 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustar: Interactive Toolbox Supporting Precise Data Annotation for Robust Vision Learning
Jul 18, 2022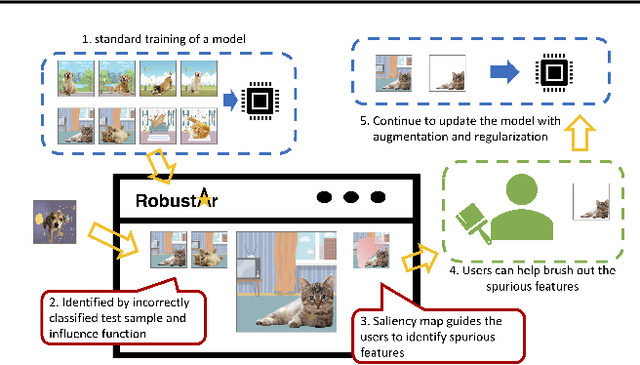
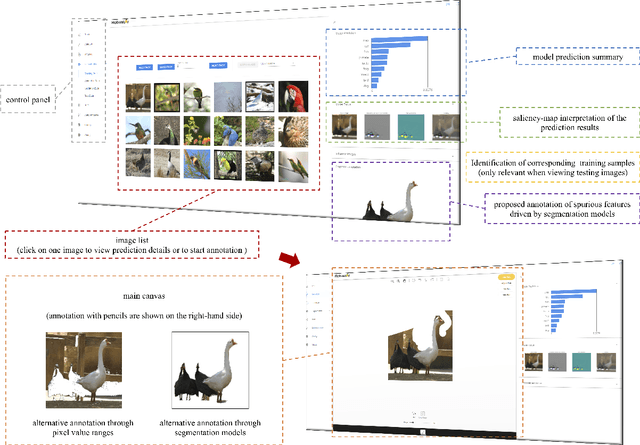
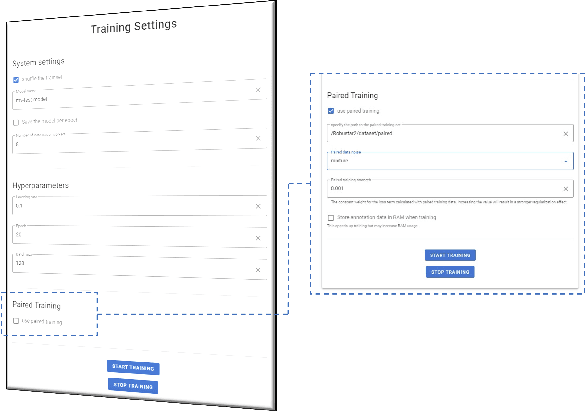
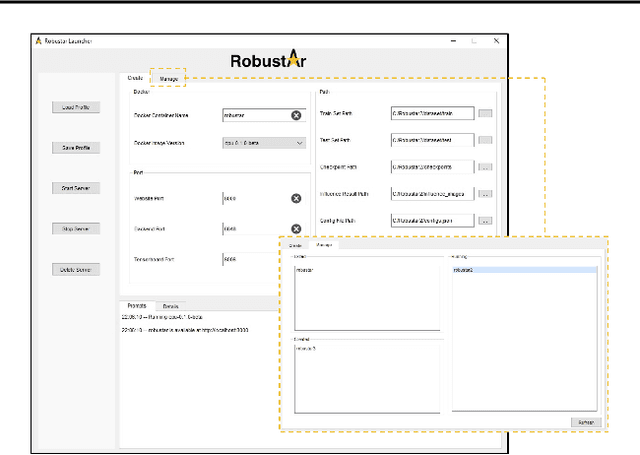
We introduce the initial release of our software Robustar, which aims to improve the robustness of vision classification machine learning models through a data-driven perspective. Building upon the recent understanding that the lack of machine learning model's robustness is the tendency of the model's learning of spurious features, we aim to solve this problem from its root at the data perspective by removing the spurious features from the data before training. In particular, we introduce a software that helps the users to better prepare the data for training image classification models by allowing the users to annotate the spurious features at the pixel level of images. To facilitate this process, our software also leverages recent advances to help identify potential images and pixels worthy of attention and to continue the training with newly annotated data. Our software is hosted at the GitHub Repository https://github.com/HaohanWang/Robustar.