 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreakZoo: Survey, Landscapes, and Horizons in Jailbreaking Large Language and Vision-Language Models
Jun 26, 2024
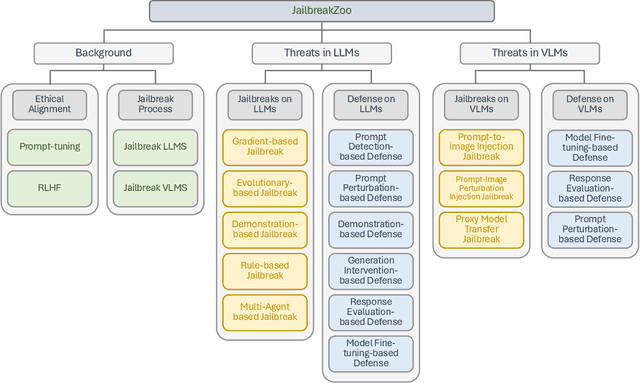
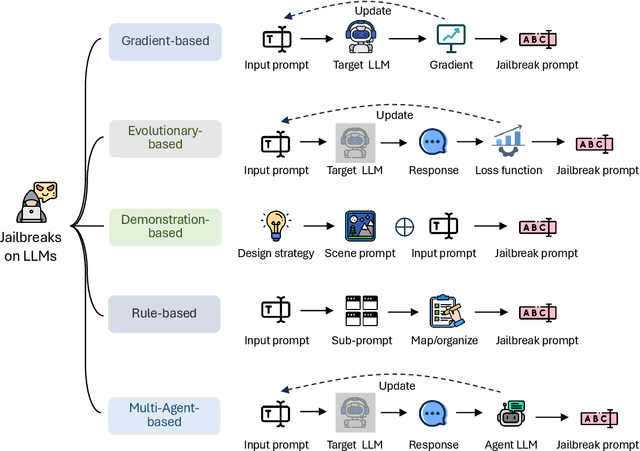
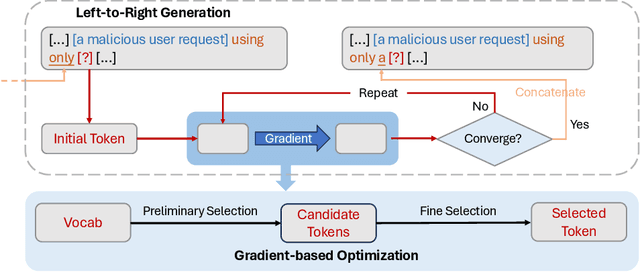
The rapid evolution of artificial intelligence (AI) through developments in Large Language Models (LLMs) and Vision-Language Models (VLMs) has brought significant advancements across various technological domains. While these models enhance capabilities in natural language processing and visual interactive tasks, their growing adoption raises critical concerns regarding security and ethical alignment. This survey provides an extensive review of the emerging field of jailbreaking--deliberately circumventing the ethical and operational boundaries of LLMs and VLMs--and the consequent development of defense mechanisms. Our study categorizes jailbreaks into seven distinct types and elaborates on defense strategies that address these vulnerabilities. Through this comprehensive examination, we identify research gaps and propose directions for future studies to enhance the security frameworks of LLMs and VLMs. Our findings underscore the necessity for a unified perspective that integrates both jailbreak strategies and defensive solutions to foster a robust, secure, and reliable environment for the next generation of language models. More details can be found on our website: \url{https://chonghan-chen.com/llm-jailbreak-zoo-survey/}.
Robustar: Interactive Toolbox Supporting Precise Data Annotation for Robust Vision Learning
Jul 18, 2022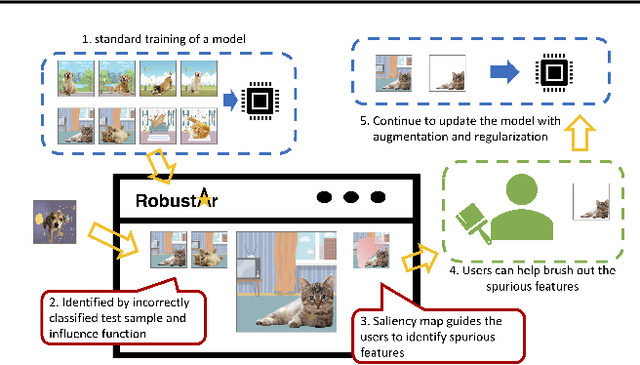
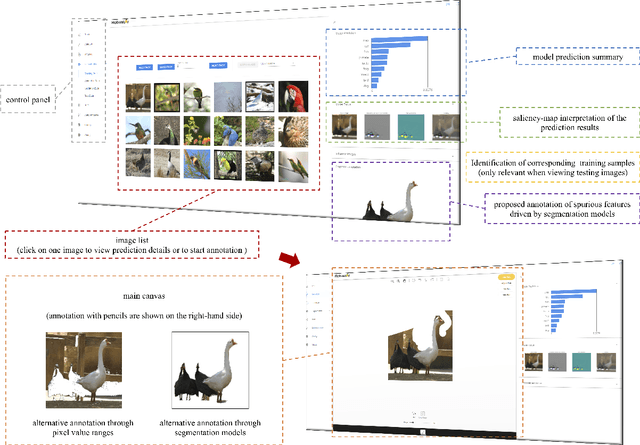
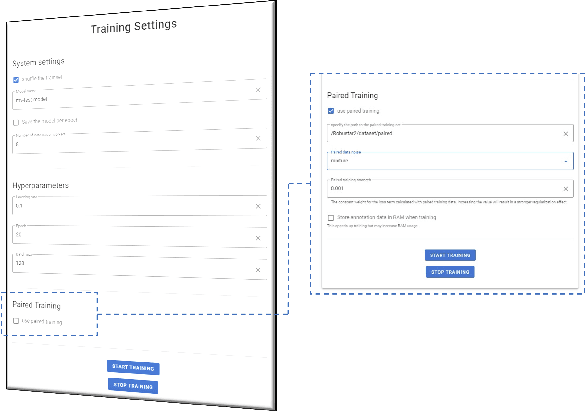
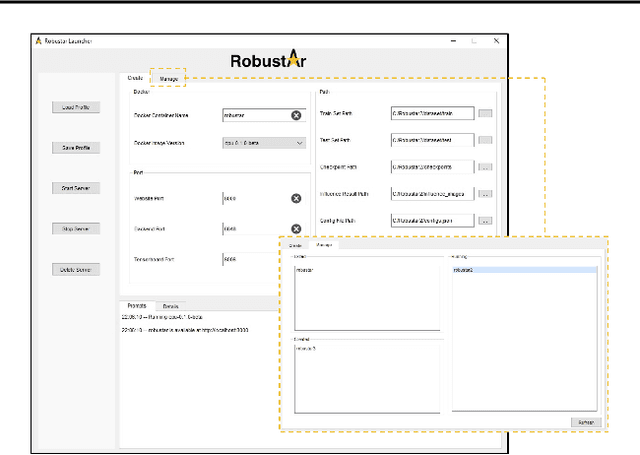
We introduce the initial release of our software Robustar, which aims to improve the robustness of vision classification machine learning models through a data-driven perspective. Building upon the recent understanding that the lack of machine learning model's robustness is the tendency of the model's learning of spurious features, we aim to solve this problem from its root at the data perspective by removing the spurious features from the data before training. In particular, we introduce a software that helps the users to better prepare the data for training image classification models by allowing the users to annotate the spurious features at the pixel level of images. To facilitate this process, our software also leverages recent advances to help identify potential images and pixels worthy of attention and to continue the training with newly annotated data. Our software is hosted at the GitHub Repository https://github.com/HaohanWang/Robustar.
Bear the Query in Mind: Visual Grounding with Query-conditioned Convolution
Jun 22, 2022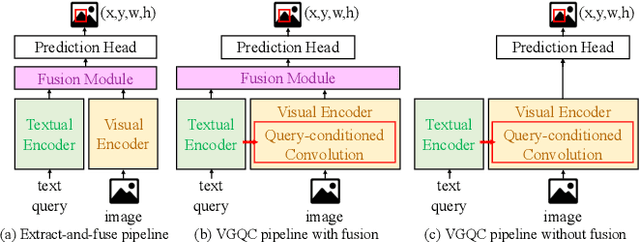
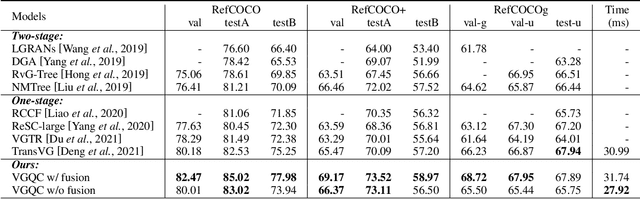
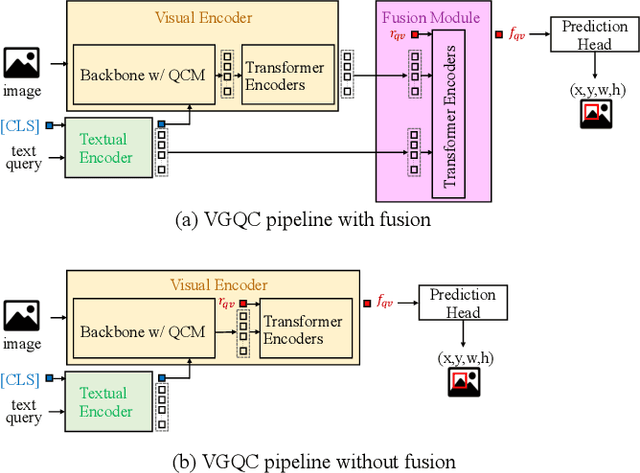
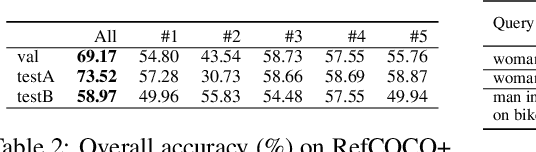
Visual grounding is a task that aims to locate a target object according to a natural language expression. As a multi-modal task, feature interaction between textual and visual inputs is vital. However, previous solutions mainly handle each modality independently before fusing them together, which does not take full advantage of relevant textual information while extracting visual features. To better leverage the textual-visual relationship in visual grounding, we propose a Query-conditioned Convolution Module (QCM) that extracts query-aware visual features by incorporating query information into the generation of convolutional kernels. With our proposed QCM, the downstream fusion module receives visual features that are more discriminative and focused on the desired object described in the expression, leading to more accurate predictions. Extensive experiments on three popular visual grounding datasets demonstrate that our method achieves state-of-the-art performance. In addition, the query-aware visual features are informative enough to achieve comparable performance to the latest methods when directly used for prediction without further multi-modal fusion.