 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIvilization v0: Toward Large-Scale Artificial Social Simulation with a Unified Agent Architecture and Adaptive Agent Profiles
Feb 11, 2026AIvilization v0 is a publicly deployed large-scale artificial society that couples a resource-constrained sandbox economy with a unified LLM-agent architecture, aiming to sustain long-horizon autonomy while remaining executable under rapidly changing environment. To mitigate the tension between goal stability and reactive correctness, we introduce (i) a hierarchical branch-thinking planner that decomposes life goals into parallel objective branches and uses simulation-guided validation plus tiered re-planning to ensure feasibility; (ii) an adaptive agent profile with dual-process memory that separates short-term execution traces from long-term semantic consolidation, enabling persistent yet evolving identity; and (iii) a human-in-the-loop steering interface that injects long-horizon objectives and short commands at appropriate abstraction levels, with effects propagated through memory rather than brittle prompt overrides. The environment integrates physiological survival costs, non-substitutable multi-tier production, an AMM-based price mechanism, and a gated education-occupation system. Using high-frequency transactions from the platforms mature phase, we find stable markets that reproduce key stylized facts (heavy-tailed returns and volatility clustering) and produce structured wealth stratification driven by education and access constraints. Ablations show simplified planners can match performance on narrow tasks, while the full architecture is more robust under multi-objective, long-horizon settings, supporting delayed investment and sustained exploration.
Instructional Prompt Optimization for Few-Shot LLM-Based Recommendations on Cold-Start Users
Sep 11, 2025The cold-start user issue further compromises the effectiveness of recommender systems in limiting access to the historical behavioral information. It is an effective pipeline to optimize instructional prompts on a few-shot large language model (LLM) used in recommender tasks. We introduce a context-conditioned prompt formulation method P(u,\ Ds)\ \rightarrow\ R\widehat, where u is a cold-start user profile, Ds is a curated support set, and R\widehat is the predicted ranked list of items. Based on systematic experimentation with transformer-based autoregressive LLMs (BioGPT, LLaMA-2, GPT-4), we provide empirical evidence that optimal exemplar injection and instruction structuring can significantly improve the precision@k and NDCG scores of such models in low-data settings. The pipeline uses token-level alignments and embedding space regularization with a greater semantic fidelity. Our findings not only show that timely composition is not merely syntactic but also functional as it is in direct control of attention scales and decoder conduct through inference. This paper shows that prompt-based adaptation may be considered one of the ways to address cold-start recommendation issues in LLM-based pipelines.
UniDet-D: A Unified Dynamic Spectral Attention Model for Object Detection under Adverse Weathers
Jun 14, 2025Real-world object detection is a challenging task where the captured images/videos often suffer from complex degradations due to various adverse weather conditions such as rain, fog, snow, low-light, etc. Despite extensive prior efforts, most existing methods are designed for one specific type of adverse weather with constraints of poor generalization, under-utilization of visual features while handling various image degradations. Leveraging a theoretical analysis on how critical visual details are lost in adverse-weather images, we design UniDet-D, a unified framework that tackles the challenge of object detection under various adverse weather conditions, and achieves object detection and image restoration within a single network. Specifically, the proposed UniDet-D incorporates a dynamic spectral attention mechanism that adaptively emphasizes informative spectral components while suppressing irrelevant ones, enabling more robust and discriminative feature representation across various degradation types. Extensive experiments show that UniDet-D achieves superior detection accuracy across different types of adverse-weather degradation. Furthermore, UniDet-D demonstrates superior generalization towards unseen adverse weather conditions such as sandstorms and rain-fog mixtures, highlighting its great potential for real-world deployment.
LLM-Driven E-Commerce Marketing Content Optimization: Balancing Creativity and Conversion
May 27, 2025As e-commerce competition intensifies, balancing creative content with conversion effectiveness becomes critical. Leveraging LLMs' language generation capabilities, we propose a framework that integrates prompt engineering, multi-objective fine-tuning, and post-processing to generate marketing copy that is both engaging and conversion-driven. Our fine-tuning method combines sentiment adjustment, diversity enhancement, and CTA embedding. Through offline evaluations and online A/B tests across categories, our approach achieves a 12.5 % increase in CTR and an 8.3 % increase in CVR while maintaining content novelty. This provides a practical solution for automated copy generation and suggests paths for future multimodal, real-time personalization.
User Behavior Analysis in Privacy Protection with Large Language Models: A Study on Privacy Preferences with Limited Data
May 08, 2025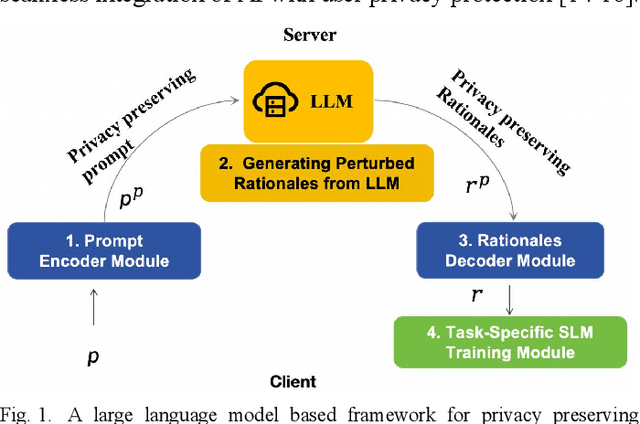

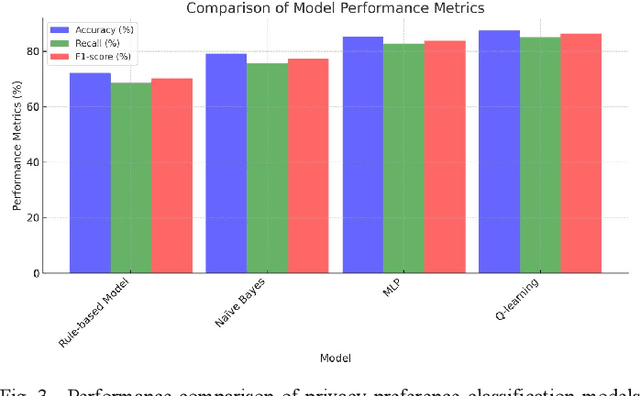

With the widespread application of large language models (LLMs), user privacy protection has become a significant research topic. Existing privacy preference modeling methods often rely on large-scale user data, making effective privacy preference analysis challenging in data-limited environments. This study explores how LLMs can analyze user behavior related to privacy protection in scenarios with limited data and proposes a method that integrates Few-shot Learning and Privacy Computing to model user privacy preferences. The research utilizes anonymized user privacy settings data, survey responses, and simulated data, comparing the performance of traditional modeling approaches with LLM-based methods. Experimental results demonstrate that, even with limited data, LLMs significantly improve the accuracy of privacy preference modeling. Additionally, incorporating Differential Privacy and Federated Learning further reduces the risk of user data exposure. The findings provide new insights into the application of LLMs in privacy protection and offer theoretical support for advancing privacy computing and user behavior analysis.
Optimization and Scalability of Collaborative Filtering Algorithms in Large Language Models
Dec 25, 2024With the rapid development of large language models (LLMs) and the growing demand for personalized content, recommendation systems have become critical in enhancing user experience and driving engagement. Collaborative filtering algorithms, being core to many recommendation systems, have garnered significant attention for their efficiency and interpretability. However, traditional collaborative filtering approaches face numerous challenges when integrated into large-scale LLM-based systems, including high computational costs, severe data sparsity, cold start problems, and lack of scalability. This paper investigates the optimization and scalability of collaborative filtering algorithms in large language models, addressing these limitations through advanced optimization strategies. Firstly, we analyze the fundamental principles of collaborative filtering algorithms and their limitations when applied in LLM-based contexts. Next, several optimization techniques such as matrix factorization, approximate nearest neighbor search, and parallel computing are proposed to enhance computational efficiency and model accuracy. Additionally, strategies such as distributed architecture and model compression are explored to facilitate dynamic updates and scalability in data-intensive environments.
Analysis of Financial Risk Behavior Prediction Using Deep Learning and Big Data Algorithms
Oct 25, 2024



As the complexity and dynamism of financial markets continue to grow, traditional financial risk prediction methods increasingly struggle to handle large datasets and intricate behavior patterns. This paper explores the feasibility and effectiveness of using deep learning and big data algorithms for financial risk behavior prediction. First, the application and advantages of deep learning and big data algorithms in the financial field are analyzed. Then, a deep learning-based big data risk prediction framework is designed and experimentally validated on actual financial datasets. The experimental results show that this method significantly improves the accuracy of financial risk behavior prediction and provides valuable support for risk management in financial institutions. Challenges in the application of deep learning are also discussed, along with potential directions for future research.
Research on Key Technologies for Cross-Cloud Federated Training of Large Language Models
Oct 24, 2024With the rapid development of natural language processing technology, large language models have demonstrated exceptional performance in various application scenarios. However, training these models requires significant computational resources and data processing capabilities. Cross-cloud federated training offers a new approach to addressing the resource bottlenecks of a single cloud platform, allowing the computational resources of multiple clouds to collaboratively complete the training tasks of large models. This study analyzes the key technologies of cross-cloud federated training, including data partitioning and distribution, communication optimization, model aggregation algorithms, and the compatibility of heterogeneous cloud platforms. Additionally, the study examines data security and privacy protection strategies in cross-cloud training, particularly the application of data encryption and differential privacy techniques. Through experimental validation, the proposed technical framework demonstrates enhanced training efficiency, ensured data security, and reduced training costs, highlighting the broad application prospects of cross-cloud federated training.
Analysis and Design of a Personalized Recommendation System Based on a Dynamic User Interest Model
Oct 13, 2024With the rapid development of the internet and the explosion of information, providing users with accurate personalized recommendations has become an important research topic. This paper designs and analyzes a personalized recommendation system based on a dynamic user interest model. The system captures user behavior data, constructs a dynamic user interest model, and combines multiple recommendation algorithms to provide personalized content to users. The research results show that this system significantly improves recommendation accuracy and user satisfaction. This paper discusses the system's architecture design, algorithm implementation, and experimental results in detail and explores future research directions.
Multi-modal clothing recommendation model based on large model and VAE enhancement
Oct 03, 2024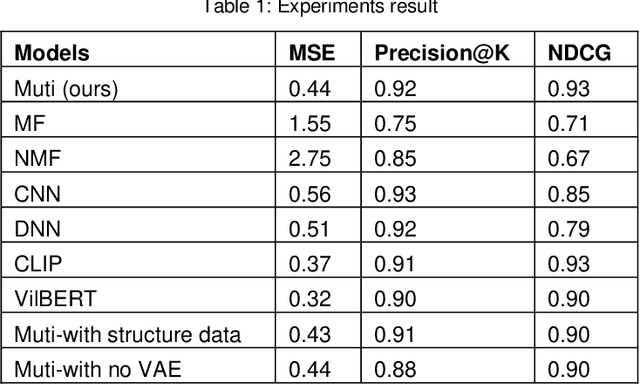
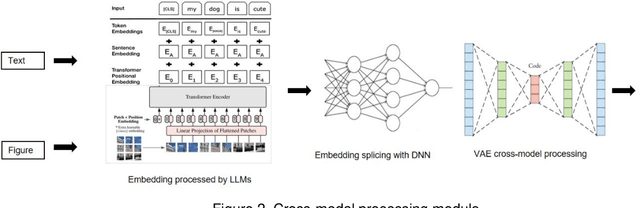
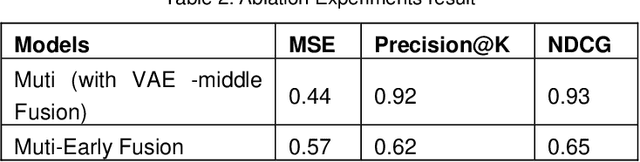
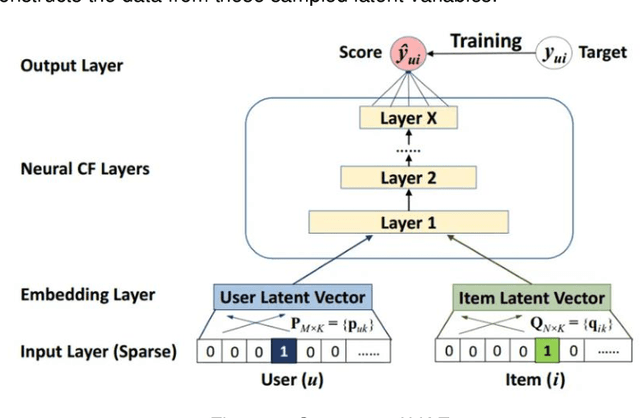
Accurately recommending products has long been a subject requiring in-depth research. This study proposes a multimodal paradigm for clothing recommendations. Specifically, it designs a multimodal analysis method that integrates clothing description texts and images, utilizing a pre-trained large language model to deeply explore the hidden meanings of users and products. Additionally, a variational encoder is employed to learn the relationship between user information and products to address the cold start problem in recommendation systems. This study also validates the significant performance advantages of this method over various recommendation system methods through extensive ablation experiments, providing crucial practical guidance for the comprehensive optimization of recommendation systems.