 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fine-Tuning Approach for T5 Using Knowledge Graphs to Address Complex Tasks
Feb 23, 2025



With the development of deep learning technology, large language models have achieved remarkable results in many natural language processing tasks. However, these models still have certain limitations in handling complex reasoning tasks and understanding rich background knowledge. To solve this problem, this study proposed a T5 model fine-tuning method based on knowledge graphs, which enhances the model's reasoning ability and context understanding ability by introducing external knowledge graphs. We used the SQuAD1.1 dataset for experiments. The experimental results show that the T5 model based on knowledge graphs is significantly better than other baseline models in reasoning accuracy, context understanding, and the ability to handle complex problems. At the same time, we also explored the impact of knowledge graphs of different scales on model performance and found that as the scale of the knowledge graph increases, the performance of the model gradually improves. Especially when dealing with complex problems, the introduction of knowledge graphs greatly improves the reasoning ability of the T5 model. Ablation experiments further verify the importance of entity and relationship embedding in the model and prove that a complete knowledge graph is crucial to improving the various capabilities of the T5 model. In summary, this study provides an effective method to enhance the reasoning and understanding capabilities of large language models and provides new directions for future research.
A Hybrid Model for Few-Shot Text Classification Using Transfer and Meta-Learning
Feb 13, 2025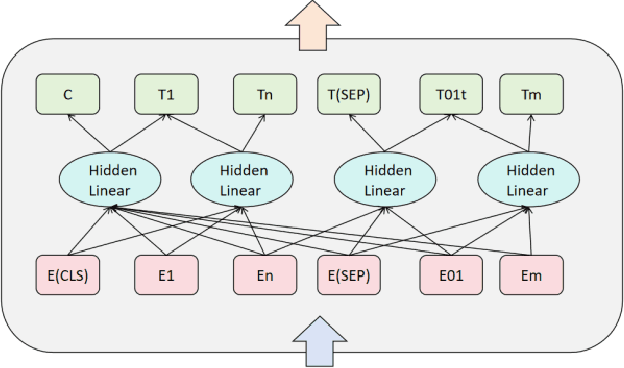
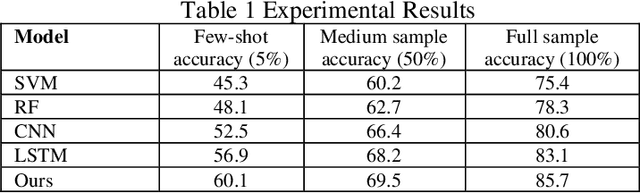
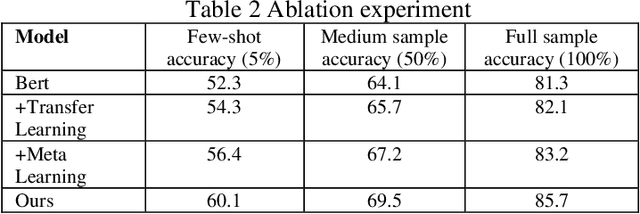
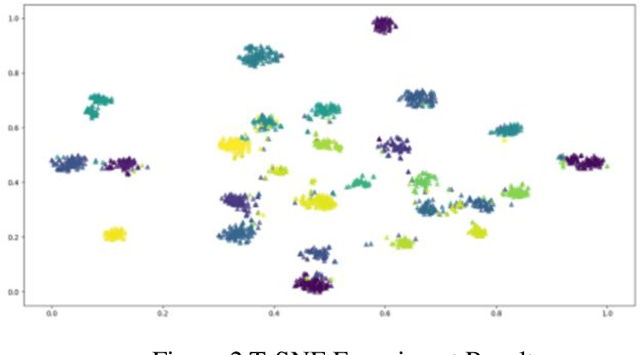
With the continuous development of natural language processing (NLP) technology, text classification tasks have been widely used in multiple application fields. However, obtaining labeled data is often expensive and difficult, especially in few-shot learning scenarios. To solve this problem, this paper proposes a few-shot text classification model based on transfer learning and meta-learning. The model uses the knowledge of the pre-trained model for transfer and optimizes the model's rapid adaptability in few-sample tasks through a meta-learning mechanism. Through a series of comparative experiments and ablation experiments, we verified the effectiveness of the proposed method. The experimental results show that under the conditions of few samples and medium samples, the model based on transfer learning and meta-learning significantly outperforms traditional machine learning and deep learning methods. In addition, ablation experiments further analyzed the contribution of each component to the model performance and confirmed the key role of transfer learning and meta-learning in improving model accuracy. Finally, this paper discusses future research directions and looks forward to the potential of this method in practical applications.
Dynamic Adaptation of LoRA Fine-Tuning for Efficient and Task-Specific Optimization of Large Language Models
Jan 24, 2025



This paper presents a novel methodology of fine-tuning for large language models-dynamic LoRA. Building from the standard Low-Rank Adaptation framework, this methodology further adds dynamic adaptation mechanisms to improve efficiency and performance. The key contribution of dynamic LoRA lies within its adaptive weight allocation mechanism coupled with an input feature-based adaptive strategy. These enhancements allow for a more precise fine-tuning process that is more tailored to specific tasks. Traditional LoRA methods use static adapter settings, not considering the different importance of model layers. In contrast, dynamic LoRA introduces a mechanism that dynamically evaluates the layer's importance during fine-tuning. This evaluation enables the reallocation of adapter parameters to fit the unique demands of each individual task, which leads to better optimization results. Another gain in flexibility arises from the consideration of the input feature distribution, which helps the model generalize better when faced with complicated and diverse datasets. The joint approach boosts not only the performance over each single task but also the generalization ability of the model. The efficiency of the dynamic LoRA was validated in experiments on benchmark datasets, such as GLUE, with surprising results. More specifically, this method achieved 88.1% accuracy with an F1-score of 87.3%. Noticeably, these improvements were made at a slight increase in computational costs: only 0.1% more resources than standard LoRA. This balance between performance and efficiency positions dynamic LoRA as a practical, scalable solution for fine-tuning LLMs, especially in resource-constrained scenarios. To take it a step further, its adaptability makes it a promising foundation for much more advanced applications, including multimodal tasks.
Feature Alignment-Based Knowledge Distillation for Efficient Compression of Large Language Models
Dec 27, 2024


This study proposes a knowledge distillation algorithm based on large language models and feature alignment, aiming to effectively transfer the knowledge of large pre-trained models into lightweight student models, thereby reducing computational costs while maintaining high model performance. Different from the traditional soft label distillation method, this method introduces a multi-layer feature alignment strategy to deeply align the intermediate features and attention mechanisms of the teacher model and the student model, maximally retaining the semantic expression ability and context modeling ability of the teacher model. In terms of method design, a multi-task loss function is constructed, including feature matching loss, attention alignment loss, and output distribution matching loss, to ensure multi-level information transfer through joint optimization. The experiments were comprehensively evaluated on the GLUE data set and various natural language processing tasks. The results show that the proposed model performs very close to the state-of-the-art GPT-4 model in terms of evaluation indicators such as perplexity, BLEU, ROUGE, and CER. At the same time, it far exceeds baseline models such as DeBERTa, XLNet, and GPT-3, showing significant performance improvements and computing efficiency advantages. Research results show that the feature alignment distillation strategy is an effective model compression method that can significantly reduce computational overhead and storage requirements while maintaining model capabilities. Future research can be further expanded in the directions of self-supervised learning, cross-modal feature alignment, and multi-task transfer learning to provide more flexible and efficient solutions for the deployment and optimization of deep learning models.
Optimizing Large Language Models with an Enhanced LoRA Fine-Tuning Algorithm for Efficiency and Robustness in NLP Tasks
Dec 25, 2024


This study proposes a large language model optimization method based on the improved LoRA fine-tuning algorithm, aiming to improve the accuracy and computational efficiency of the model in natural language processing tasks. We fine-tune the large language model through a low-rank adaptation strategy, which significantly reduces the consumption of computing resources while maintaining the powerful capabilities of the pre-trained model. The experiment uses the QQP task as the evaluation scenario. The results show that the improved LoRA algorithm shows significant improvements in accuracy, F1 score, and MCC compared with traditional models such as BERT, Roberta, T5, and GPT-4. In particular, in terms of F1 score and MCC, our model shows stronger robustness and discrimination ability, which proves the potential of the improved LoRA algorithm in fine-tuning large-scale pre-trained models. In addition, this paper also discusses the application prospects of the improved LoRA algorithm in other natural language processing tasks, emphasizing its advantages in multi-task learning and scenarios with limited computing resources. Future research can further optimize the LoRA fine-tuning strategy and expand its application in larger-scale pre-trained models to improve the generalization ability and task adaptability of the model.
Adaptive Optimization for Enhanced Efficiency in Large-Scale Language Model Training
Dec 06, 2024



With the rapid development of natural language processing technology, large-scale language models (LLM) have achieved remarkable results in a variety of tasks. However, how to effectively train these huge models and improve their performance and computational efficiency remains an important challenge. This paper proposes an improved method based on adaptive optimization algorithm, aiming to improve the training efficiency and final performance of LLM. Through comparative experiments on the SQuAD and GLUE data sets, the experimental results show that compared with traditional optimization algorithms (such as SGD, Momentum, AdaGrad, RMSProp and Adam), the adaptive optimization algorithm we proposed has better accuracy and F1 score. Both have achieved significant improvements, especially showed stronger training capabilities when processed large-scale texts and complex tasks. The research results verify the advantages of adaptive optimization algorithms in large-scale language model training and provide new ideas and directions for future optimization methods.
Graph Neural Network-Based Entity Extraction and Relationship Reasoning in Complex Knowledge Graphs
Nov 19, 2024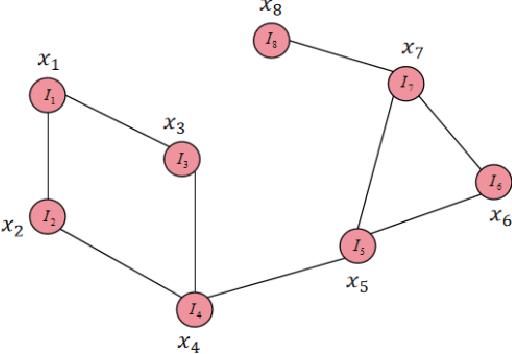


This study proposed a knowledge graph entity extraction and relationship reasoning algorithm based on a graph neural network, using a graph convolutional network and graph attention network to model the complex structure in the knowledge graph. By building an end-to-end joint model, this paper achieves efficient recognition and reasoning of entities and relationships. In the experiment, this paper compared the model with a variety of deep learning algorithms and verified its superiority through indicators such as AUC, recall rate, precision rate, and F1 value. The experimental results show that the model proposed in this paper performs well in all indicators, especially in complex knowledge graphs, it has stronger generalization ability and stability. This provides strong support for further research on knowledge graphs and also demonstrates the application potential of graph neural networks in entity extraction and relationship reasoning.