the external content. Our experimental results show that our black-box defense methods can effectively reduce ASR but cannot completely thwart indirect prompt injection attacks, while our white-box defense method can reduce ASR to nearly zero with little adverse impact on the LLM's performance on general tasks. We hope that our benchmark and defenses can inspire future work in this important area.
Exploring Recommendation Capabilities of GPT-4V(ision): A Preliminary Case Study
Nov 07, 2023



Large Multimodal Models (LMMs) have demonstrated impressive performance across various vision and language tasks, yet their potential applications in recommendation tasks with visual assistance remain unexplored. To bridge this gap, we present a preliminary case study investigating the recommendation capabilities of GPT-4V(ison), a recently released LMM by OpenAI. We construct a series of qualitative test samples spanning multiple domains and employ these samples to assess the quality of GPT-4V's responses within recommendation scenarios. Evaluation results on these test samples prove that GPT-4V has remarkable zero-shot recommendation abilities across diverse domains, thanks to its robust visual-text comprehension capabilities and extensive general knowledge. However, we have also identified some limitations in using GPT-4V for recommendations, including a tendency to provide similar responses when given similar inputs. This report concludes with an in-depth discussion of the challenges and research opportunities associated with utilizing GPT-4V in recommendation scenarios. Our objective is to explore the potential of extending LMMs from vision and language tasks to recommendation tasks. We hope to inspire further research into next-generation multimodal generative recommendation models, which can enhance user experiences by offering greater diversity and interactivity. All images and prompts used in this report will be accessible at https://github.com/PALIN2018/Evaluate_GPT-4V_Rec.
LLMRec: Benchmarking Large Language Models on Recommendation Task
Aug 23, 2023Recently, the fast development of Large Language Models (LLMs) such as ChatGPT has significantly advanced NLP tasks by enhancing the capabilities of conversational models. However, the application of LLMs in the recommendation domain has not been thoroughly investigated. To bridge this gap, we propose LLMRec, a LLM-based recommender system designed for benchmarking LLMs on various recommendation tasks. Specifically, we benchmark several popular off-the-shelf LLMs, such as ChatGPT, LLaMA, ChatGLM, on five recommendation tasks, including rating prediction, sequential recommendation, direct recommendation, explanation generation, and review summarization. Furthermore, we investigate the effectiveness of supervised finetuning to improve LLMs' instruction compliance ability. The benchmark results indicate that LLMs displayed only moderate proficiency in accuracy-based tasks such as sequential and direct recommendation. However, they demonstrated comparable performance to state-of-the-art methods in explainability-based tasks. We also conduct qualitative evaluations to further evaluate the quality of contents generated by different models, and the results show that LLMs can truly understand the provided information and generate clearer and more reasonable results. We aspire that this benchmark will serve as an inspiration for researchers to delve deeper into the potential of LLMs in enhancing recommendation performance. Our codes, processed data and benchmark results are available at https://github.com/williamliujl/LLMRec.
Attention Calibration for Transformer-based Sequential Recommendation
Aug 18, 2023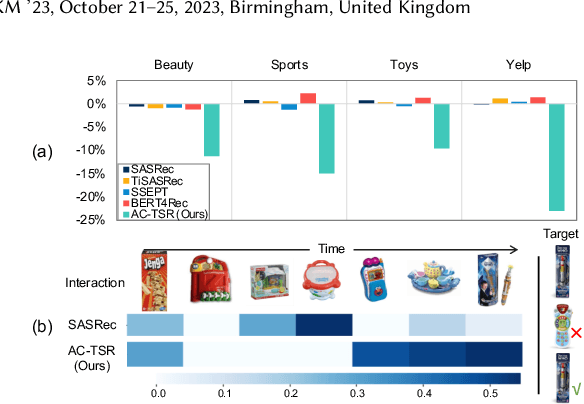
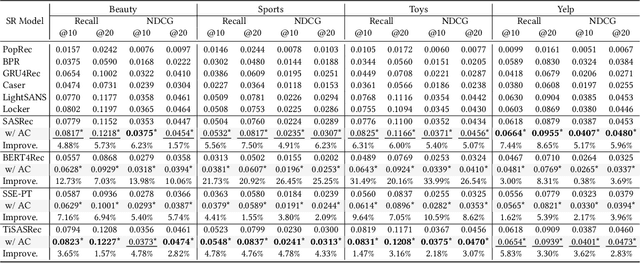
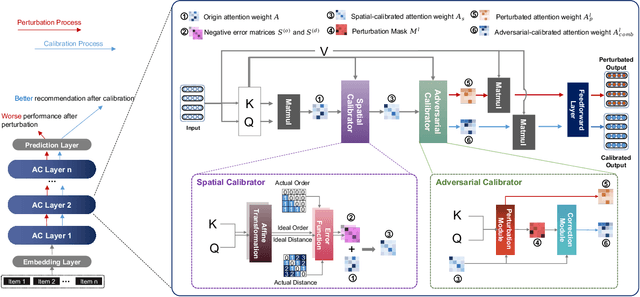
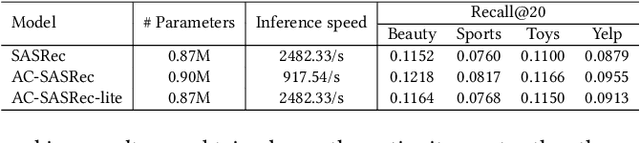
Transformer-based sequential recommendation (SR) has been booming in recent years, with the self-attention mechanism as its key component. Self-attention has been widely believed to be able to effectively select those informative and relevant items from a sequence of interacted items for next-item prediction via learning larger attention weights for these items. However, this may not always be true in reality. Our empirical analysis of some representative Transformer-based SR models reveals that it is not uncommon for large attention weights to be assigned to less relevant items, which can result in inaccurate recommendations. Through further in-depth analysis, we find two factors that may contribute to such inaccurate assignment of attention weights: sub-optimal position encoding and noisy input. To this end, in this paper, we aim to address this significant yet challenging gap in existing works. To be specific, we propose a simple yet effective framework called Attention Calibration for Transformer-based Sequential Recommendation (AC-TSR). In AC-TSR, a novel spatial calibrator and adversarial calibrator are designed respectively to directly calibrates those incorrectly assigned attention weights. The former is devised to explicitly capture the spatial relationships (i.e., order and distance) among items for more precise calculation of attention weights. The latter aims to redistribute the attention weights based on each item's contribution to the next-item prediction. AC-TSR is readily adaptable and can be seamlessly integrated into various existing transformer-based SR models. Extensive experimental results on four benchmark real-world datasets demonstrate the superiority of our proposed ACTSR via significant recommendation performance enhancements. The source code is available at https://github.com/AIM-SE/AC-TSR.