 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking From the Future: Multi-order Iterations Can Enhance Adversarial Attack Transferability
Jul 02, 2024



Various methods try to enhance adversarial transferability by improving the generalization from different perspectives. In this paper, we rethink the optimization process and propose a novel sequence optimization concept, which is named Looking From the Future (LFF). LFF makes use of the original optimization process to refine the very first local optimization choice. Adapting the LFF concept to the adversarial attack task, we further propose an LFF attack as well as an MLFF attack with better generalization ability. Furthermore, guiding with the LFF concept, we propose an $LLF^{\mathcal{N}}$ attack which entends the LFF attack to a multi-order attack, further enhancing the transfer attack ability. All our proposed methods can be directly applied to the iteration-based attack methods. We evaluate our proposed method on the ImageNet1k dataset by applying several SOTA adversarial attack methods under four kinds of tasks. Experimental results show that our proposed method can greatly enhance the attack transferability. Ablation experiments are also applied to verify the effectiveness of each component. The source code will be released after this paper is accepted.
Adversarial Purification of Information Masking
Nov 26, 2023



Adversarial attacks meticulously generate minuscule, imperceptible perturbations to images to deceive neural networks. Counteracting these, adversarial purification methods seek to transform adversarial input samples into clean output images to defend against adversarial attacks. Nonetheless, extent generative models fail to effectively eliminate adversarial perturbations, yielding less-than-ideal purification results. We emphasize the potential threat of residual adversarial perturbations to target models, quantitatively establishing a relationship between perturbation scale and attack capability. Notably, the residual perturbations on the purified image primarily stem from the same-position patch and similar patches of the adversarial sample. We propose a novel adversarial purification approach named Information Mask Purification (IMPure), aims to extensively eliminate adversarial perturbations. To obtain an adversarial sample, we first mask part of the patches information, then reconstruct the patches to resist adversarial perturbations from the patches. We reconstruct all patches in parallel to obtain a cohesive image. Then, in order to protect the purified samples against potential similar regional perturbations, we simulate this risk by randomly mixing the purified samples with the input samples before inputting them into the feature extraction network. Finally, we establish a combined constraint of pixel loss and perceptual loss to augment the model's reconstruction adaptability. Extensive experiments on the ImageNet dataset with three classifier models demonstrate that our approach achieves state-of-the-art results against nine adversarial attack methods. Implementation code and pre-trained weights can be accessed at \textcolor{blue}{https://github.com/NoWindButRain/IMPure}.
Classification of ADHD Patients Using Kernel Hierarchical Extreme Learning Machine
Jun 28, 2022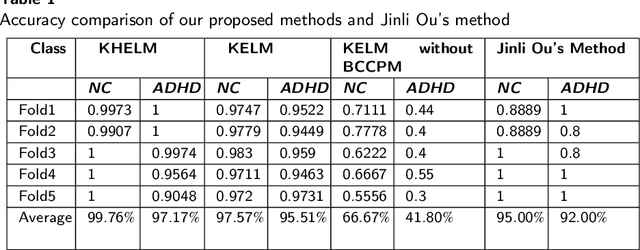


Recently, the application of deep learning models to diagnose neuropsychiatric diseases from brain imaging data has received more and more attention. However, in practice, exploring interactions in brain functional connectivity based on operational magnetic resonance imaging data is critical for studying mental illness. Since Attention-Deficit and Hyperactivity Disorder (ADHD) is a type of chronic disease that is very difficult to diagnose in the early stages, it is necessary to improve the diagnosis accuracy of such illness using machine learning models treating patients before the critical condition. In this study, we utilize the dynamics of brain functional connectivity to model features from medical imaging data, which can extract the differences in brain function interactions between Normal Control (NC) and ADHD. To meet that requirement, we employ the Bayesian connectivity change-point model to detect brain dynamics using the local binary encoding approach and kernel hierarchical extreme learning machine for classifying features. To verify our model, we experimented with it on several real-world children's datasets, and our results achieved superior classification rates compared to the state-of-the-art models.
An Effective Fusion Method to Enhance the Robustness of CNN
May 31, 2022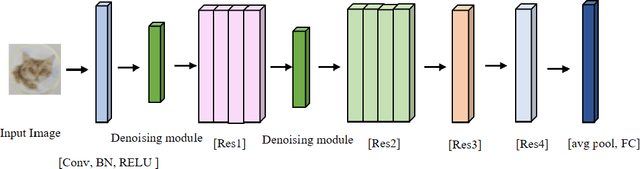
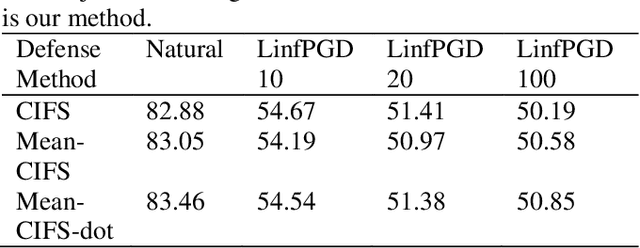
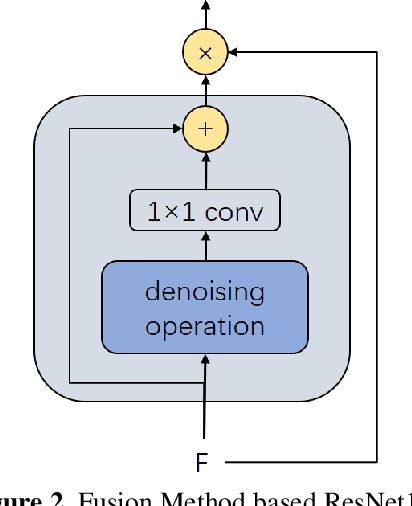
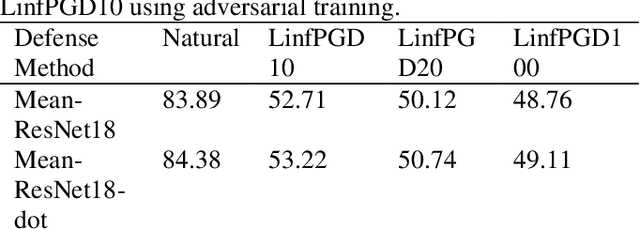
With the development of technology rapidly, applications of convolutional neural networks have improved the convenience of our life. However, in image classification field, it has been found that when some perturbations are added to images, the CNN would misclassify it. Thus various defense methods have been proposed. The previous approach only considered how to incorporate modules in the network to improve robustness, but did not focus on the way the modules were incorporated. In this paper, we design a new fusion method to enhance the robustness of CNN. We use a dot product-based approach to add the denoising module to ResNet18 and the attention mechanism to further improve the robustness of the model. The experimental results on CIFAR10 have shown that our method is effective and better than the state-of-the-art methods under the attack of FGSM and PGD.
Real-centric Consistency Learning for Deepfake Detection
May 15, 2022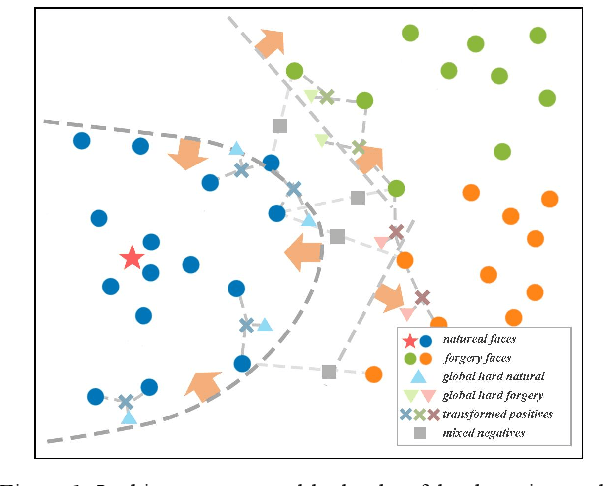
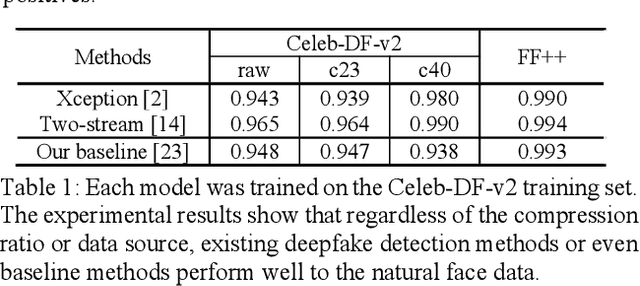


Most of previous deepfake detection researches bent their efforts to describe and discriminate artifacts in human perceptible ways, which leave a bias in the learned networks of ignoring some critical invariance features intra-class and underperforming the robustness of internet interference. Essentially, the target of deepfake detection problem is to represent natural faces and fake faces at the representation space discriminatively, and it reminds us whether we could optimize the feature extraction procedure at the representation space through constraining intra-class consistence and inter-class inconsistence to bring the intra-class representations close and push the inter-class representations apart? Therefore, inspired by contrastive representation learning, we tackle the deepfake detection problem through learning the invariant representations of both classes and propose a novel real-centric consistency learning method. We constraint the representation from both the sample level and the feature level. At the sample level, we take the procedure of deepfake synthesis into consideration and propose a novel forgery semantical-based pairing strategy to mine latent generation-related features. At the feature level, based on the centers of natural faces at the representation space, we design a hard positive mining and synthesizing method to simulate the potential marginal features. Besides, a hard negative fusion method is designed to improve the discrimination of negative marginal features with the help of supervised contrastive margin loss we developed. The effectiveness and robustness of the proposed method has been demonstrated through extensive experiments.
Understanding CNNs from excitations
May 04, 2022
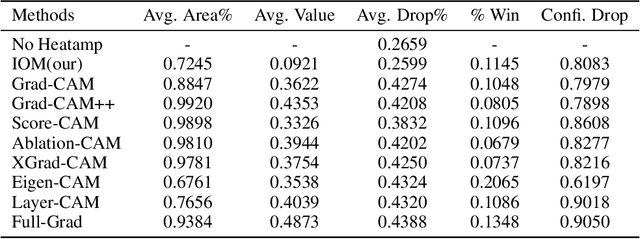
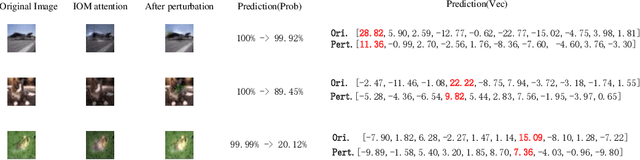
For instance-level explanation, in order to reveal the relations between high-level semantics and detailed spatial information, this paper proposes a novel cognitive approach to neural networks, which named PANE. Under the guidance of PANE, a novel saliency map representation method, named IOM, is proposed for CNN-like models. We make the comparison with eight state-of-the-art saliency map representation methods. The experimental results show that IOM far outperforms baselines. The work of this paper may bring a new perspective to understand deep neural networks.
Functional Connectivity Based Classification of ADHD Using Different Atlases
Mar 01, 2022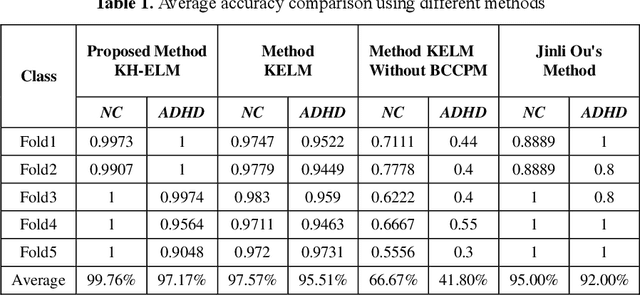

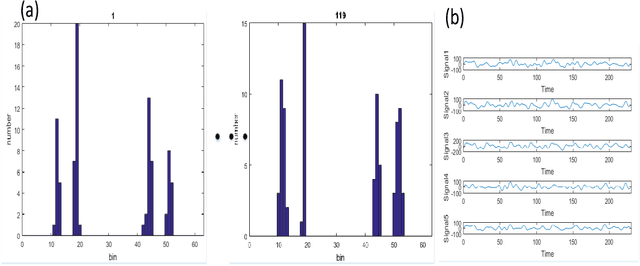
These days, computational diagnosis strategies of neuropsychiatric disorders are gaining attention day by day. It's critical to determine the brain's functional connectivity based on Functional-Magnetic-Resonance-Imaging(fMRI) to diagnose the disorder. It's known as a chronic disease, and millions of children amass the symptoms of this disease, so there is much vacuum for the researcher to formulate a model to improve the accuracy to diagnose ADHD accurately. In this paper, we consider the functional connectivity of a brain extracted using various time templates/Atlases. Local-Binary Encoding-Method (LBEM) algorithm is utilized for feature extraction, while Hierarchical- Extreme-Learning-Machine (HELM) is used to classify the extracted features. To validate our approach, fMRI data of 143 normal and 100 ADHD affected children is used for experimental purpose. Our experimental results are based on comparing various Atlases given as CC400, CC200, and AAL. Our model achieves high performance with CC400 as compared to other Atlases
A Unified Multi-Task Learning Framework of Real-Time Drone Supervision for Crowd Counting
Feb 08, 2022



In this paper, a novel Unified Multi-Task Learning Framework of Real-Time Drone Supervision for Crowd Counting (MFCC) is proposed, which utilizes an image fusion network architecture to fuse images from the visible and thermal infrared image, and a crowd counting network architecture to estimate the density map. The purpose of our framework is to fuse two modalities, including visible and thermal infrared images captured by drones in real-time, that exploit the complementary information to accurately count the dense population and then automatically guide the flight of the drone to supervise the dense crowd. To this end, we propose the unified multi-task learning framework for crowd counting for the first time and re-design the unified training loss functions to align the image fusion network and crowd counting network. We also design the Assisted Learning Module (ALM) to fuse the density map feature to the image fusion encoder process for learning the counting features. To improve the accuracy, we propose the Extensive Context Extraction Module (ECEM) that is based on a dense connection architecture to encode multi-receptive-fields contextual information and apply the Multi-domain Attention Block (MAB) for concerning the head region in the drone view. Finally, we apply the prediction map to automatically guide the drones to supervise the dense crowd. The experimental results on the DroneRGBT dataset show that, compared with the existing methods, ours has comparable results on objective evaluations and an easier training process.
Block shuffling learning for Deepfake Detection
Feb 06, 2022



Although the deepfake detection based on convolutional neural network has achieved good results, the detection results show that these detectors show obvious performance degradation when the input images undergo some common transformations (like resizing, blurring), which indicates that the generalization ability of the detector is insufficient. In this paper, we propose a novel block shuffling learning method to solve this problem. Specifically, we divide the images into blocks and then introduce the random shuffling to intra-block and inter-block. Intra-block shuffling increases the robustness of the detector and we also propose an adversarial loss algorithm to overcome the over-fitting problem brought by the noise introduced by shuffling. Moreover, we encourage the detector to focus on finding differences among the local features through inter-block shuffling, and reconstruct the spatial layout of the blocks to model the semantic associations between them. Especially, our method can be easily integrated with various CNN models. Extensive experiments show that our proposed method achieves state-of-the-art performance in forgery face detection, including good generalization ability in the face of common image transformations.
Sparse Coding Driven Deep Decision Tree Ensembles for Nuclear Segmentation in Digital Pathology Images
Aug 13, 2020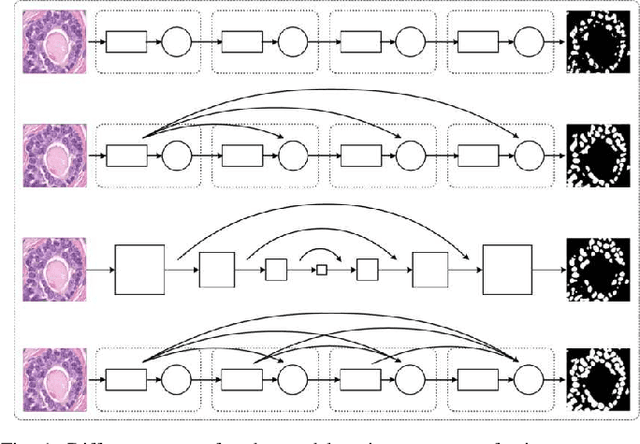
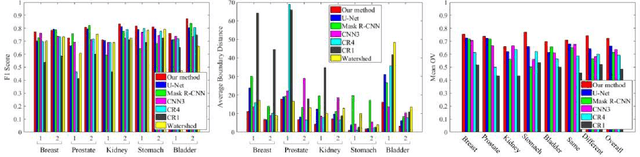

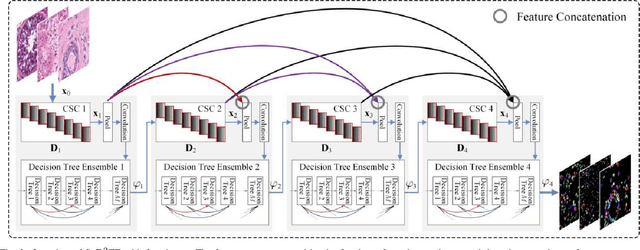
In this paper, we propose an easily trained yet powerful representation learning approach with performance highly competitive to deep neural networks in a digital pathology image segmentation task. The method, called sparse coding driven deep decision tree ensembles that we abbreviate as ScD2TE, provides a new perspective on representation learning. We explore the possibility of stacking several layers based on non-differentiable pairwise modules and generate a densely concatenated architecture holding the characteristics of feature map reuse and end-to-end dense learning. Under this architecture, fast convolutional sparse coding is used to extract multi-level features from the output of each layer. In this way, rich image appearance models together with more contextual information are integrated by learning a series of decision tree ensembles. The appearance and the high-level context features of all the previous layers are seamlessly combined by concatenating them to feed-forward as input, which in turn makes the outputs of subsequent layers more accurate and the whole model efficient to train. Compared with deep neural networks, our proposed ScD2TE does not require back-propagation computation and depends on less hyper-parameters. ScD2TE is able to achieve a fast end-to-end pixel-wise training in a layer-wise manner. We demonstrated the superiority of our segmentation technique by evaluating it on the multi-disease state and multi-organ dataset where consistently higher performances were obtained for comparison against several state-of-the-art deep learning methods such as convolutional neural networks (CNN), fully convolutional networks (FCN), etc.