 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pixels: Exploring Human-Readable SVG Generation for Simple Images with Vision Language Models
Paper and Code
Nov 27, 2023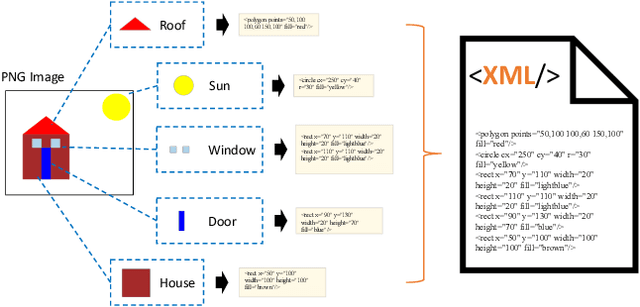
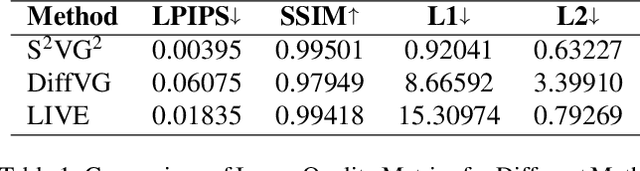
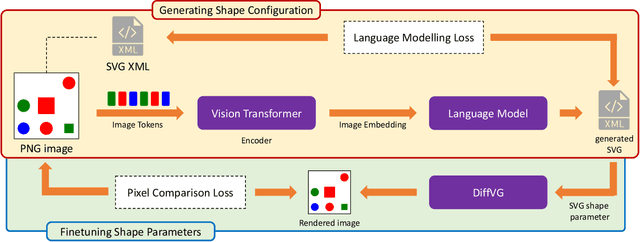
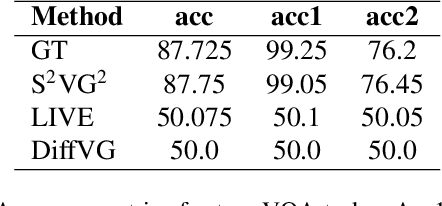
In the field of computer graphics, the use of vector graphics, particularly Scalable Vector Graphics (SVG), represents a notable development from traditional pixel-based imagery. SVGs, with their XML-based format, are distinct in their ability to directly and explicitly represent visual elements such as shape, color, and path. This direct representation facilitates a more accurate and logical depiction of graphical elements, enhancing reasoning and interpretability. Recognizing the potential of SVGs, the machine learning community has introduced multiple methods for image vectorization. However, transforming images into SVG format while retaining the relational properties and context of the original scene remains a key challenge. Most vectorization methods often yield SVGs that are overly complex and not easily interpretable. In response to this challenge, we introduce our method, Simple-SVG-Generation (S\textsuperscript{2}VG\textsuperscript{2}). Our method focuses on producing SVGs that are both accurate and simple, aligning with human readability and understanding. With simple images, we evaluate our method with reasoning tasks together with advanced language models, the results show a clear improvement over previous SVG generation methods. We also conducted surveys for human evaluation on the readability of our generated SVGs, the results also favor our methods.