 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenMapping: Unleashing the Potential of Inverse Perspective Mapping for Robust Online HD Map Construction
Sep 13, 2024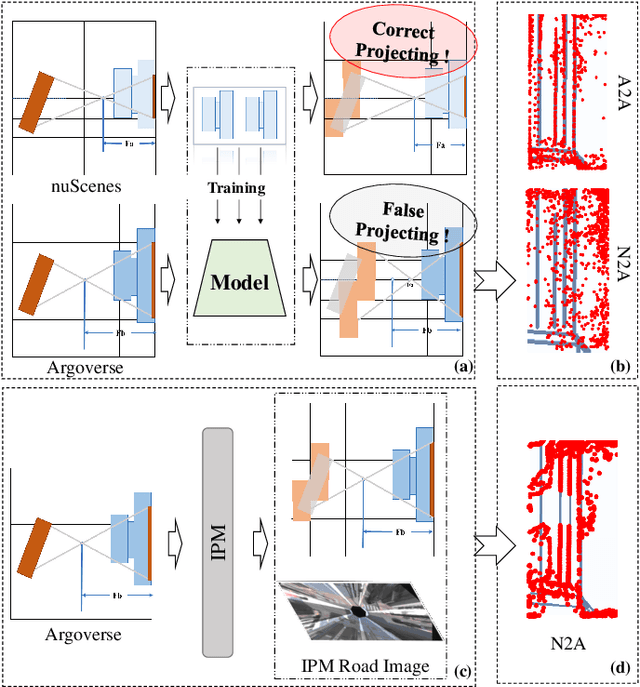
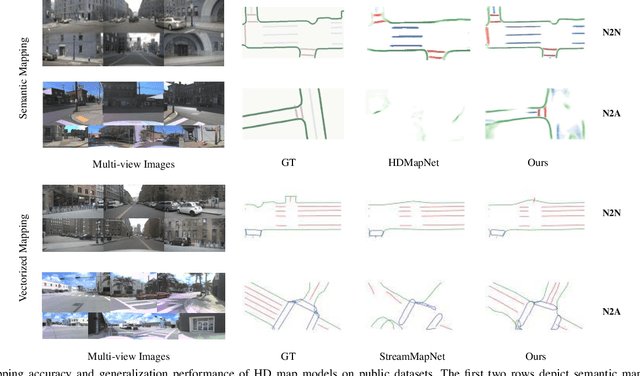
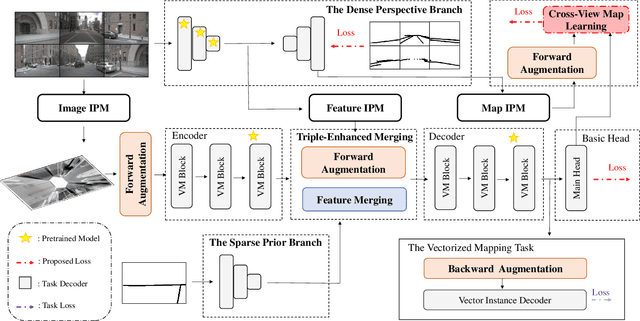
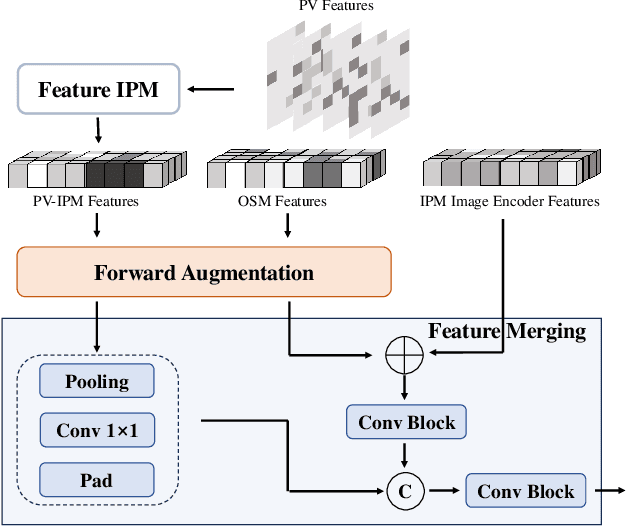
Online High-Definition (HD) maps have emerged as the preferred option for autonomous driving, overshadowing the counterpart offline HD maps due to flexible update capability and lower maintenance costs. However, contemporary online HD map models embed parameters of visual sensors into training, resulting in a significant decrease in generalization performance when applied to visual sensors with different parameters. Inspired by the inherent potential of Inverse Perspective Mapping (IPM), where camera parameters are decoupled from the training process, we have designed a universal map generation framework, GenMapping. The framework is established with a triadic synergy architecture, including principal and dual auxiliary branches. When faced with a coarse road image with local distortion translated via IPM, the principal branch learns robust global features under the state space models. The two auxiliary branches are a dense perspective branch and a sparse prior branch. The former exploits the correlation information between static and moving objects, whereas the latter introduces the prior knowledge of OpenStreetMap (OSM). The triple-enhanced merging module is crafted to synergistically integrate the unique spatial features from all three branches. To further improve generalization capabilities, a Cross-View Map Learning (CVML) scheme is leveraged to realize joint learning within the common space. Additionally, a Bidirectional Data Augmentation (BiDA) module is introduced to mitigate reliance on datasets concurrently. A thorough array of experimental results shows that the proposed model surpasses current state-of-the-art methods in both semantic mapping and vectorized mapping, while also maintaining a rapid inference speed. The source code will be publicly available at https://github.com/lynn-yu/GenMapping.
Deep Adaptive Interest Network: Personalized Recommendation with Context-Aware Learning
Sep 04, 2024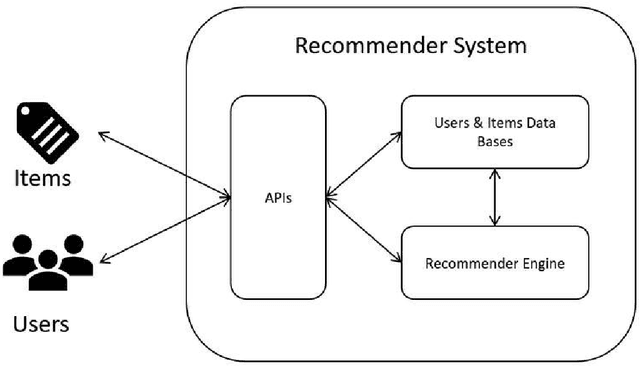
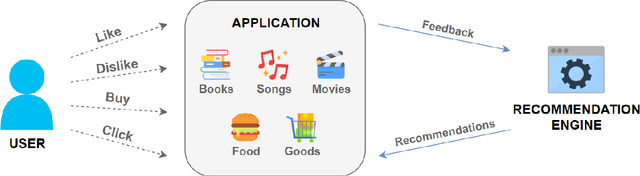
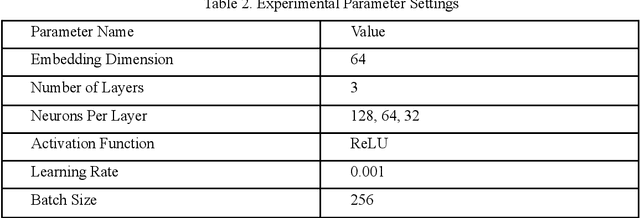
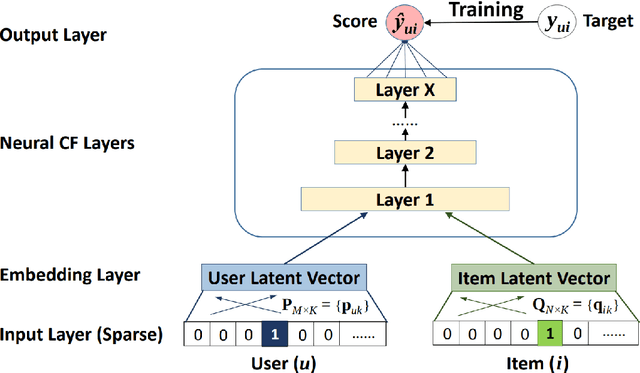
In personalized recommendation systems, accurately capturing users' evolving interests and combining them with contextual information is a critical research area. This paper proposes a novel model called the Deep Adaptive Interest Network (DAIN), which dynamically models users' interests while incorporating context-aware learning mechanisms to achieve precise and adaptive personalized recommendations. DAIN leverages deep learning techniques to build an adaptive interest network structure that can capture users' interest changes in real-time while further optimizing recommendation results by integrating contextual information. Experiments conducted on several public datasets demonstrate that DAIN excels in both recommendation performance and computational efficiency. This research not only provides a new solution for personalized recommendation systems but also offers fresh insights into the application of context-aware learning in recommendation systems.
DTCLMapper: Dual Temporal Consistent Learning for Vectorized HD Map Construction
May 09, 2024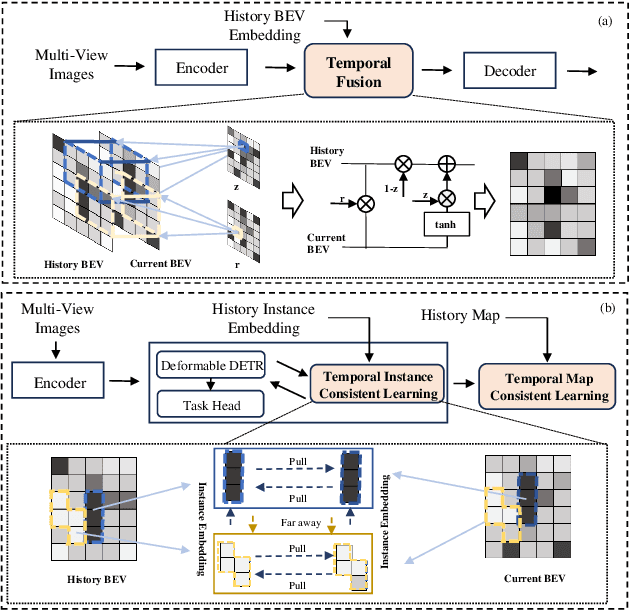
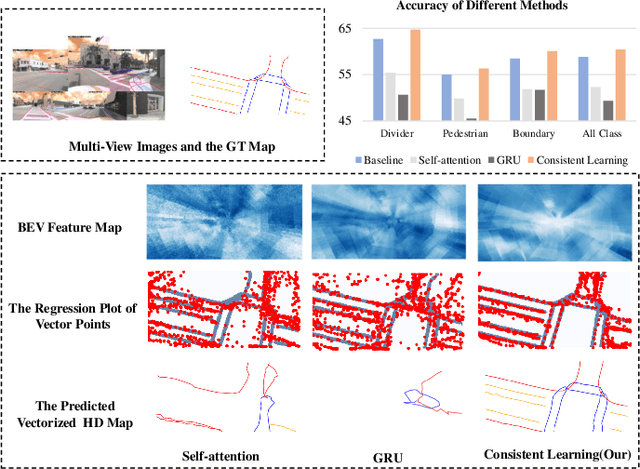
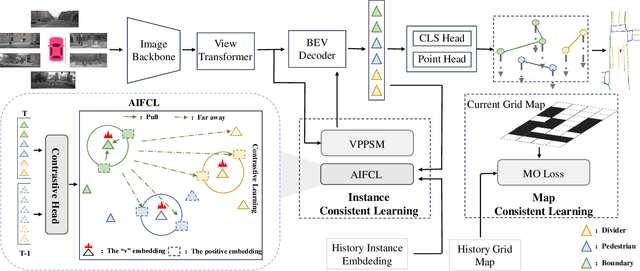
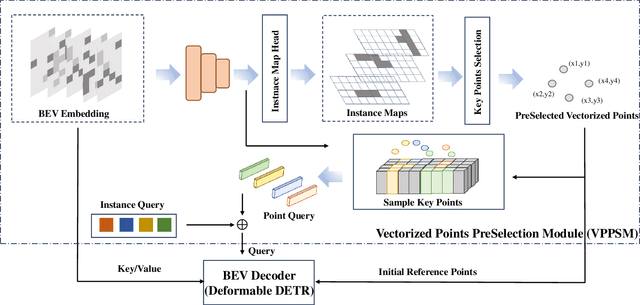
Temporal information plays a pivotal role in Bird's-Eye-View (BEV) driving scene understanding, which can alleviate the visual information sparsity. However, the indiscriminate temporal fusion method will cause the barrier of feature redundancy when constructing vectorized High-Definition (HD) maps. In this paper, we revisit the temporal fusion of vectorized HD maps, focusing on temporal instance consistency and temporal map consistency learning. To improve the representation of instances in single-frame maps, we introduce a novel method, DTCLMapper. This approach uses a dual-stream temporal consistency learning module that combines instance embedding with geometry maps. In the instance embedding component, our approach integrates temporal Instance Consistency Learning (ICL), ensuring consistency from vector points and instance features aggregated from points. A vectorized points pre-selection module is employed to enhance the regression efficiency of vector points from each instance. Then aggregated instance features obtained from the vectorized points preselection module are grounded in contrastive learning to realize temporal consistency, where positive and negative samples are selected based on position and semantic information. The geometry mapping component introduces Map Consistency Learning (MCL) designed with self-supervised learning. The MCL enhances the generalization capability of our consistent learning approach by concentrating on the global location and distribution constraints of the instances. Extensive experiments on well-recognized benchmarks indicate that the proposed DTCLMapper achieves state-of-the-art performance in vectorized mapping tasks, reaching 61.9% and 65.1% mAP scores on the nuScenes and Argoverse datasets, respectively. The source code will be made publicly available at https://github.com/lynn-yu/DTCLMapper.
CFMW: Cross-modality Fusion Mamba for Multispectral Object Detection under Adverse Weather Conditions
Apr 25, 2024



Cross-modality images that integrate visible-infrared spectra cues can provide richer complementary information for object detection. Despite this, existing visible-infrared object detection methods severely degrade in severe weather conditions. This failure stems from the pronounced sensitivity of visible images to environmental perturbations, such as rain, haze, and snow, which frequently cause false negatives and false positives in detection. To address this issue, we introduce a novel and challenging task, termed visible-infrared object detection under adverse weather conditions. To foster this task, we have constructed a new Severe Weather Visible-Infrared Dataset (SWVID) with diverse severe weather scenes. Furthermore, we introduce the Cross-modality Fusion Mamba with Weather-removal (CFMW) to augment detection accuracy in adverse weather conditions. Thanks to the proposed Weather Removal Diffusion Model (WRDM) and Cross-modality Fusion Mamba (CFM) modules, CFMW is able to mine more essential information of pedestrian features in cross-modality fusion, thus could transfer to other rarer scenarios with high efficiency and has adequate availability on those platforms with low computing power. To the best of our knowledge, this is the first study that targeted improvement and integrated both Diffusion and Mamba modules in cross-modality object detection, successfully expanding the practical application of this type of model with its higher accuracy and more advanced architecture. Extensive experiments on both well-recognized and self-created datasets conclusively demonstrate that our CFMW achieves state-of-the-art detection performance, surpassing existing benchmarks. The dataset and source code will be made publicly available at https://github.com/lhy-zjut/CFMW.