 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext Token Perception Score: Analytical Assessment of your LLM Perception Skills
May 22, 2025Autoregressive pretraining has become the de facto paradigm for learning general-purpose representations in large language models (LLMs). However, linear probe performance across downstream perception tasks shows substantial variability, suggesting that features optimized for next-token prediction do not consistently transfer well to downstream perception tasks. We demonstrate that representations learned via autoregression capture features that may lie outside the subspaces most informative for perception. To quantify the (mis)alignment between autoregressive pretraining and downstream perception, we introduce the Next Token Perception Score (NTPS)-a score derived under a linear setting that measures the overlap between autoregressive and perception feature subspaces. This metric can be easily computed in closed form from pretrained representations and labeled data, and is proven to both upper- and lower-bound the excess loss. Empirically, we show that NTPS correlates strongly with linear probe accuracy across 12 diverse NLP datasets and eight pretrained models ranging from 270M to 8B parameters, confirming its utility as a measure of alignment. Furthermore, we show that NTPS increases following low-rank adaptation (LoRA) fine-tuning, especially in large models, suggesting that LoRA aligning representations to perception tasks enhances subspace overlap and thus improves downstream performance. More importantly, we find that NTPS reliably predicts the additional accuracy gains attained by LoRA finetuning thereby providing a lightweight prescreening tool for LoRA adaptation. Our results offer both theoretical insights and practical tools for analytically assessing LLM perception skills.
Curvature Tuning: Provable Training-free Model Steering From a Single Parameter
Feb 11, 2025

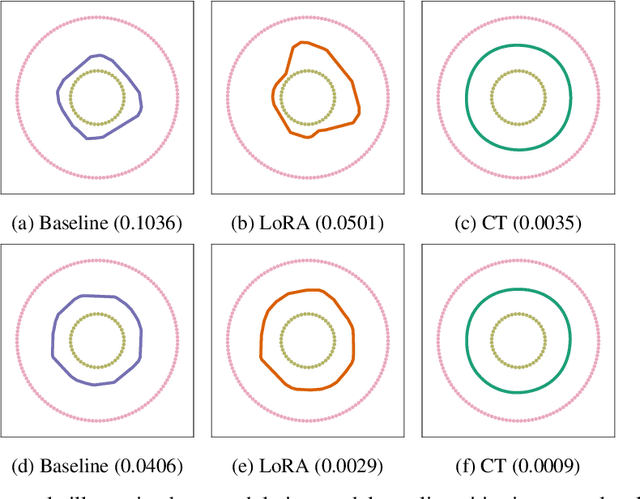

The scaling of model size and data size has reshaped the paradigm of AI. As a result, the common protocol to leverage the latest models is to steer them towards a specific downstream task of interest through {\em fine-tuning}. Despite its importance, the main methods for fine-tuning remain limited to full or low-rank adapters--containing countless hyper-parameters and lacking interpretability. In this paper, we take a step back and demonstrate how novel and explainable post-training steering solutions can be derived theoretically from {\em spline operators}, a rich mathematical framing of Deep Networks that was recently developed. Our method--coined \textbf{Curvature Tuning (CT)}--has a single parameter that provably modulates the curvature of the model's decision boundary henceforth allowing training-free steering. This makes CT both more efficient and interpretable than conventional fine-tuning methods. We empirically validate its effectiveness in improving generalization and robustness of pretrained models. For example, CT improves out-of-distribution transfer performances of ResNet-18/50 by 2.57\%/1.74\% across seventeen downstream datasets, and improves RobustBench robust accuracy by 11.76\%/348.44\%. Additionally, we apply CT to ReLU-based Swin-T/S, improving their generalization on nine downstream datasets by 2.43\%/3.33\%. Our code is available at \href{https://github.com/Leon-Leyang/curvature-tuning}{https://github.com/Leon-Leyang/curvature-tuning}.
Revolve: Optimizing AI Systems by Tracking Response Evolution in Textual Optimization
Dec 04, 2024



Recent advancements in large language models (LLMs) have significantly enhanced the ability of LLM-based systems to perform complex tasks through natural language processing and tool interaction. However, optimizing these LLM-based systems for specific tasks remains challenging, often requiring manual interventions like prompt engineering and hyperparameter tuning. Existing automatic optimization methods, such as textual feedback-based techniques (e.g., TextGrad), tend to focus on immediate feedback, analogous to using immediate derivatives in traditional numerical gradient descent. However, relying solely on such feedback can be limited when the adjustments made in response to this feedback are either too small or fluctuate irregularly, potentially slowing down or even stalling the optimization process. To overcome these challenges, more adaptive methods are needed, especially in situations where the system's response is evolving slowly or unpredictably. In this paper, we introduce REVOLVE, an optimization method that tracks how "R"esponses "EVOLVE" across iterations in LLM systems. By focusing on the evolution of responses over time, REVOLVE enables more stable and effective optimization by making thoughtful, progressive adjustments at each step. Experimental results demonstrate that REVOLVE outperforms competitive baselines, achieving a 7.8% improvement in prompt optimization, a 20.72% gain in solution refinement, and a 29.17% increase in code optimization. Additionally, REVOLVE converges in fewer iterations, resulting in significant computational savings. These advantages highlight its adaptability and efficiency, positioning REVOLVE as a valuable tool for optimizing LLM-based systems and accelerating the development of next-generation AI technologies. Code is available at: https://github.com/Peiyance/REVOLVE.
DROJ: A Prompt-Driven Attack against Large Language Models
Nov 14, 2024



Large Language Models (LLMs) have demonstrated exceptional capabilities across various natural language processing tasks. Due to their training on internet-sourced datasets, LLMs can sometimes generate objectionable content, necessitating extensive alignment with human feedback to avoid such outputs. Despite massive alignment efforts, LLMs remain susceptible to adversarial jailbreak attacks, which usually are manipulated prompts designed to circumvent safety mechanisms and elicit harmful responses. Here, we introduce a novel approach, Directed Rrepresentation Optimization Jailbreak (DROJ), which optimizes jailbreak prompts at the embedding level to shift the hidden representations of harmful queries towards directions that are more likely to elicit affirmative responses from the model. Our evaluations on LLaMA-2-7b-chat model show that DROJ achieves a 100\% keyword-based Attack Success Rate (ASR), effectively preventing direct refusals. However, the model occasionally produces repetitive and non-informative responses. To mitigate this, we introduce a helpfulness system prompt that enhances the utility of the model's responses. Our code is available at https://github.com/Leon-Leyang/LLM-Safeguard.
JailbreakZoo: Survey, Landscapes, and Horizons in Jailbreaking Large Language and Vision-Language Models
Jun 26, 2024
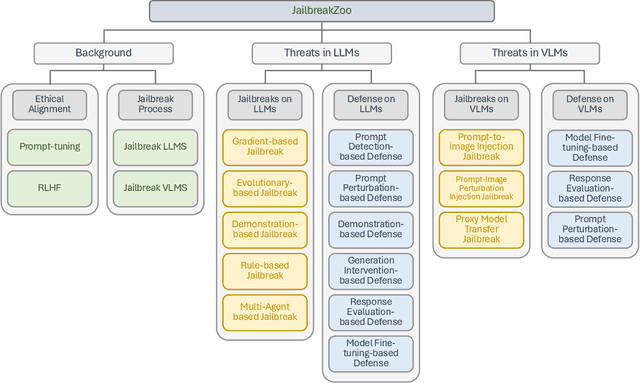
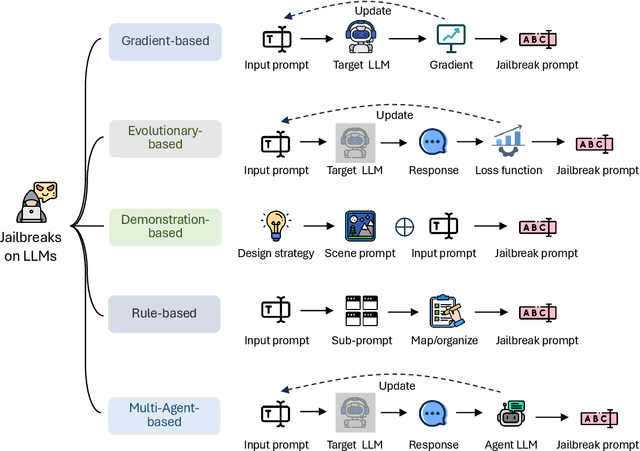
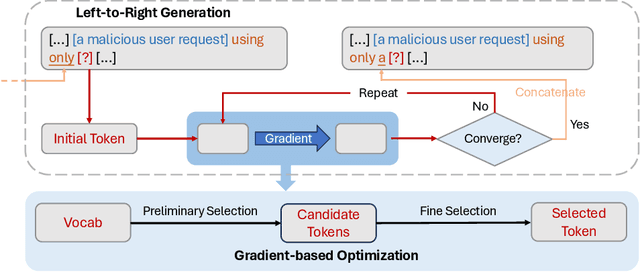
The rapid evolution of artificial intelligence (AI) through developments in Large Language Models (LLMs) and Vision-Language Models (VLMs) has brought significant advancements across various technological domains. While these models enhance capabilities in natural language processing and visual interactive tasks, their growing adoption raises critical concerns regarding security and ethical alignment. This survey provides an extensive review of the emerging field of jailbreaking--deliberately circumventing the ethical and operational boundaries of LLMs and VLMs--and the consequent development of defense mechanisms. Our study categorizes jailbreaks into seven distinct types and elaborates on defense strategies that address these vulnerabilities. Through this comprehensive examination, we identify research gaps and propose directions for future studies to enhance the security frameworks of LLMs and VLMs. Our findings underscore the necessity for a unified perspective that integrates both jailbreak strategies and defensive solutions to foster a robust, secure, and reliable environment for the next generation of language models. More details can be found on our website: \url{https://chonghan-chen.com/llm-jailbreak-zoo-survey/}.
Robustar: Interactive Toolbox Supporting Precise Data Annotation for Robust Vision Learning
Jul 18, 2022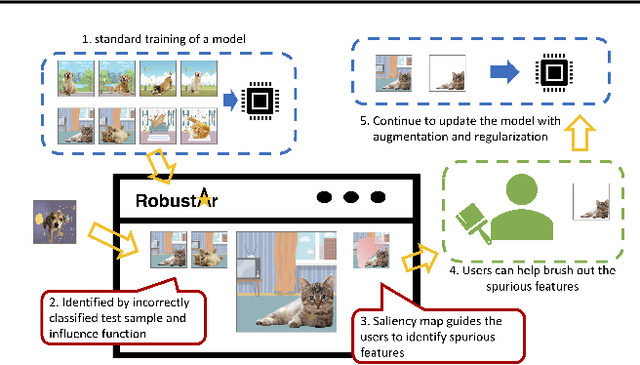
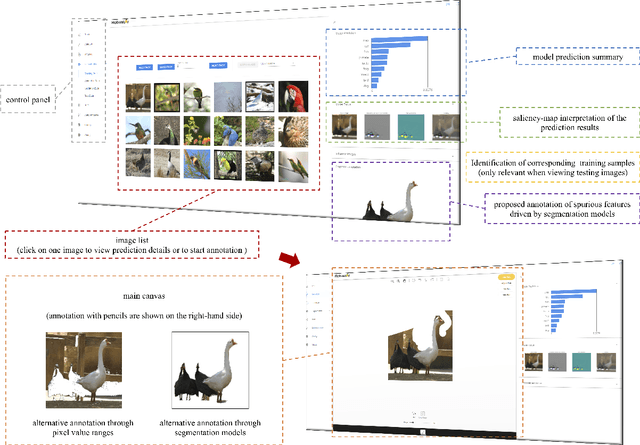
We introduce the initial release of our software Robustar, which aims to improve the robustness of vision classification machine learning models through a data-driven perspective. Building upon the recent understanding that the lack of machine learning model's robustness is the tendency of the model's learning of spurious features, we aim to solve this problem from its root at the data perspective by removing the spurious features from the data before training. In particular, we introduce a software that helps the users to better prepare the data for training image classification models by allowing the users to annotate the spurious features at the pixel level of images. To facilitate this process, our software also leverages recent advances to help identify potential images and pixels worthy of attention and to continue the training with newly annotated data. Our software is hosted at the GitHub Repository https://github.com/HaohanWang/Robustar.