 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDTCLMapper: Dual Temporal Consistent Learning for Vectorized HD Map Construction
Paper and Code
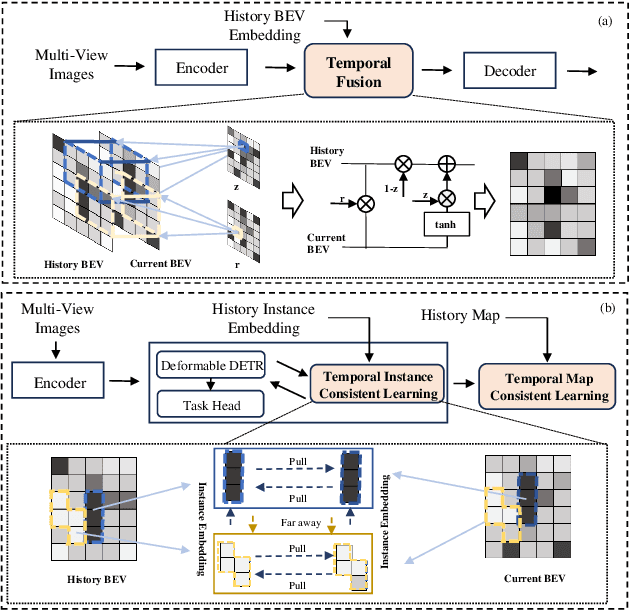
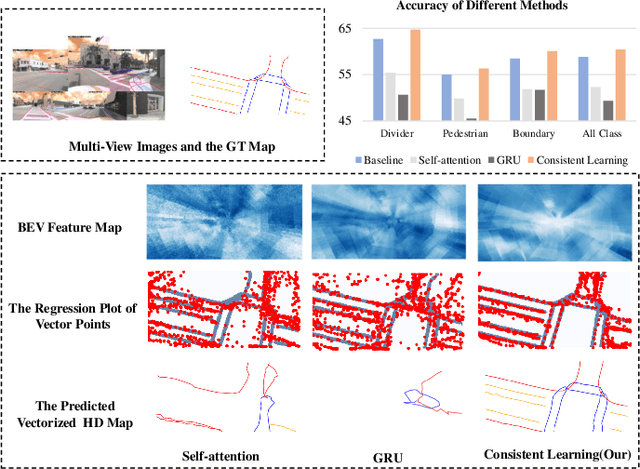
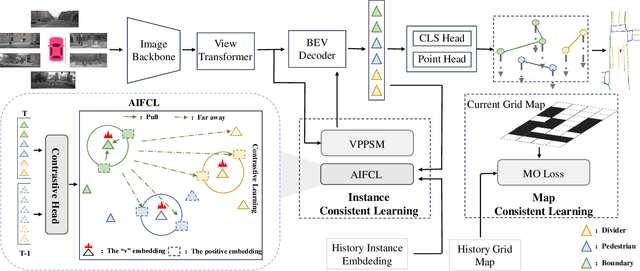
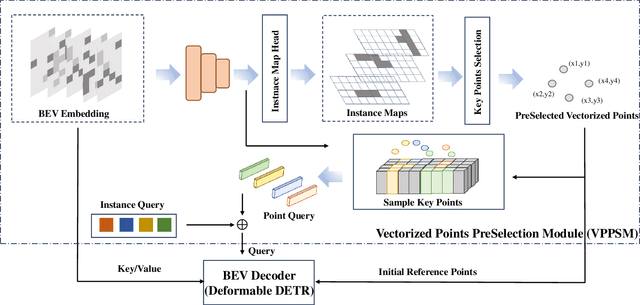
Temporal information plays a pivotal role in Bird's-Eye-View (BEV) driving scene understanding, which can alleviate the visual information sparsity. However, the indiscriminate temporal fusion method will cause the barrier of feature redundancy when constructing vectorized High-Definition (HD) maps. In this paper, we revisit the temporal fusion of vectorized HD maps, focusing on temporal instance consistency and temporal map consistency learning. To improve the representation of instances in single-frame maps, we introduce a novel method, DTCLMapper. This approach uses a dual-stream temporal consistency learning module that combines instance embedding with geometry maps. In the instance embedding component, our approach integrates temporal Instance Consistency Learning (ICL), ensuring consistency from vector points and instance features aggregated from points. A vectorized points pre-selection module is employed to enhance the regression efficiency of vector points from each instance. Then aggregated instance features obtained from the vectorized points preselection module are grounded in contrastive learning to realize temporal consistency, where positive and negative samples are selected based on position and semantic information. The geometry mapping component introduces Map Consistency Learning (MCL) designed with self-supervised learning. The MCL enhances the generalization capability of our consistent learning approach by concentrating on the global location and distribution constraints of the instances. Extensive experiments on well-recognized benchmarks indicate that the proposed DTCLMapper achieves state-of-the-art performance in vectorized mapping tasks, reaching 61.9% and 65.1% mAP scores on the nuScenes and Argoverse datasets, respectively. The source code will be made publicly available at https://github.com/lynn-yu/DTCLMapper.