 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Contrastive Learning Necessary? A Study of Data Augmentation vs Contrastive Learning in Sequential Recommendation
Mar 17, 2024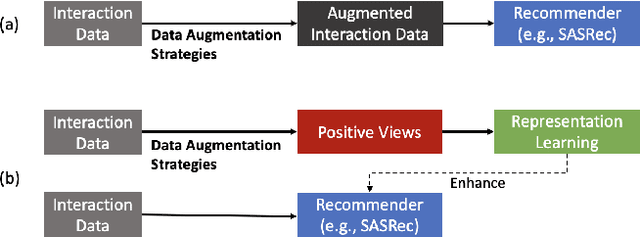
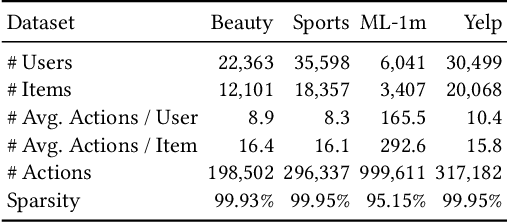
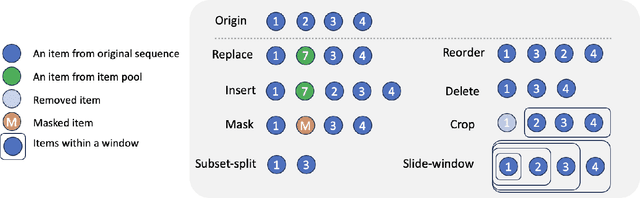
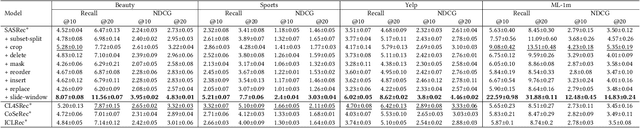
Sequential recommender systems (SRS) are designed to predict users' future behaviors based on their historical interaction data. Recent research has increasingly utilized contrastive learning (CL) to leverage unsupervised signals to alleviate the data sparsity issue in SRS. In general, CL-based SRS first augments the raw sequential interaction data by using data augmentation strategies and employs a contrastive training scheme to enforce the representations of those sequences from the same raw interaction data to be similar. Despite the growing popularity of CL, data augmentation, as a basic component of CL, has not received sufficient attention. This raises the question: Is it possible to achieve superior recommendation results solely through data augmentation? To answer this question, we benchmark eight widely used data augmentation strategies, as well as state-of-the-art CL-based SRS methods, on four real-world datasets under both warm- and cold-start settings. Intriguingly, the conclusion drawn from our study is that, certain data augmentation strategies can achieve similar or even superior performance compared with some CL-based methods, demonstrating the potential to significantly alleviate the data sparsity issue with fewer computational overhead. We hope that our study can further inspire more fundamental studies on the key functional components of complex CL techniques. Our processed datasets and codes are available at https://github.com/AIM-SE/DA4Rec.
Exploring Recommendation Capabilities of GPT-4V(ision): A Preliminary Case Study
Nov 07, 2023



Large Multimodal Models (LMMs) have demonstrated impressive performance across various vision and language tasks, yet their potential applications in recommendation tasks with visual assistance remain unexplored. To bridge this gap, we present a preliminary case study investigating the recommendation capabilities of GPT-4V(ison), a recently released LMM by OpenAI. We construct a series of qualitative test samples spanning multiple domains and employ these samples to assess the quality of GPT-4V's responses within recommendation scenarios. Evaluation results on these test samples prove that GPT-4V has remarkable zero-shot recommendation abilities across diverse domains, thanks to its robust visual-text comprehension capabilities and extensive general knowledge. However, we have also identified some limitations in using GPT-4V for recommendations, including a tendency to provide similar responses when given similar inputs. This report concludes with an in-depth discussion of the challenges and research opportunities associated with utilizing GPT-4V in recommendation scenarios. Our objective is to explore the potential of extending LMMs from vision and language tasks to recommendation tasks. We hope to inspire further research into next-generation multimodal generative recommendation models, which can enhance user experiences by offering greater diversity and interactivity. All images and prompts used in this report will be accessible at https://github.com/PALIN2018/Evaluate_GPT-4V_Rec.