 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Recommendation Combining Collaborative Filtering and Large Language Models
Dec 25, 2024



With the advent of the information explosion era, the importance of recommendation systems in various applications is increasingly significant. Traditional collaborative filtering algorithms are widely used due to their effectiveness in capturing user behavior patterns, but they encounter limitations when dealing with cold start problems and data sparsity. Large Language Models (LLMs), with their strong natural language understanding and generation capabilities, provide a new breakthrough for recommendation systems. This study proposes an enhanced recommendation method that combines collaborative filtering and LLMs, aiming to leverage collaborative filtering's advantage in modeling user preferences while enhancing the understanding of textual information about users and items through LLMs to improve recommendation accuracy and diversity. This paper first introduces the fundamental theories of collaborative filtering and LLMs, then designs a recommendation system architecture that integrates both, and validates the system's effectiveness through experiments. The results show that the hybrid model based on collaborative filtering and LLMs significantly improves precision, recall, and user satisfaction, demonstrating its potential in complex recommendation scenarios.
Enhancing Recommendation Systems with GNNs and Addressing Over-Smoothing
Dec 04, 2024



This paper addresses key challenges in enhancing recommendation systems by leveraging Graph Neural Networks (GNNs) and addressing inherent limitations such as over-smoothing, which reduces model effectiveness as network hierarchy deepens. The proposed approach introduces three GNN-based recommendation models, specifically designed to mitigate over-smoothing through innovative mechanisms like residual connections and identity mapping within the aggregation propagation process. These modifications enable more effective information flow across layers, preserving essential user-item interaction details to improve recommendation accuracy. Additionally, the study emphasizes the critical need for interpretability in recommendation systems, aiming to provide transparent and justifiable suggestions tailored to dynamic user preferences. By integrating collaborative filtering with GNN architectures, the proposed models not only enhance predictive accuracy but also align recommendations more closely with individual behaviors, adapting to nuanced shifts in user interests. This work advances the field by tackling both technical and user-centric challenges, contributing to the development of robust and explainable recommendation systems capable of managing the complexity and scale of modern online environments.
Metric Learning for Tag Recommendation: Tackling Data Sparsity and Cold Start Issues
Nov 10, 2024


With the rapid growth of digital information, personalized recommendation systems have become an indispensable part of Internet services, especially in the fields of e-commerce, social media, and online entertainment. However, traditional collaborative filtering and content-based recommendation methods have limitations in dealing with data sparsity and cold start problems, especially in the face of largescale heterogeneous data, which makes it difficult to meet user expectations. This paper proposes a new label recommendation algorithm based on metric learning, which aims to overcome the challenges of traditional recommendation systems by learning effective distance or similarity metrics to capture the subtle differences between user preferences and item features. Experimental results show that the algorithm outperforms baseline methods including local response metric learning (LRML), collaborative metric learning (CML), and adaptive tensor factorization (ATF) based on adversarial learning on multiple evaluation metrics. In particular, it performs particularly well in the accuracy of the first few recommended items, while maintaining high robustness and maintaining high recommendation accuracy.
Analysis of Financial Risk Behavior Prediction Using Deep Learning and Big Data Algorithms
Oct 25, 2024



As the complexity and dynamism of financial markets continue to grow, traditional financial risk prediction methods increasingly struggle to handle large datasets and intricate behavior patterns. This paper explores the feasibility and effectiveness of using deep learning and big data algorithms for financial risk behavior prediction. First, the application and advantages of deep learning and big data algorithms in the financial field are analyzed. Then, a deep learning-based big data risk prediction framework is designed and experimentally validated on actual financial datasets. The experimental results show that this method significantly improves the accuracy of financial risk behavior prediction and provides valuable support for risk management in financial institutions. Challenges in the application of deep learning are also discussed, along with potential directions for future research.
A Recommendation Model Utilizing Separation Embedding and Self-Attention for Feature Mining
Oct 19, 2024



With the explosive growth of Internet data, users are facing the problem of information overload, which makes it a challenge to efficiently obtain the required resources. Recommendation systems have emerged in this context. By filtering massive amounts of information, they provide users with content that meets their needs, playing a key role in scenarios such as advertising recommendation and product recommendation. However, traditional click-through rate prediction and TOP-K recommendation mechanisms are gradually unable to meet the recommendations needs in modern life scenarios due to high computational complexity, large memory consumption, long feature selection time, and insufficient feature interaction. This paper proposes a recommendations system model based on a separation embedding cross-network. The model uses an embedding neural network layer to transform sparse feature vectors into dense embedding vectors, and can independently perform feature cross operations on different dimensions, thereby improving the accuracy and depth of feature mining. Experimental results show that the model shows stronger adaptability and higher prediction accuracy in processing complex data sets, effectively solving the problems existing in existing models.
Balancing Innovation and Privacy: Data Security Strategies in Natural Language Processing Applications
Oct 11, 2024



This research addresses privacy protection in Natural Language Processing (NLP) by introducing a novel algorithm based on differential privacy, aimed at safeguarding user data in common applications such as chatbots, sentiment analysis, and machine translation. With the widespread application of NLP technology, the security and privacy protection of user data have become important issues that need to be solved urgently. This paper proposes a new privacy protection algorithm designed to effectively prevent the leakage of user sensitive information. By introducing a differential privacy mechanism, our model ensures the accuracy and reliability of data analysis results while adding random noise. This method not only reduces the risk caused by data leakage but also achieves effective processing of data while protecting user privacy. Compared to traditional privacy methods like data anonymization and homomorphic encryption, our approach offers significant advantages in terms of computational efficiency and scalability while maintaining high accuracy in data analysis. The proposed algorithm's efficacy is demonstrated through performance metrics such as accuracy (0.89), precision (0.85), and recall (0.88), outperforming other methods in balancing privacy and utility. As privacy protection regulations become increasingly stringent, enterprises and developers must take effective measures to deal with privacy risks. Our research provides an important reference for the application of privacy protection technology in the field of NLP, emphasizing the need to achieve a balance between technological innovation and user privacy. In the future, with the continuous advancement of technology, privacy protection will become a core element of data-driven applications and promote the healthy development of the entire industry.
Graph Neural Network Framework for Sentiment Analysis Using Syntactic Feature
Sep 21, 2024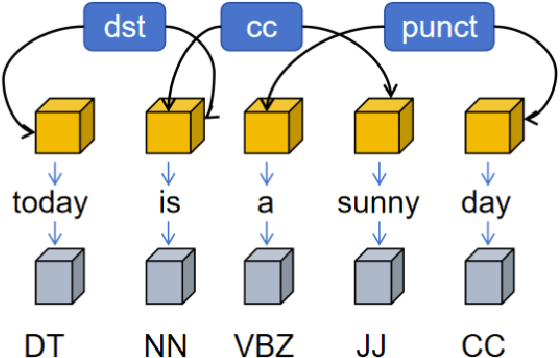
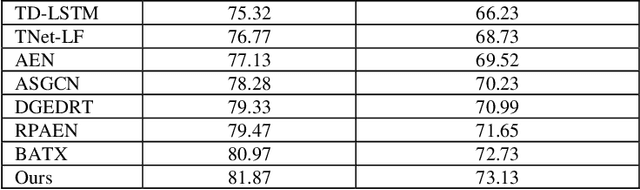
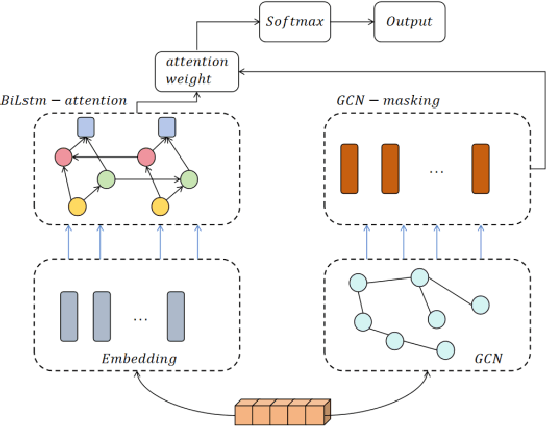
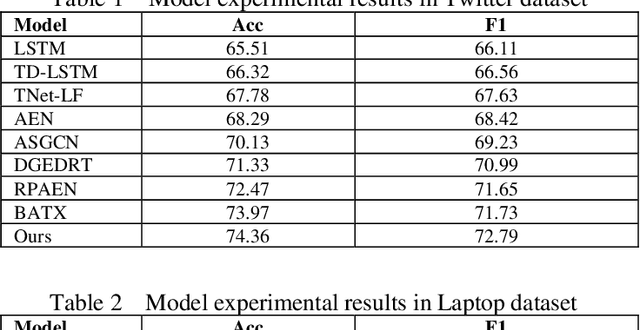
Amidst the swift evolution of social media platforms and e-commerce ecosystems, the domain of opinion mining has surged as a pivotal area of exploration within natural language processing. A specialized segment within this field focuses on extracting nuanced evaluations tied to particular elements within textual contexts. This research advances a composite framework that amalgamates the positional cues of topical descriptors. The proposed system converts syntactic structures into a matrix format, leveraging convolutions and attention mechanisms within a graph to distill salient characteristics. Incorporating the positional relevance of descriptors relative to lexical items enhances the sequential integrity of the input. Trials have substantiated that this integrated graph-centric scheme markedly elevates the efficacy of evaluative categorization, showcasing preeminence.