 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBear the Query in Mind: Visual Grounding with Query-conditioned Convolution
Jun 22, 2022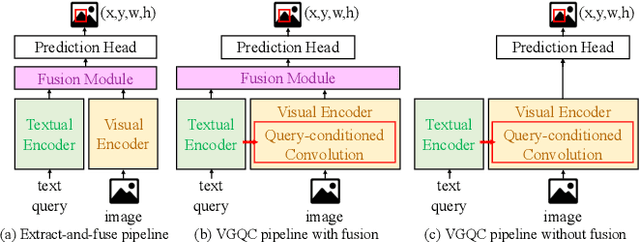
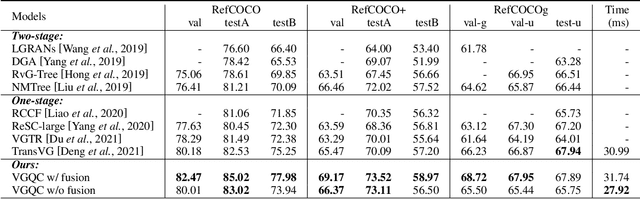
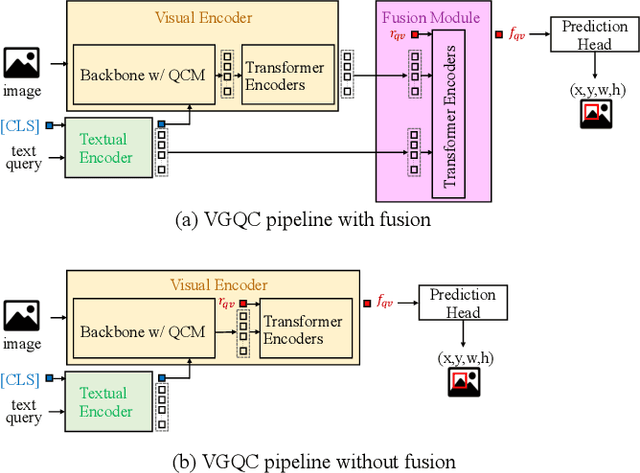
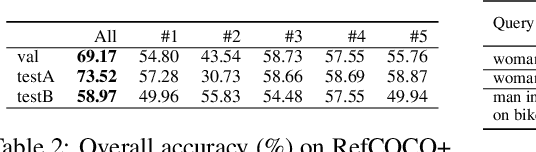
Visual grounding is a task that aims to locate a target object according to a natural language expression. As a multi-modal task, feature interaction between textual and visual inputs is vital. However, previous solutions mainly handle each modality independently before fusing them together, which does not take full advantage of relevant textual information while extracting visual features. To better leverage the textual-visual relationship in visual grounding, we propose a Query-conditioned Convolution Module (QCM) that extracts query-aware visual features by incorporating query information into the generation of convolutional kernels. With our proposed QCM, the downstream fusion module receives visual features that are more discriminative and focused on the desired object described in the expression, leading to more accurate predictions. Extensive experiments on three popular visual grounding datasets demonstrate that our method achieves state-of-the-art performance. In addition, the query-aware visual features are informative enough to achieve comparable performance to the latest methods when directly used for prediction without further multi-modal fusion.
RSL19BD at DBDC4: Ensemble of Decision Tree-based and LSTM-based Models
May 11, 2019
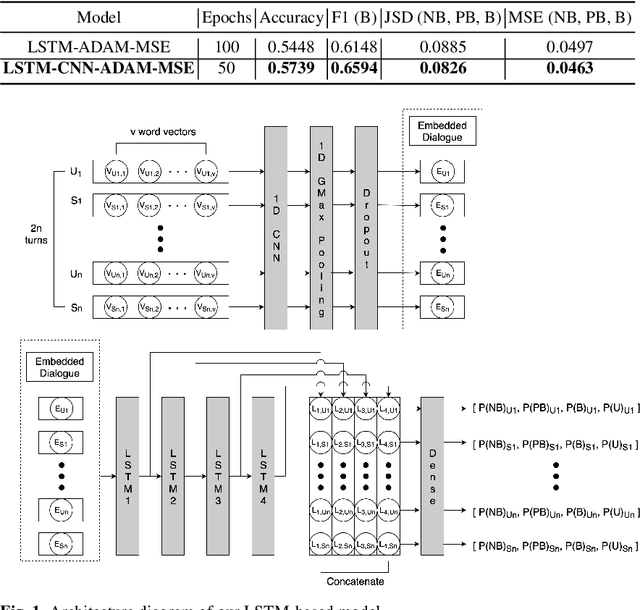

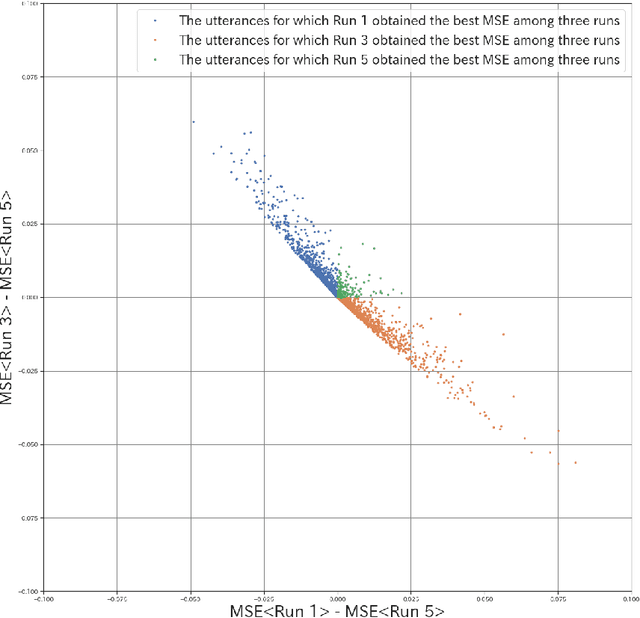
RSL19BD (Waseda University Sakai Laboratory) participated in the Fourth Dialogue Breakdown Detection Challenge (DBDC4) and submitted five runs to both English and Japanese subtasks. In these runs, we utilise the Decision Tree-based model and the Long Short-Term Memory-based (LSTM-based) model following the approaches of RSL17BD and KTH in the Third Dialogue Breakdown Detection Challenge (DBDC3) respectively. The Decision Tree-based model follows the approach of RSL17BD but utilises RandomForestRegressor instead of ExtraTreesRegressor. In addition, instead of predicting the mean and the variance of the probability distribution of the three breakdown labels, it predicts the probability of each label directly. The LSTM-based model follows the approach of KTH with some changes in the architecture and utilises Convolutional Neural Network (CNN) to perform text feature extraction. In addition, instead of targeting the single breakdown label and minimising the categorical cross entropy loss, it targets the probability distribution of the three breakdown labels and minimises the mean squared error. Run 1 utilises a Decision Tree-based model; Run 2 utilises an LSTM-based model; Run 3 performs an ensemble of 5 LSTM-based models; Run 4 performs an ensemble of Run 1 and Run 2; Run 5 performs an ensemble of Run 1 and Run 3. Run 5 statistically significantly outperformed all other runs in terms of MSE (NB, PB, B) for the English data and all other runs except Run 4 in terms of MSE (NB, PB, B) for the Japanese data (alpha level = 0.05).