 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Guided Dynamic Retrieval for Improving Generation Quality in RAG Models
Apr 28, 2025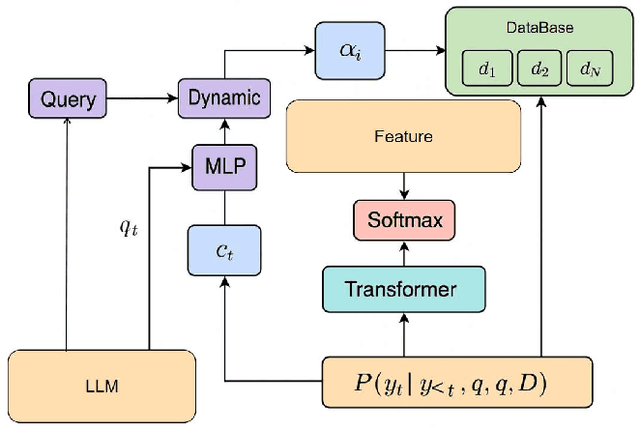
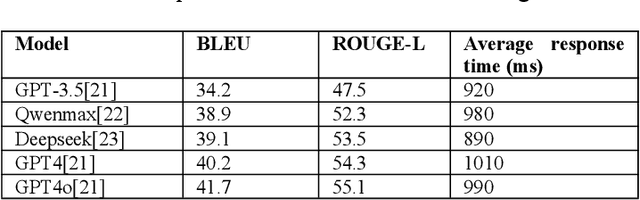
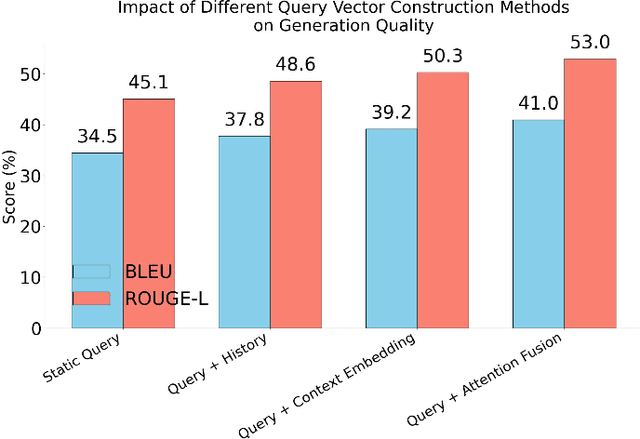
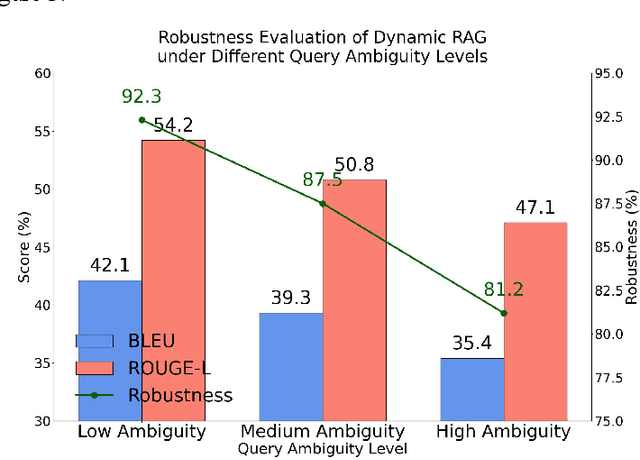
This paper focuses on the dynamic optimization of the Retrieval-Augmented Generation (RAG) architecture. It proposes a state-aware dynamic knowledge retrieval mechanism to enhance semantic understanding and knowledge scheduling efficiency in large language models for open-domain question answering and complex generation tasks. The method introduces a multi-level perceptive retrieval vector construction strategy and a differentiable document matching path. These components enable end-to-end joint training and collaborative optimization of the retrieval and generation modules. This effectively addresses the limitations of static RAG structures in context adaptation and knowledge access. Experiments are conducted on the Natural Questions dataset. The proposed structure is thoroughly evaluated across different large models, including GPT-4, GPT-4o, and DeepSeek. Comparative and ablation experiments from multiple perspectives confirm the significant improvements in BLEU and ROUGE-L scores. The approach also demonstrates stronger robustness and generation consistency in tasks involving semantic ambiguity and multi-document fusion. These results highlight its broad application potential and practical value in building high-quality language generation systems.
Graph-Based Spectral Decomposition for Parameter Coordination in Language Model Fine-Tuning
Apr 28, 2025This paper proposes a parameter collaborative optimization algorithm for large language models, enhanced with graph spectral analysis. The goal is to improve both fine-tuning efficiency and structural awareness during training. In the proposed method, the parameters of a pre-trained language model are treated as nodes in a graph. A weighted graph is constructed, and Laplacian spectral decomposition is applied to enable frequency-domain modeling and structural representation of the parameter space. Based on this structure, a joint loss function is designed. It combines the task loss with a spectral regularization term to facilitate collaborative updates among parameters. In addition, a spectral filtering mechanism is introduced during the optimization phase. This mechanism adjusts gradients in a structure-aware manner, enhancing the model's training stability and convergence behavior. The method is evaluated on multiple tasks, including traditional fine-tuning comparisons, few-shot generalization tests, and convergence speed analysis. In all settings, the proposed approach demonstrates superior performance. The experimental results confirm that the spectral collaborative optimization framework effectively reduces parameter perturbations and improves fine-tuning quality while preserving overall model performance. This work contributes significantly to the field of artificial intelligence by advancing parameter-efficient training methodologies for large-scale models, reinforcing the importance of structural signal processing in deep learning optimization, and offering a robust, generalizable framework for enhancing language model adaptability and performance.
Pre-trained Language Models and Few-shot Learning for Medical Entity Extraction
Apr 06, 2025This study proposes a medical entity extraction method based on Transformer to enhance the information extraction capability of medical literature. Considering the professionalism and complexity of medical texts, we compare the performance of different pre-trained language models (BERT, BioBERT, PubMedBERT, ClinicalBERT) in medical entity extraction tasks. Experimental results show that PubMedBERT achieves the best performance (F1-score = 88.8%), indicating that a language model pre-trained on biomedical literature is more effective in the medical domain. In addition, we analyze the impact of different entity extraction methods (CRF, Span-based, Seq2Seq) and find that the Span-based approach performs best in medical entity extraction tasks (F1-score = 88.6%). It demonstrates superior accuracy in identifying entity boundaries. In low-resource scenarios, we further explore the application of Few-shot Learning in medical entity extraction. Experimental results show that even with only 10-shot training samples, the model achieves an F1-score of 79.1%, verifying the effectiveness of Few-shot Learning under limited data conditions. This study confirms that the combination of pre-trained language models and Few-shot Learning can enhance the accuracy of medical entity extraction. Future research can integrate knowledge graphs and active learning strategies to improve the model's generalization and stability, providing a more effective solution for medical NLP research. Keywords- Natural Language Processing, medical named entity recognition, pre-trained language model, Few-shot Learning, information extraction, deep learning
A Fine-Tuning Approach for T5 Using Knowledge Graphs to Address Complex Tasks
Feb 23, 2025



With the development of deep learning technology, large language models have achieved remarkable results in many natural language processing tasks. However, these models still have certain limitations in handling complex reasoning tasks and understanding rich background knowledge. To solve this problem, this study proposed a T5 model fine-tuning method based on knowledge graphs, which enhances the model's reasoning ability and context understanding ability by introducing external knowledge graphs. We used the SQuAD1.1 dataset for experiments. The experimental results show that the T5 model based on knowledge graphs is significantly better than other baseline models in reasoning accuracy, context understanding, and the ability to handle complex problems. At the same time, we also explored the impact of knowledge graphs of different scales on model performance and found that as the scale of the knowledge graph increases, the performance of the model gradually improves. Especially when dealing with complex problems, the introduction of knowledge graphs greatly improves the reasoning ability of the T5 model. Ablation experiments further verify the importance of entity and relationship embedding in the model and prove that a complete knowledge graph is crucial to improving the various capabilities of the T5 model. In summary, this study provides an effective method to enhance the reasoning and understanding capabilities of large language models and provides new directions for future research.
A Hybrid Model for Few-Shot Text Classification Using Transfer and Meta-Learning
Feb 13, 2025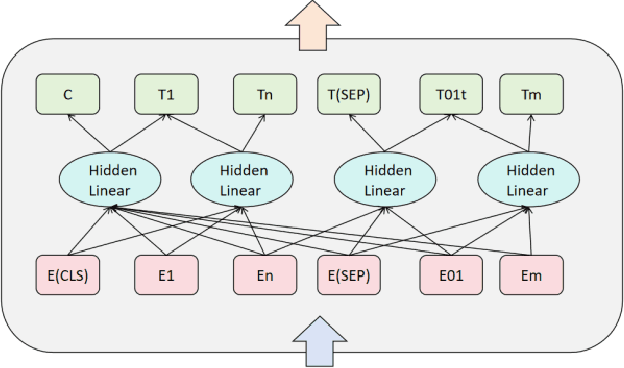
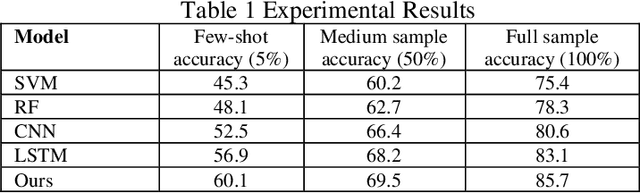
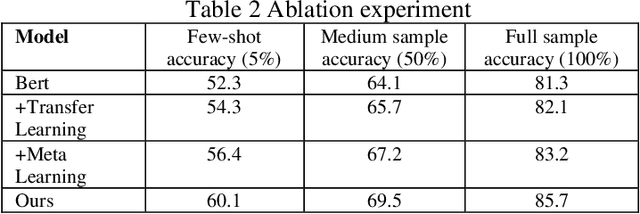
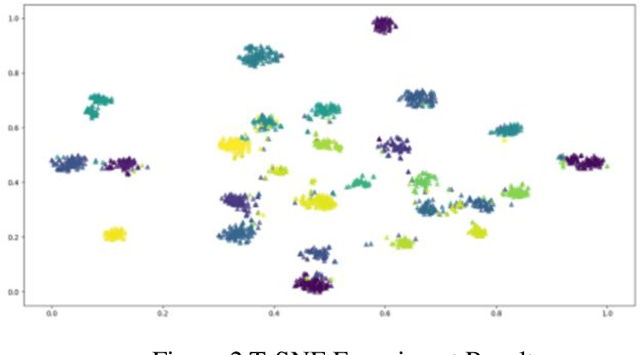
With the continuous development of natural language processing (NLP) technology, text classification tasks have been widely used in multiple application fields. However, obtaining labeled data is often expensive and difficult, especially in few-shot learning scenarios. To solve this problem, this paper proposes a few-shot text classification model based on transfer learning and meta-learning. The model uses the knowledge of the pre-trained model for transfer and optimizes the model's rapid adaptability in few-sample tasks through a meta-learning mechanism. Through a series of comparative experiments and ablation experiments, we verified the effectiveness of the proposed method. The experimental results show that under the conditions of few samples and medium samples, the model based on transfer learning and meta-learning significantly outperforms traditional machine learning and deep learning methods. In addition, ablation experiments further analyzed the contribution of each component to the model performance and confirmed the key role of transfer learning and meta-learning in improving model accuracy. Finally, this paper discusses future research directions and looks forward to the potential of this method in practical applications.
A Review of Intelligent Device Fault Diagnosis Technologies Based on Machine Vision
Dec 11, 2024This paper provides a comprehensive review of mechanical equipment fault diagnosis methods, focusing on the advancements brought by Transformer-based models. It details the structure, working principles, and benefits of Transformers, particularly their self-attention mechanism and parallel computation capabilities, which have propelled their widespread application in natural language processing and computer vision. The discussion highlights key Transformer model variants, such as Vision Transformers (ViT) and their extensions, which leverage self-attention to improve accuracy and efficiency in visual tasks. Furthermore, the paper examines the application of Transformer-based approaches in intelligent fault diagnosis for mechanical systems, showcasing their superior ability to extract and recognize patterns from complex sensor data for precise fault identification. Despite these advancements, challenges remain, including the reliance on extensive labeled datasets, significant computational demands, and difficulties in deploying models on resource-limited devices. To address these limitations, the paper proposes future research directions, such as developing lightweight Transformer architectures, integrating multimodal data sources, and enhancing adaptability to diverse operational conditions. These efforts aim to further expand the application of Transformer-based methods in mechanical fault diagnosis, making them more robust, efficient, and suitable for real-world industrial environments.
Dynamic EEG-fMRI mapping: Revealing the relationship between brain connectivity and cognitive state
Nov 29, 2024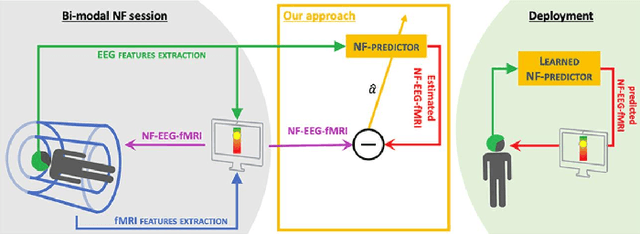
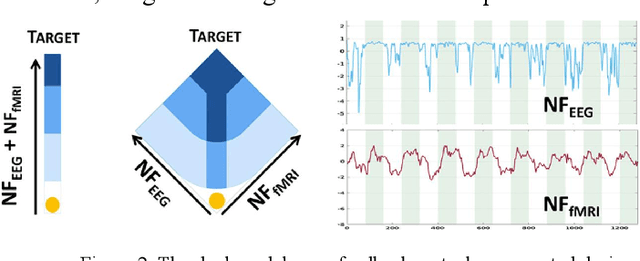
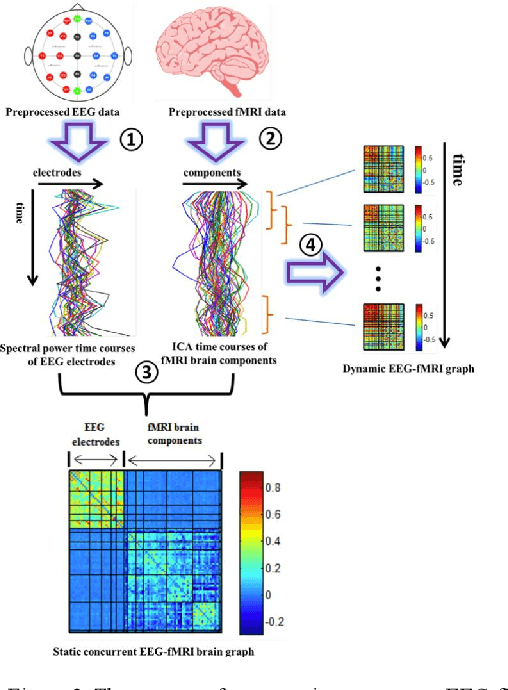
This study investigated the dynamic connectivity patterns between EEG and fMRI modalities, contributing to our understanding of brain network interactions. By employing a comprehensive approach that integrated static and dynamic analyses of EEG-fMRI data, we were able to uncover distinct connectivity states and characterize their temporal fluctuations. The results revealed modular organization within the intrinsic connectivity networks (ICNs) of the brain, highlighting the significant roles of sensory systems and the default mode network. The use of a sliding window technique allowed us to assess how functional connectivity varies over time, further elucidating the transient nature of brain connectivity. Additionally, our findings align with previous literature, reinforcing the notion that cognitive states can be effectively identified through short-duration data, specifically within the 30-60 second timeframe. The established relationships between connectivity strength and cognitive processes, particularly during different visual states, underscore the relevance of our approach for future research into brain dynamics. Overall, this study not only enhances our understanding of the interplay between EEG and fMRI signals but also paves the way for further exploration into the neural correlates of cognitive functions and their implications in clinical settings. Future research should focus on refining these methodologies and exploring their applications in various cognitive and clinical contexts.
Balancing Innovation and Privacy: Data Security Strategies in Natural Language Processing Applications
Oct 11, 2024



This research addresses privacy protection in Natural Language Processing (NLP) by introducing a novel algorithm based on differential privacy, aimed at safeguarding user data in common applications such as chatbots, sentiment analysis, and machine translation. With the widespread application of NLP technology, the security and privacy protection of user data have become important issues that need to be solved urgently. This paper proposes a new privacy protection algorithm designed to effectively prevent the leakage of user sensitive information. By introducing a differential privacy mechanism, our model ensures the accuracy and reliability of data analysis results while adding random noise. This method not only reduces the risk caused by data leakage but also achieves effective processing of data while protecting user privacy. Compared to traditional privacy methods like data anonymization and homomorphic encryption, our approach offers significant advantages in terms of computational efficiency and scalability while maintaining high accuracy in data analysis. The proposed algorithm's efficacy is demonstrated through performance metrics such as accuracy (0.89), precision (0.85), and recall (0.88), outperforming other methods in balancing privacy and utility. As privacy protection regulations become increasingly stringent, enterprises and developers must take effective measures to deal with privacy risks. Our research provides an important reference for the application of privacy protection technology in the field of NLP, emphasizing the need to achieve a balance between technological innovation and user privacy. In the future, with the continuous advancement of technology, privacy protection will become a core element of data-driven applications and promote the healthy development of the entire industry.
Graph Neural Network Framework for Sentiment Analysis Using Syntactic Feature
Sep 21, 2024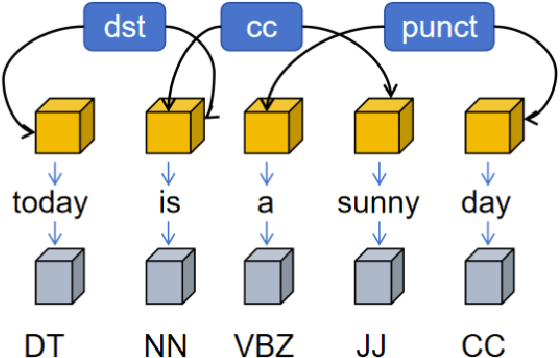
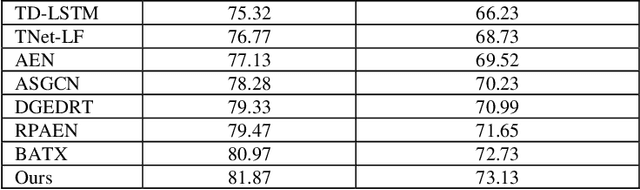
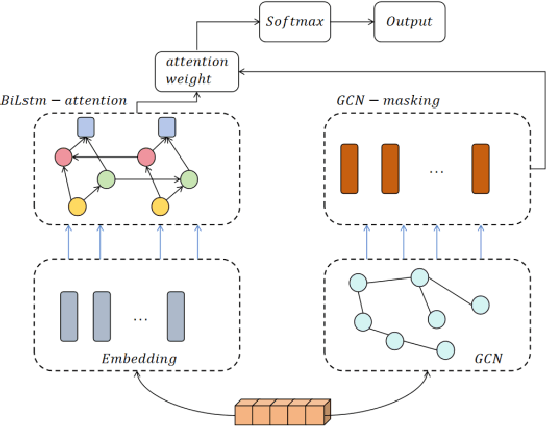
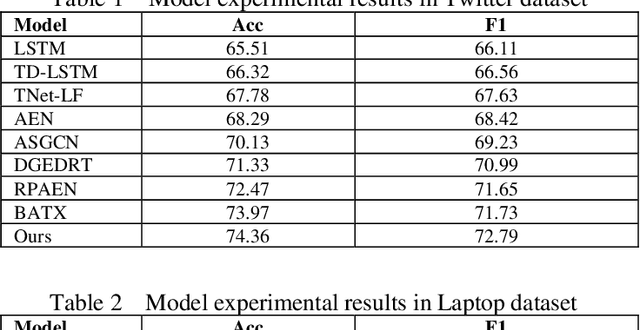
Amidst the swift evolution of social media platforms and e-commerce ecosystems, the domain of opinion mining has surged as a pivotal area of exploration within natural language processing. A specialized segment within this field focuses on extracting nuanced evaluations tied to particular elements within textual contexts. This research advances a composite framework that amalgamates the positional cues of topical descriptors. The proposed system converts syntactic structures into a matrix format, leveraging convolutions and attention mechanisms within a graph to distill salient characteristics. Incorporating the positional relevance of descriptors relative to lexical items enhances the sequential integrity of the input. Trials have substantiated that this integrated graph-centric scheme markedly elevates the efficacy of evaluative categorization, showcasing preeminence.