 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBear the Query in Mind: Visual Grounding with Query-conditioned Convolution
Paper and Code
Jun 22, 2022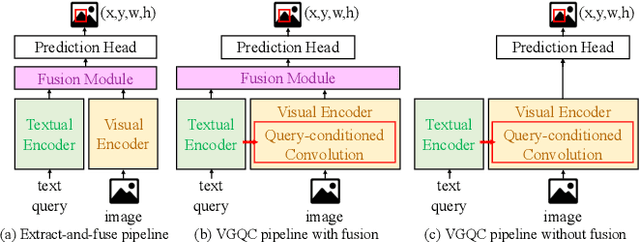
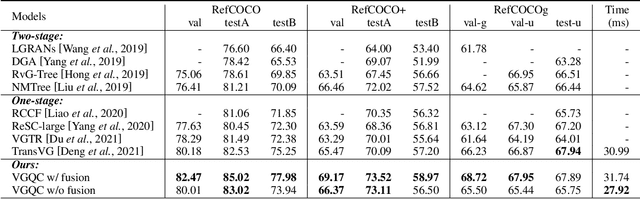
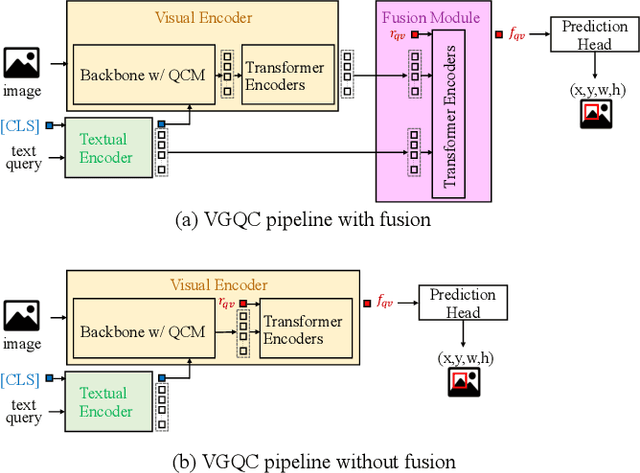
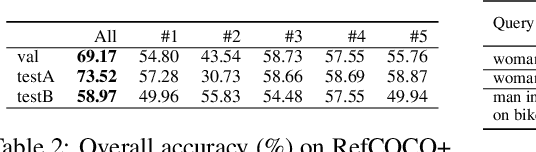
Visual grounding is a task that aims to locate a target object according to a natural language expression. As a multi-modal task, feature interaction between textual and visual inputs is vital. However, previous solutions mainly handle each modality independently before fusing them together, which does not take full advantage of relevant textual information while extracting visual features. To better leverage the textual-visual relationship in visual grounding, we propose a Query-conditioned Convolution Module (QCM) that extracts query-aware visual features by incorporating query information into the generation of convolutional kernels. With our proposed QCM, the downstream fusion module receives visual features that are more discriminative and focused on the desired object described in the expression, leading to more accurate predictions. Extensive experiments on three popular visual grounding datasets demonstrate that our method achieves state-of-the-art performance. In addition, the query-aware visual features are informative enough to achieve comparable performance to the latest methods when directly used for prediction without further multi-modal fusion.