 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Confidence Reranker: A Training-Free Approach for Enhancing Retrieval-Augmented Generation Systems
Feb 14, 2026Large language models (LLMs) have revolutionized natural language processing, yet hallucinations in knowledge-intensive tasks remain a critical challenge. Retrieval-augmented generation (RAG) addresses this by integrating external knowledge, but its efficacy depends on accurate document retrieval and ranking. Although existing rerankers demonstrate effectiveness, they frequently necessitate specialized training, impose substantial computational expenses, and fail to fully exploit the semantic capabilities of LLMs, particularly their inherent confidence signals. We propose the LLM-Confidence Reranker (LCR), a training-free, plug-and-play algorithm that enhances reranking in RAG systems by leveraging black-box LLM confidence derived from Maximum Semantic Cluster Proportion (MSCP). LCR employs a two-stage process: confidence assessment via multinomial sampling and clustering, followed by binning and multi-level sorting based on query and document confidence thresholds. This approach prioritizes relevant documents while preserving original rankings for high-confidence queries, ensuring robustness. Evaluated on BEIR and TREC benchmarks with BM25 and Contriever retrievers, LCR--using only 7--9B-parameter pre-trained LLMs--consistently improves NDCG@5 by up to 20.6% across pre-trained LLM and fine-tuned Transformer rerankers, without degradation. Ablation studies validate the hypothesis that LLM confidence positively correlates with document relevance, elucidating LCR's mechanism. LCR offers computational efficiency, parallelism for scalability, and broad compatibility, mitigating hallucinations in applications like medical diagnosis.
* Published by ESWA
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
OT Score: An OT based Confidence Score for Unsupervised Domain Adaptation
May 16, 2025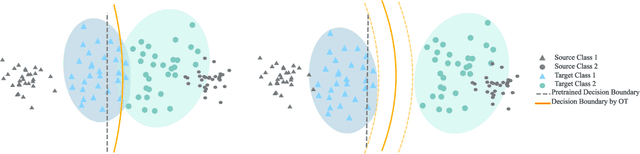
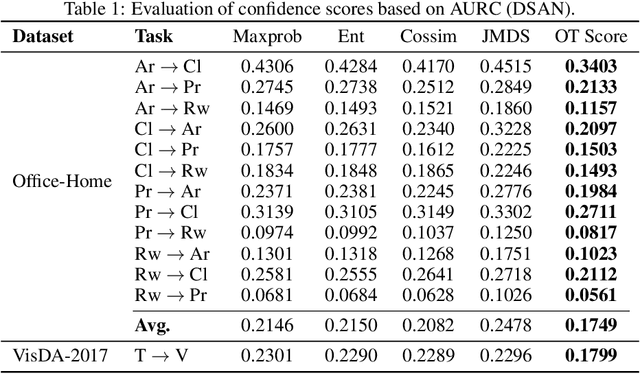
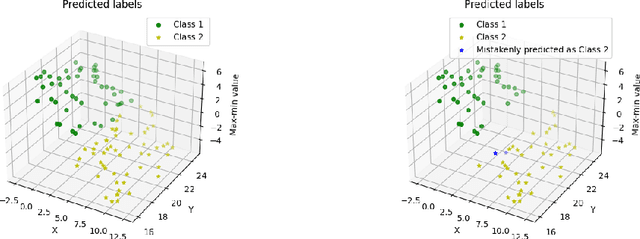
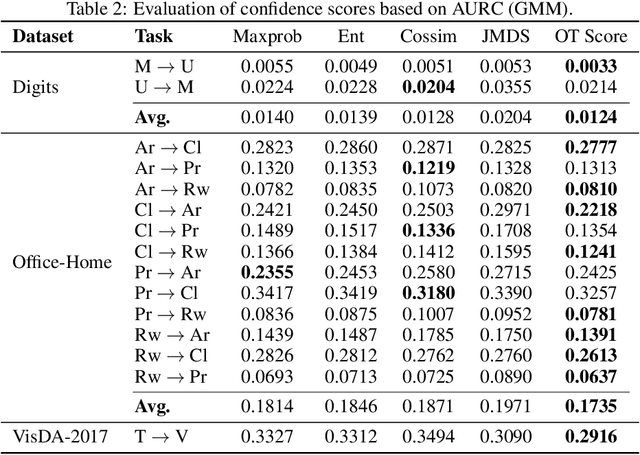
We address the computational and theoretical limitations of existing distributional alignment methods for unsupervised domain adaptation (UDA), particularly regarding the estimation of classification performance and confidence without target labels. Current theoretical frameworks for these methods often yield computationally intractable quantities and fail to adequately reflect the properties of the alignment algorithms employed. To overcome these challenges, we introduce the Optimal Transport (OT) score, a confidence metric derived from a novel theoretical analysis that exploits the flexibility of decision boundaries induced by Semi-Discrete Optimal Transport alignment. The proposed OT score is intuitively interpretable, theoretically rigorous, and computationally efficient. It provides principled uncertainty estimates for any given set of target pseudo-labels without requiring model retraining, and can flexibly adapt to varying degrees of available source information. Experimental results on standard UDA benchmarks demonstrate that classification accuracy consistently improves by identifying and removing low-confidence predictions, and that OT score significantly outperforms existing confidence metrics across diverse adaptation scenarios.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Generating Seamless Virtual Immunohistochemical Whole Slide Images with Content and Color Consistency
Oct 01, 2024



Immunohistochemical (IHC) stains play a vital role in a pathologist's analysis of medical images, providing crucial diagnostic information for various diseases. Virtual staining from hematoxylin and eosin (H&E)-stained whole slide images (WSIs) allows the automatic production of other useful IHC stains without the expensive physical staining process. However, current virtual WSI generation methods based on tile-wise processing often suffer from inconsistencies in content, texture, and color at tile boundaries. These inconsistencies lead to artifacts that compromise image quality and potentially hinder accurate clinical assessment and diagnoses. To address this limitation, we propose a novel consistent WSI synthesis network, CC-WSI-Net, that extends GAN models to produce seamless synthetic whole slide images. Our CC-WSI-Net integrates a content- and color-consistency supervisor, ensuring consistency across tiles and facilitating the generation of seamless synthetic WSIs while ensuring Sox10 immunohistochemistry accuracy in melanocyte detection. We validate our method through extensive image-quality analyses, objective detection assessments, and a subjective survey with pathologists. By generating high-quality synthetic WSIs, our method opens doors for advanced virtual staining techniques with broader applications in research and clinical care.
Machine Learning-Based Research on the Adaptability of Adolescents to Online Education
Aug 29, 2024

With the rapid advancement of internet technology, the adaptability of adolescents to online learning has emerged as a focal point of interest within the educational sphere. However, the academic community's efforts to develop predictive models for adolescent online learning adaptability require further refinement and expansion. Utilizing data from the "Chinese Adolescent Online Education Survey" spanning the years 2014 to 2016, this study implements five machine learning algorithms - logistic regression, K-nearest neighbors, random forest, XGBoost, and CatBoost - to analyze the factors influencing adolescent online learning adaptability and to determine the model best suited for prediction. The research reveals that the duration of courses, the financial status of the family, and age are the primary factors affecting students' adaptability in online learning environments. Additionally, age significantly impacts students' adaptive capacities. Among the predictive models, the random forest, XGBoost, and CatBoost algorithms demonstrate superior forecasting capabilities, with the random forest model being particularly adept at capturing the characteristics of students' adaptability.
Attention Mechanism and Context Modeling System for Text Mining Machine Translation
Aug 08, 2024



This paper advances a novel architectural schema anchored upon the Transformer paradigm and innovatively amalgamates the K-means categorization algorithm to augment the contextual apprehension capabilities of the schema. The transformer model performs well in machine translation tasks due to its parallel computing power and multi-head attention mechanism. However, it may encounter contextual ambiguity or ignore local features when dealing with highly complex language structures. To circumvent this constraint, this exposition incorporates the K-Means algorithm, which is used to stratify the lexis and idioms of the input textual matter, thereby facilitating superior identification and preservation of the local structure and contextual intelligence of the language. The advantage of this combination is that K-Means can automatically discover the topic or concept regions in the text, which may be directly related to translation quality. Consequently, the schema contrived herein enlists K-Means as a preparatory phase antecedent to the Transformer and recalibrates the multi-head attention weights to assist in the discrimination of lexis and idioms bearing analogous semantics or functionalities. This ensures the schema accords heightened regard to the contextual intelligence embodied by these clusters during the training phase, rather than merely focusing on locational intelligence.
Adversarial Purification of Information Masking
Nov 26, 2023



Adversarial attacks meticulously generate minuscule, imperceptible perturbations to images to deceive neural networks. Counteracting these, adversarial purification methods seek to transform adversarial input samples into clean output images to defend against adversarial attacks. Nonetheless, extent generative models fail to effectively eliminate adversarial perturbations, yielding less-than-ideal purification results. We emphasize the potential threat of residual adversarial perturbations to target models, quantitatively establishing a relationship between perturbation scale and attack capability. Notably, the residual perturbations on the purified image primarily stem from the same-position patch and similar patches of the adversarial sample. We propose a novel adversarial purification approach named Information Mask Purification (IMPure), aims to extensively eliminate adversarial perturbations. To obtain an adversarial sample, we first mask part of the patches information, then reconstruct the patches to resist adversarial perturbations from the patches. We reconstruct all patches in parallel to obtain a cohesive image. Then, in order to protect the purified samples against potential similar regional perturbations, we simulate this risk by randomly mixing the purified samples with the input samples before inputting them into the feature extraction network. Finally, we establish a combined constraint of pixel loss and perceptual loss to augment the model's reconstruction adaptability. Extensive experiments on the ImageNet dataset with three classifier models demonstrate that our approach achieves state-of-the-art results against nine adversarial attack methods. Implementation code and pre-trained weights can be accessed at \textcolor{blue}{https://github.com/NoWindButRain/IMPure}.
Block shuffling learning for Deepfake Detection
Feb 06, 2022



Although the deepfake detection based on convolutional neural network has achieved good results, the detection results show that these detectors show obvious performance degradation when the input images undergo some common transformations (like resizing, blurring), which indicates that the generalization ability of the detector is insufficient. In this paper, we propose a novel block shuffling learning method to solve this problem. Specifically, we divide the images into blocks and then introduce the random shuffling to intra-block and inter-block. Intra-block shuffling increases the robustness of the detector and we also propose an adversarial loss algorithm to overcome the over-fitting problem brought by the noise introduced by shuffling. Moreover, we encourage the detector to focus on finding differences among the local features through inter-block shuffling, and reconstruct the spatial layout of the blocks to model the semantic associations between them. Especially, our method can be easily integrated with various CNN models. Extensive experiments show that our proposed method achieves state-of-the-art performance in forgery face detection, including good generalization ability in the face of common image transformations.