 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Output Rankings in Generative Engines for LLM-based Search
Feb 03, 2026The way customers search for and choose products is changing with the rise of large language models (LLMs). LLM-based search, or generative engines, provides direct product recommendations to users, rather than traditional online search results that require users to explore options themselves. However, these recommendations are strongly influenced by the initial retrieval order of LLMs, which disadvantages small businesses and independent creators by limiting their visibility. In this work, we propose CORE, an optimization method that \textbf{C}ontrols \textbf{O}utput \textbf{R}ankings in g\textbf{E}nerative Engines for LLM-based search. Since the LLM's interactions with the search engine are black-box, CORE targets the content returned by search engines as the primary means of influencing output rankings. Specifically, CORE optimizes retrieved content by appending strategically designed optimization content to steer the ranking of outputs. We introduce three types of optimization content: string-based, reasoning-based, and review-based, demonstrating their effectiveness in shaping output rankings. To evaluate CORE in realistic settings, we introduce ProductBench, a large-scale benchmark with 15 product categories and 200 products per category, where each product is associated with its top-10 recommendations collected from Amazon's search interface. Extensive experiments on four LLMs with search capabilities (GPT-4o, Gemini-2.5, Claude-4, and Grok-3) demonstrate that CORE achieves an average Promotion Success Rate of \textbf{91.4\% @Top-5}, \textbf{86.6\% @Top-3}, and \textbf{80.3\% @Top-1}, across 15 product categories, outperforming existing ranking manipulation methods while preserving the fluency of optimized content.
GuardVal: Dynamic Large Language Model Jailbreak Evaluation for Comprehensive Safety Testing
Jul 10, 2025Jailbreak attacks reveal critical vulnerabilities in Large Language Models (LLMs) by causing them to generate harmful or unethical content. Evaluating these threats is particularly challenging due to the evolving nature of LLMs and the sophistication required in effectively probing their vulnerabilities. Current benchmarks and evaluation methods struggle to fully address these challenges, leaving gaps in the assessment of LLM vulnerabilities. In this paper, we review existing jailbreak evaluation practices and identify three assumed desiderata for an effective jailbreak evaluation protocol. To address these challenges, we introduce GuardVal, a new evaluation protocol that dynamically generates and refines jailbreak prompts based on the defender LLM's state, providing a more accurate assessment of defender LLMs' capacity to handle safety-critical situations. Moreover, we propose a new optimization method that prevents stagnation during prompt refinement, ensuring the generation of increasingly effective jailbreak prompts that expose deeper weaknesses in the defender LLMs. We apply this protocol to a diverse set of models, from Mistral-7b to GPT-4, across 10 safety domains. Our findings highlight distinct behavioral patterns among the models, offering a comprehensive view of their robustness. Furthermore, our evaluation process deepens the understanding of LLM behavior, leading to insights that can inform future research and drive the development of more secure models.
From Hallucinations to Jailbreaks: Rethinking the Vulnerability of Large Foundation Models
May 30, 2025Large foundation models (LFMs) are susceptible to two distinct vulnerabilities: hallucinations and jailbreak attacks. While typically studied in isolation, we observe that defenses targeting one often affect the other, hinting at a deeper connection. We propose a unified theoretical framework that models jailbreaks as token-level optimization and hallucinations as attention-level optimization. Within this framework, we establish two key propositions: (1) \textit{Similar Loss Convergence} - the loss functions for both vulnerabilities converge similarly when optimizing for target-specific outputs; and (2) \textit{Gradient Consistency in Attention Redistribution} - both exhibit consistent gradient behavior driven by shared attention dynamics. We validate these propositions empirically on LLaVA-1.5 and MiniGPT-4, showing consistent optimization trends and aligned gradients. Leveraging this connection, we demonstrate that mitigation techniques for hallucinations can reduce jailbreak success rates, and vice versa. Our findings reveal a shared failure mode in LFMs and suggest that robustness strategies should jointly address both vulnerabilities.
Reasoning Can Hurt the Inductive Abilities of Large Language Models
May 30, 2025Large Language Models (LLMs) have shown remarkable progress across domains, yet their ability to perform inductive reasoning - inferring latent rules from sparse examples - remains limited. It is often assumed that chain-of-thought (CoT) prompting, as used in Large Reasoning Models (LRMs), enhances such reasoning. We investigate this assumption with creating four controlled, diagnostic game-based tasks - chess, Texas Hold'em, dice games, and blackjack - with hidden human-defined rules. We find that CoT reasoning can degrade inductive performance, with LRMs often underperforming their non-reasoning counterparts. To explain this, we present a theoretical framework that reveals how reasoning steps can amplify error through three failure modes: incorrect sub-task decomposition, incorrect sub-task solving, and incorrect final answer summarization. Based on our theoretical and empirical analysis, we introduce structured interventions that adapt CoT generation according to our identified failure types. These interventions improve inductive accuracy without retraining. Our findings suggest that effective (CoT) reasoning depends not only on taking more steps but also on ensuring those steps are well-structured.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
Revolve: Optimizing AI Systems by Tracking Response Evolution in Textual Optimization
Dec 04, 2024



Recent advancements in large language models (LLMs) have significantly enhanced the ability of LLM-based systems to perform complex tasks through natural language processing and tool interaction. However, optimizing these LLM-based systems for specific tasks remains challenging, often requiring manual interventions like prompt engineering and hyperparameter tuning. Existing automatic optimization methods, such as textual feedback-based techniques (e.g., TextGrad), tend to focus on immediate feedback, analogous to using immediate derivatives in traditional numerical gradient descent. However, relying solely on such feedback can be limited when the adjustments made in response to this feedback are either too small or fluctuate irregularly, potentially slowing down or even stalling the optimization process. To overcome these challenges, more adaptive methods are needed, especially in situations where the system's response is evolving slowly or unpredictably. In this paper, we introduce REVOLVE, an optimization method that tracks how "R"esponses "EVOLVE" across iterations in LLM systems. By focusing on the evolution of responses over time, REVOLVE enables more stable and effective optimization by making thoughtful, progressive adjustments at each step. Experimental results demonstrate that REVOLVE outperforms competitive baselines, achieving a 7.8% improvement in prompt optimization, a 20.72% gain in solution refinement, and a 29.17% increase in code optimization. Additionally, REVOLVE converges in fewer iterations, resulting in significant computational savings. These advantages highlight its adaptability and efficiency, positioning REVOLVE as a valuable tool for optimizing LLM-based systems and accelerating the development of next-generation AI technologies. Code is available at: https://github.com/Peiyance/REVOLVE.
When Graph meets Multimodal: Benchmarking on Multimodal Attributed Graphs Learning
Oct 11, 2024



Multimodal attributed graphs (MAGs) are prevalent in various real-world scenarios and generally contain two kinds of knowledge: (a) Attribute knowledge is mainly supported by the attributes of different modalities contained in nodes (entities) themselves, such as texts and images. (b) Topology knowledge, on the other hand, is provided by the complex interactions posed between nodes. The cornerstone of MAG representation learning lies in the seamless integration of multimodal attributes and topology. Recent advancements in Pre-trained Language/Vision models (PLMs/PVMs) and Graph neural networks (GNNs) have facilitated effective learning on MAGs, garnering increased research interest. However, the absence of meaningful benchmark datasets and standardized evaluation procedures for MAG representation learning has impeded progress in this field. In this paper, we propose Multimodal Attribute Graph Benchmark (MAGB)}, a comprehensive and diverse collection of challenging benchmark datasets for MAGs. The MAGB datasets are notably large in scale and encompass a wide range of domains, spanning from e-commerce networks to social networks. In addition to the brand-new datasets, we conduct extensive benchmark experiments over MAGB with various learning paradigms, ranging from GNN-based and PLM-based methods, to explore the necessity and feasibility of integrating multimodal attributes and graph topology. In a nutshell, we provide an overview of the MAG datasets, standardized evaluation procedures, and present baseline experiments. The entire MAGB project is publicly accessible at https://github.com/sktsherlock/ATG.
Towards Graph Prompt Learning: A Survey and Beyond
Aug 26, 2024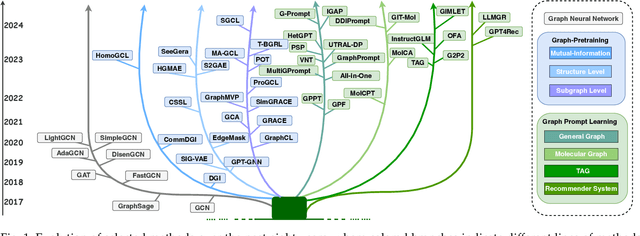
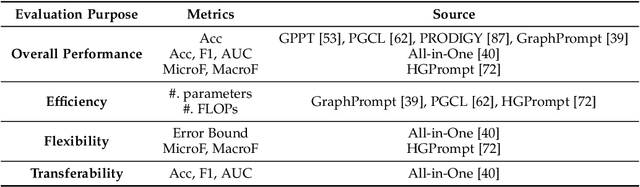
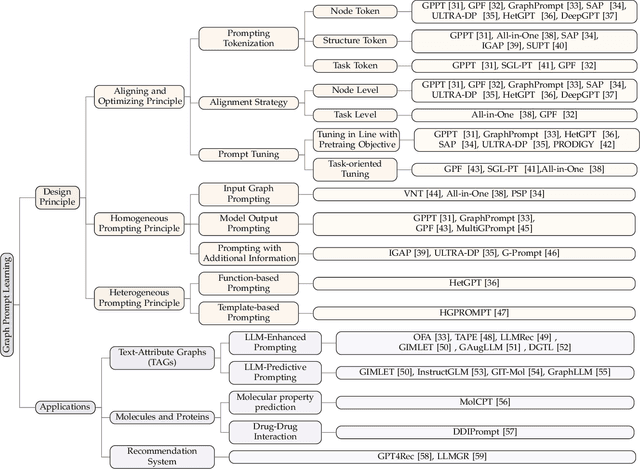
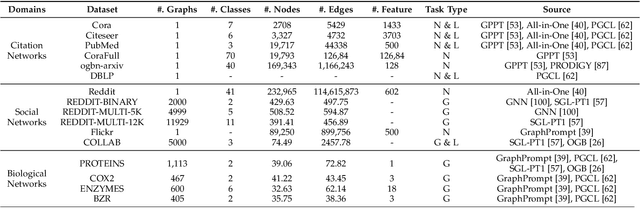
Large-scale "pre-train and prompt learning" paradigms have demonstrated remarkable adaptability, enabling broad applications across diverse domains such as question answering, image recognition, and multimodal retrieval. This approach fully leverages the potential of large-scale pre-trained models, reducing downstream data requirements and computational costs while enhancing model applicability across various tasks. Graphs, as versatile data structures that capture relationships between entities, play pivotal roles in fields such as social network analysis, recommender systems, and biological graphs. Despite the success of pre-train and prompt learning paradigms in Natural Language Processing (NLP) and Computer Vision (CV), their application in graph domains remains nascent. In graph-structured data, not only do the node and edge features often have disparate distributions, but the topological structures also differ significantly. This diversity in graph data can lead to incompatible patterns or gaps between pre-training and fine-tuning on downstream graphs. We aim to bridge this gap by summarizing methods for alleviating these disparities. This includes exploring prompt design methodologies, comparing related techniques, assessing application scenarios and datasets, and identifying unresolved problems and challenges. This survey categorizes over 100 relevant works in this field, summarizing general design principles and the latest applications, including text-attributed graphs, molecules, proteins, and recommendation systems. Through this extensive review, we provide a foundational understanding of graph prompt learning, aiming to impact not only the graph mining community but also the broader Artificial General Intelligence (AGI) community.
JailbreakZoo: Survey, Landscapes, and Horizons in Jailbreaking Large Language and Vision-Language Models
Jun 26, 2024
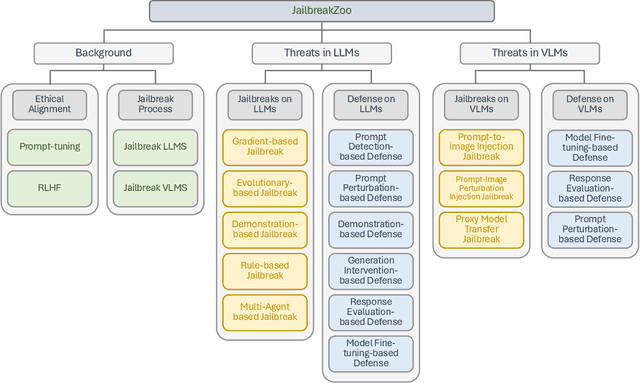
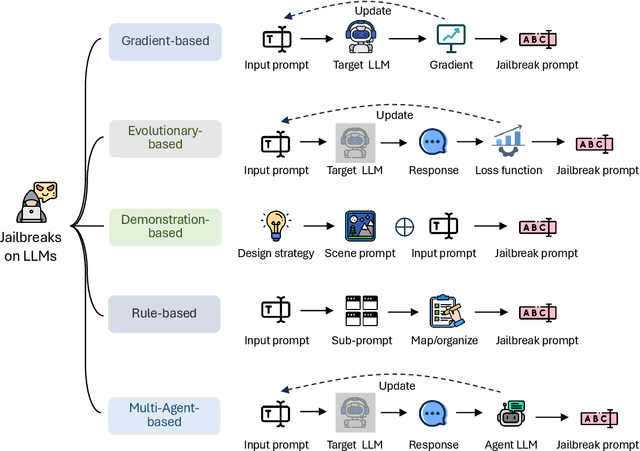
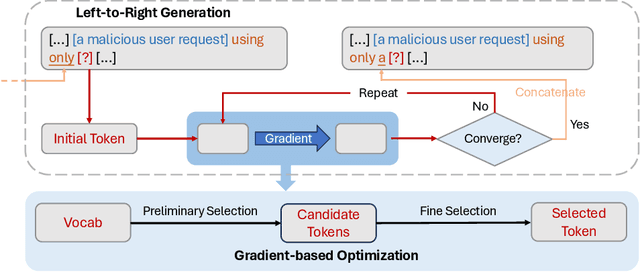
The rapid evolution of artificial intelligence (AI) through developments in Large Language Models (LLMs) and Vision-Language Models (VLMs) has brought significant advancements across various technological domains. While these models enhance capabilities in natural language processing and visual interactive tasks, their growing adoption raises critical concerns regarding security and ethical alignment. This survey provides an extensive review of the emerging field of jailbreaking--deliberately circumventing the ethical and operational boundaries of LLMs and VLMs--and the consequent development of defense mechanisms. Our study categorizes jailbreaks into seven distinct types and elaborates on defense strategies that address these vulnerabilities. Through this comprehensive examination, we identify research gaps and propose directions for future studies to enhance the security frameworks of LLMs and VLMs. Our findings underscore the necessity for a unified perspective that integrates both jailbreak strategies and defensive solutions to foster a robust, secure, and reliable environment for the next generation of language models. More details can be found on our website: \url{https://chonghan-chen.com/llm-jailbreak-zoo-survey/}.
GPT4Rec: Graph Prompt Tuning for Streaming Recommendation
Jun 12, 2024



In the realm of personalized recommender systems, the challenge of adapting to evolving user preferences and the continuous influx of new users and items is paramount. Conventional models, typically reliant on a static training-test approach, struggle to keep pace with these dynamic demands. Streaming recommendation, particularly through continual graph learning, has emerged as a novel solution. However, existing methods in this area either rely on historical data replay, which is increasingly impractical due to stringent data privacy regulations; or are inability to effectively address the over-stability issue; or depend on model-isolation and expansion strategies. To tackle these difficulties, we present GPT4Rec, a Graph Prompt Tuning method for streaming Recommendation. Given the evolving user-item interaction graph, GPT4Rec first disentangles the graph patterns into multiple views. After isolating specific interaction patterns and relationships in different views, GPT4Rec utilizes lightweight graph prompts to efficiently guide the model across varying interaction patterns within the user-item graph. Firstly, node-level prompts are employed to instruct the model to adapt to changes in the attributes or properties of individual nodes within the graph. Secondly, structure-level prompts guide the model in adapting to broader patterns of connectivity and relationships within the graph. Finally, view-level prompts are innovatively designed to facilitate the aggregation of information from multiple disentangled views. These prompt designs allow GPT4Rec to synthesize a comprehensive understanding of the graph, ensuring that all vital aspects of the user-item interactions are considered and effectively integrated. Experiments on four diverse real-world datasets demonstrate the effectiveness and efficiency of our proposal.