 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreakZoo: Survey, Landscapes, and Horizons in Jailbreaking Large Language and Vision-Language Models
Paper and Code

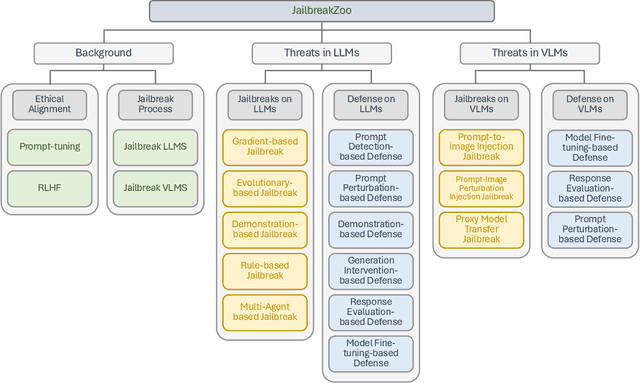
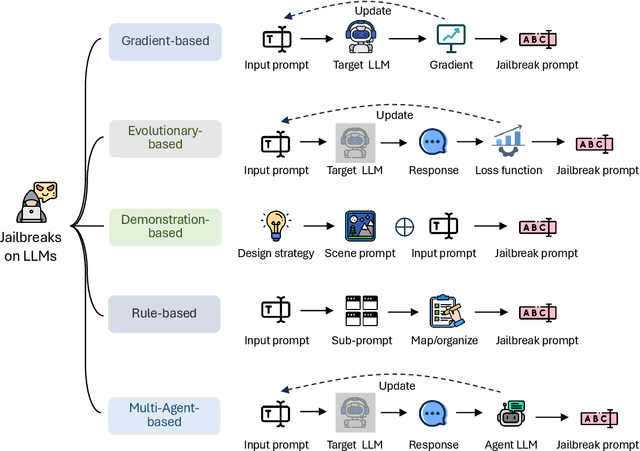
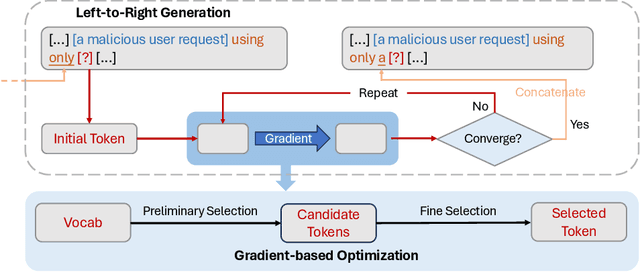
The rapid evolution of artificial intelligence (AI) through developments in Large Language Models (LLMs) and Vision-Language Models (VLMs) has brought significant advancements across various technological domains. While these models enhance capabilities in natural language processing and visual interactive tasks, their growing adoption raises critical concerns regarding security and ethical alignment. This survey provides an extensive review of the emerging field of jailbreaking--deliberately circumventing the ethical and operational boundaries of LLMs and VLMs--and the consequent development of defense mechanisms. Our study categorizes jailbreaks into seven distinct types and elaborates on defense strategies that address these vulnerabilities. Through this comprehensive examination, we identify research gaps and propose directions for future studies to enhance the security frameworks of LLMs and VLMs. Our findings underscore the necessity for a unified perspective that integrates both jailbreak strategies and defensive solutions to foster a robust, secure, and reliable environment for the next generation of language models. More details can be found on our website: \url{https://chonghan-chen.com/llm-jailbreak-zoo-survey/}.