 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCG-MLLM: Captioning and Generating 3D content via Multi-modal Large Language Models
Jan 29, 2026Large Language Models(LLMs) have revolutionized text generation and multimodal perception, but their capabilities in 3D content generation remain underexplored. Existing methods compromise by producing either low-resolution meshes or coarse structural proxies, failing to capture fine-grained geometry natively. In this paper, we propose CG-MLLM, a novel Multi-modal Large Language Model (MLLM) capable of 3D captioning and high-resolution 3D generation in a single framework. Leveraging the Mixture-of-Transformer architecture, CG-MLLM decouples disparate modeling needs, where the Token-level Autoregressive (TokenAR) Transformer handles token-level content, and the Block-level Autoregressive (BlockAR) Transformer handles block-level content. By integrating a pre-trained vision-language backbone with a specialized 3D VAE latent space, CG-MLLM facilitates long-context interactions between standard tokens and spatial blocks within a single integrated architecture. Experimental results show that CG-MLLM significantly outperforms existing MLLMs in generating high-fidelity 3D objects, effectively bringing high-resolution 3D content creation into the mainstream LLM paradigm.
Lean4Physics: Comprehensive Reasoning Framework for College-level Physics in Lean4
Oct 30, 2025We present **Lean4PHYS**, a comprehensive reasoning framework for college-level physics problems in Lean4. **Lean4PHYS** includes *LeanPhysBench*, a college-level benchmark for formal physics reasoning in Lean4, which contains 200 hand-crafted and peer-reviewed statements derived from university textbooks and physics competition problems. To establish a solid foundation for formal reasoning in physics, we also introduce *PhysLib*, a community-driven repository containing fundamental unit systems and theorems essential for formal physics reasoning. Based on the benchmark and Lean4 repository we composed in **Lean4PHYS**, we report baseline results using major expert Math Lean4 provers and state-of-the-art closed-source models, with the best performance of DeepSeek-Prover-V2-7B achieving only 16% and Claude-Sonnet-4 achieving 35%. We also conduct a detailed analysis showing that our *PhysLib* can achieve an average improvement of 11.75% in model performance. This demonstrates the challenging nature of our *LeanPhysBench* and the effectiveness of *PhysLib*. To the best of our knowledge, this is the first study to provide a physics benchmark in Lean4.
Is GPT-OSS Good? A Comprehensive Evaluation of OpenAI's Latest Open Source Models
Aug 17, 2025



In August 2025, OpenAI released GPT-OSS models, its first open weight large language models since GPT-2 in 2019, comprising two mixture of experts architectures with 120B and 20B parameters. We evaluated both variants against six contemporary open source large language models ranging from 14.7B to 235B parameters, representing both dense and sparse designs, across ten benchmarks covering general knowledge, mathematical reasoning, code generation, multilingual understanding, and conversational ability. All models were tested in unquantised form under standardised inference settings, with statistical validation using McNemars test and effect size analysis. Results show that gpt-oss-20B consistently outperforms gpt-oss-120B on several benchmarks, such as HumanEval and MMLU, despite requiring substantially less memory and energy per response. Both models demonstrate mid-tier overall performance within the current open source landscape, with relative strength in code generation and notable weaknesses in multilingual tasks. These findings provide empirical evidence that scaling in sparse architectures may not yield proportional performance gains, underscoring the need for further investigation into optimisation strategies and informing more efficient model selection for future open source deployments.
Uncovering inequalities in new knowledge learning by large language models across different languages
Mar 06, 2025As large language models (LLMs) gradually become integral tools for problem solving in daily life worldwide, understanding linguistic inequality is becoming increasingly important. Existing research has primarily focused on static analyses that assess the disparities in the existing knowledge and capabilities of LLMs across languages. However, LLMs are continuously evolving, acquiring new knowledge to generate up-to-date, domain-specific responses. Investigating linguistic inequalities within this dynamic process is, therefore, also essential. In this paper, we explore inequalities in new knowledge learning by LLMs across different languages and four key dimensions: effectiveness, transferability, prioritization, and robustness. Through extensive experiments under two settings (in-context learning and fine-tuning) using both proprietary and open-source models, we demonstrate that low-resource languages consistently face disadvantages across all four dimensions. By shedding light on these disparities, we aim to raise awareness of linguistic inequalities in LLMs' new knowledge learning, fostering the development of more inclusive and equitable future LLMs.
A Recommendation Model Utilizing Separation Embedding and Self-Attention for Feature Mining
Oct 19, 2024



With the explosive growth of Internet data, users are facing the problem of information overload, which makes it a challenge to efficiently obtain the required resources. Recommendation systems have emerged in this context. By filtering massive amounts of information, they provide users with content that meets their needs, playing a key role in scenarios such as advertising recommendation and product recommendation. However, traditional click-through rate prediction and TOP-K recommendation mechanisms are gradually unable to meet the recommendations needs in modern life scenarios due to high computational complexity, large memory consumption, long feature selection time, and insufficient feature interaction. This paper proposes a recommendations system model based on a separation embedding cross-network. The model uses an embedding neural network layer to transform sparse feature vectors into dense embedding vectors, and can independently perform feature cross operations on different dimensions, thereby improving the accuracy and depth of feature mining. Experimental results show that the model shows stronger adaptability and higher prediction accuracy in processing complex data sets, effectively solving the problems existing in existing models.
Integration of Mamba and Transformer -- MAT for Long-Short Range Time Series Forecasting with Application to Weather Dynamics
Sep 13, 2024
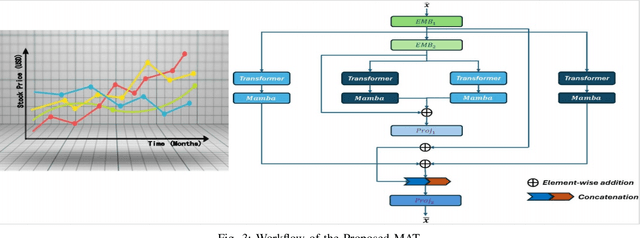
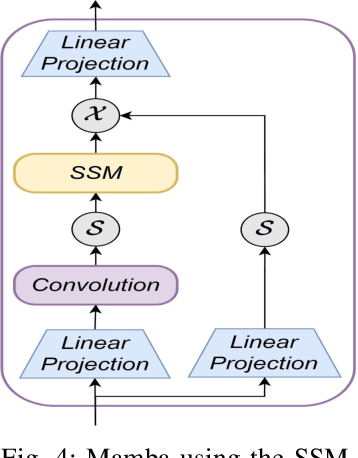
Long-short range time series forecasting is essential for predicting future trends and patterns over extended periods. While deep learning models such as Transformers have made significant strides in advancing time series forecasting, they often encounter difficulties in capturing long-term dependencies and effectively managing sparse semantic features. The state-space model, Mamba, addresses these issues through its adept handling of selective input and parallel computing, striking a balance between computational efficiency and prediction accuracy. This article examines the advantages and disadvantages of both Mamba and Transformer models, and introduces a combined approach, MAT, which leverages the strengths of each model to capture unique long-short range dependencies and inherent evolutionary patterns in multivariate time series. Specifically, MAT harnesses the long-range dependency capabilities of Mamba and the short-range characteristics of Transformers. Experimental results on benchmark weather datasets demonstrate that MAT outperforms existing comparable methods in terms of prediction accuracy, scalability, and memory efficiency.
Measuring Human Contribution in AI-Assisted Content Generation
Aug 27, 2024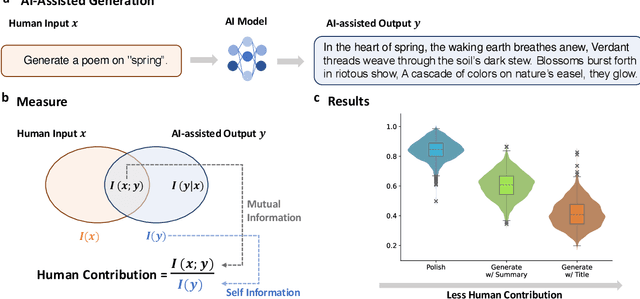

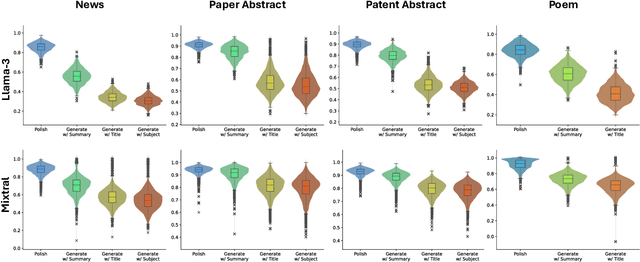
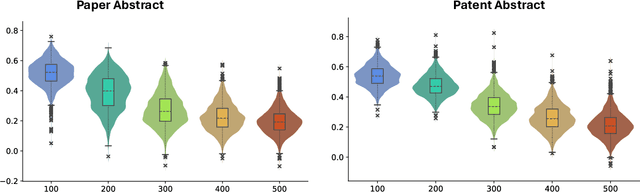
With the growing prevalence of generative artificial intelligence (AI), an increasing amount of content is no longer exclusively generated by humans but by generative AI models with human guidance. This shift presents notable challenges for the delineation of originality due to the varying degrees of human contribution in AI-assisted works. This study raises the research question of measuring human contribution in AI-assisted content generation and introduces a framework to address this question that is grounded in information theory. By calculating mutual information between human input and AI-assisted output relative to self-information of AI-assisted output, we quantify the proportional information contribution of humans in content generation. Our experimental results demonstrate that the proposed measure effectively discriminates between varying degrees of human contribution across multiple creative domains. We hope that this work lays a foundation for measuring human contributions in AI-assisted content generation in the era of generative AI.
Attention Mechanism and Context Modeling System for Text Mining Machine Translation
Aug 08, 2024



This paper advances a novel architectural schema anchored upon the Transformer paradigm and innovatively amalgamates the K-means categorization algorithm to augment the contextual apprehension capabilities of the schema. The transformer model performs well in machine translation tasks due to its parallel computing power and multi-head attention mechanism. However, it may encounter contextual ambiguity or ignore local features when dealing with highly complex language structures. To circumvent this constraint, this exposition incorporates the K-Means algorithm, which is used to stratify the lexis and idioms of the input textual matter, thereby facilitating superior identification and preservation of the local structure and contextual intelligence of the language. The advantage of this combination is that K-Means can automatically discover the topic or concept regions in the text, which may be directly related to translation quality. Consequently, the schema contrived herein enlists K-Means as a preparatory phase antecedent to the Transformer and recalibrates the multi-head attention weights to assist in the discrimination of lexis and idioms bearing analogous semantics or functionalities. This ensures the schema accords heightened regard to the contextual intelligence embodied by these clusters during the training phase, rather than merely focusing on locational intelligence.
Text-Driven Diverse Facial Texture Generation via Progressive Latent-Space Refinement
Apr 15, 2024



Automatic 3D facial texture generation has gained significant interest recently. Existing approaches may not support the traditional physically based rendering pipeline or rely on 3D data captured by Light Stage. Our key contribution is a progressive latent space refinement approach that can bootstrap from 3D Morphable Models (3DMMs)-based texture maps generated from facial images to generate high-quality and diverse PBR textures, including albedo, normal, and roughness. It starts with enhancing Generative Adversarial Networks (GANs) for text-guided and diverse texture generation. To this end, we design a self-supervised paradigm to overcome the reliance on ground truth 3D textures and train the generative model with only entangled texture maps. Besides, we foster mutual enhancement between GANs and Score Distillation Sampling (SDS). SDS boosts GANs with more generative modes, while GANs promote more efficient optimization of SDS. Furthermore, we introduce an edge-aware SDS for multi-view consistent facial structure. Experiments demonstrate that our method outperforms existing 3D texture generation methods regarding photo-realistic quality, diversity, and efficiency.
How COVID-19 has Impacted American Attitudes Toward China: A Study on Twitter
Aug 25, 2021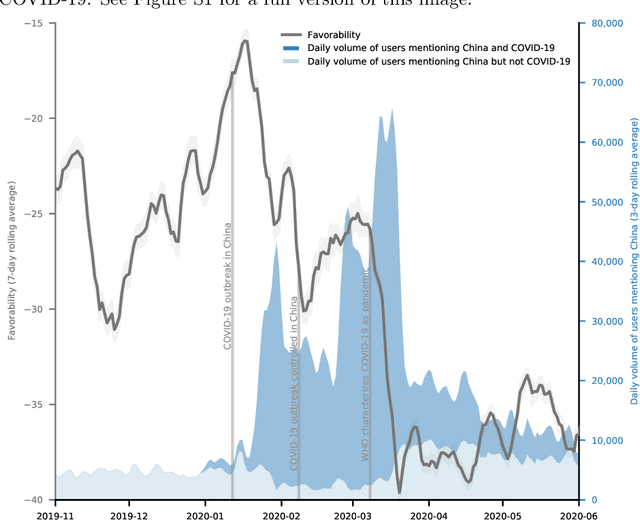
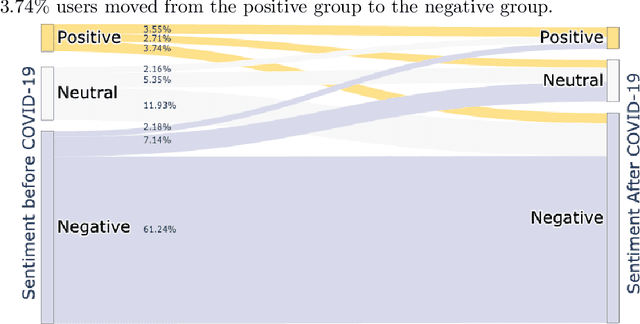
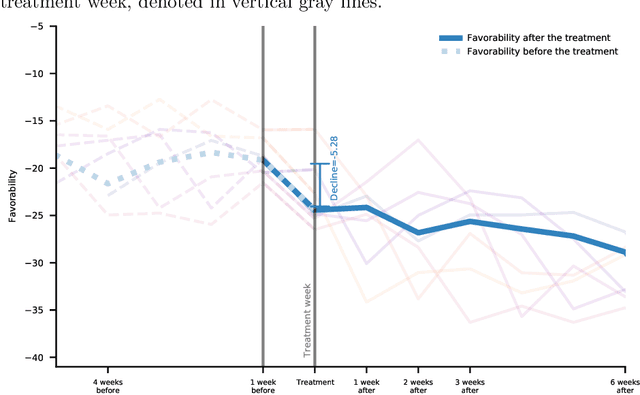
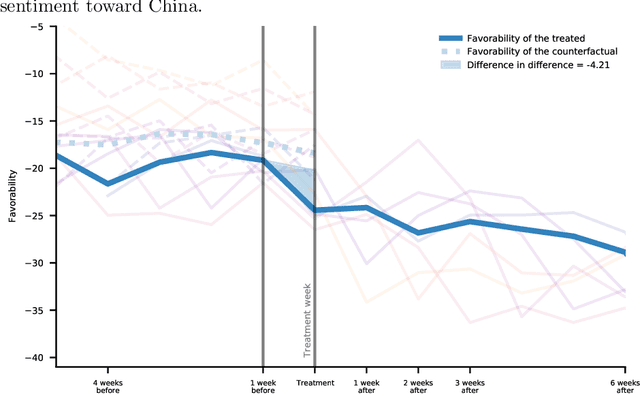
Past research has studied social determinants of attitudes toward foreign countries. Confounded by potential endogeneity biases due to unobserved factors or reverse causality, the causal impact of these factors on public opinion is usually difficult to establish. Using social media data, we leverage the suddenness of the COVID-19 pandemic to examine whether a major global event has causally changed American views of another country. We collate a database of more than 297 million posts on the social media platform Twitter about China or COVID-19 up to June 2020, and we treat tweeting about COVID-19 as a proxy for individual awareness of COVID-19. Using regression discontinuity and difference-in-difference estimation, we find that awareness of COVID-19 causes a sharp rise in anti-China attitudes. Our work has implications for understanding how self-interest affects policy preference and how Americans view migrant communities.