 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
Mar 17, 2026Distilled autoregressive (AR) video models enable efficient streaming generation but frequently misalign with human visual preferences. Existing reinforcement learning (RL) frameworks are not naturally suited to these architectures, typically requiring either expensive re-distillation or solver-coupled reverse-process optimization that introduces considerable memory and computational overhead. We present Astrolabe, an efficient online RL framework tailored for distilled AR models. To overcome existing bottlenecks, we introduce a forward-process RL formulation based on negative-aware fine-tuning. By contrasting positive and negative samples directly at inference endpoints, this approach establishes an implicit policy improvement direction without requiring reverse-process unrolling. To scale this alignment to long videos, we propose a streaming training scheme that generates sequences progressively via a rolling KV-cache, applying RL updates exclusively to local clip windows while conditioning on prior context to ensure long-range coherence. Finally, to mitigate reward hacking, we integrate a multi-reward objective stabilized by uncertainty-aware selective regularization and dynamic reference updates. Extensive experiments demonstrate that our method consistently enhances generation quality across multiple distilled AR video models, serving as a robust and scalable alignment solution.
OmniForcing: Unleashing Real-time Joint Audio-Visual Generation
Mar 12, 2026Recent joint audio-visual diffusion models achieve remarkable generation quality but suffer from high latency due to their bidirectional attention dependencies, hindering real-time applications. We propose OmniForcing, the first framework to distill an offline, dual-stream bidirectional diffusion model into a high-fidelity streaming autoregressive generator. However, naively applying causal distillation to such dual-stream architectures triggers severe training instability, due to the extreme temporal asymmetry between modalities and the resulting token sparsity. We address the inherent information density gap by introducing an Asymmetric Block-Causal Alignment with a zero-truncation Global Prefix that prevents multi-modal synchronization drift. The gradient explosion caused by extreme audio token sparsity during the causal shift is further resolved through an Audio Sink Token mechanism equipped with an Identity RoPE constraint. Finally, a Joint Self-Forcing Distillation paradigm enables the model to dynamically self-correct cumulative cross-modal errors from exposure bias during long rollouts. Empowered by a modality-independent rolling KV-cache inference scheme, OmniForcing achieves state-of-the-art streaming generation at $\sim$25 FPS on a single GPU, maintaining multi-modal synchronization and visual quality on par with the bidirectional teacher.\textbf{Project Page:} \href{https://omniforcing.com}{https://omniforcing.com}
SetPO: Set-Level Policy Optimization for Diversity-Preserving LLM Reasoning
Feb 01, 2026Reinforcement learning with verifiable rewards has shown notable effectiveness in enhancing large language models (LLMs) reasoning performance, especially in mathematics tasks. However, such improvements often come with reduced outcome diversity, where the model concentrates probability mass on a narrow set of solutions. Motivated by diminishing-returns principles, we introduce a set level diversity objective defined over sampled trajectories using kernelized similarity. Our approach derives a leave-one-out marginal contribution for each sampled trajectory and integrates this objective as a plug-in advantage shaping term for policy optimization. We further investigate the contribution of a single trajectory to language model diversity within a distribution perturbation framework. This analysis theoretically confirms a monotonicity property, proving that rarer trajectories yield consistently higher marginal contributions to the global diversity. Extensive experiments across a range of model scales demonstrate the effectiveness of our proposed algorithm, consistently outperforming strong baselines in both Pass@1 and Pass@K across various benchmarks.
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
Frame-Level Captions for Long Video Generation with Complex Multi Scenes
May 27, 2025Generating long videos that can show complex stories, like movie scenes from scripts, has great promise and offers much more than short clips. However, current methods that use autoregression with diffusion models often struggle because their step-by-step process naturally leads to a serious error accumulation (drift). Also, many existing ways to make long videos focus on single, continuous scenes, making them less useful for stories with many events and changes. This paper introduces a new approach to solve these problems. First, we propose a novel way to annotate datasets at the frame-level, providing detailed text guidance needed for making complex, multi-scene long videos. This detailed guidance works with a Frame-Level Attention Mechanism to make sure text and video match precisely. A key feature is that each part (frame) within these windows can be guided by its own distinct text prompt. Our training uses Diffusion Forcing to provide the model with the ability to handle time flexibly. We tested our approach on difficult VBench 2.0 benchmarks ("Complex Plots" and "Complex Landscapes") based on the WanX2.1-T2V-1.3B model. The results show our method is better at following instructions in complex, changing scenes and creates high-quality long videos. We plan to share our dataset annotation methods and trained models with the research community. Project page: https://zgctroy.github.io/frame-level-captions .
Generative Pre-trained Autoregressive Diffusion Transformer
May 15, 2025In this work, we present GPDiT, a Generative Pre-trained Autoregressive Diffusion Transformer that unifies the strengths of diffusion and autoregressive modeling for long-range video synthesis, within a continuous latent space. Instead of predicting discrete tokens, GPDiT autoregressively predicts future latent frames using a diffusion loss, enabling natural modeling of motion dynamics and semantic consistency across frames. This continuous autoregressive framework not only enhances generation quality but also endows the model with representation capabilities. Additionally, we introduce a lightweight causal attention variant and a parameter-free rotation-based time-conditioning mechanism, improving both the training and inference efficiency. Extensive experiments demonstrate that GPDiT achieves strong performance in video generation quality, video representation ability, and few-shot learning tasks, highlighting its potential as an effective framework for video modeling in continuous space.
STORYANCHORS: Generating Consistent Multi-Scene Story Frames for Long-Form Narratives
May 13, 2025This paper introduces StoryAnchors, a unified framework for generating high-quality, multi-scene story frames with strong temporal consistency. The framework employs a bidirectional story generator that integrates both past and future contexts to ensure temporal consistency, character continuity, and smooth scene transitions throughout the narrative. Specific conditions are introduced to distinguish story frame generation from standard video synthesis, facilitating greater scene diversity and enhancing narrative richness. To further improve generation quality, StoryAnchors integrates Multi-Event Story Frame Labeling and Progressive Story Frame Training, enabling the model to capture both overarching narrative flow and event-level dynamics. This approach supports the creation of editable and expandable story frames, allowing for manual modifications and the generation of longer, more complex sequences. Extensive experiments show that StoryAnchors outperforms existing open-source models in key areas such as consistency, narrative coherence, and scene diversity. Its performance in narrative consistency and story richness is also on par with GPT-4o. Ultimately, StoryAnchors pushes the boundaries of story-driven frame generation, offering a scalable, flexible, and highly editable foundation for future research.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
Research and Implementation of Data Enhancement Techniques for Graph Neural Networks
Jun 18, 2024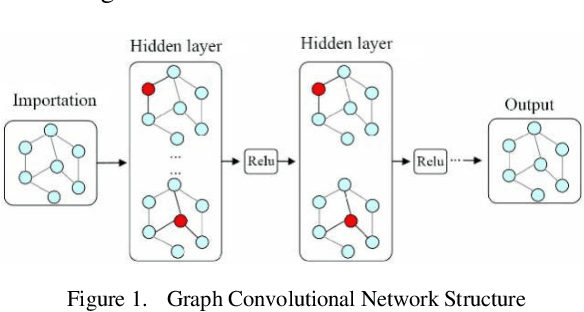
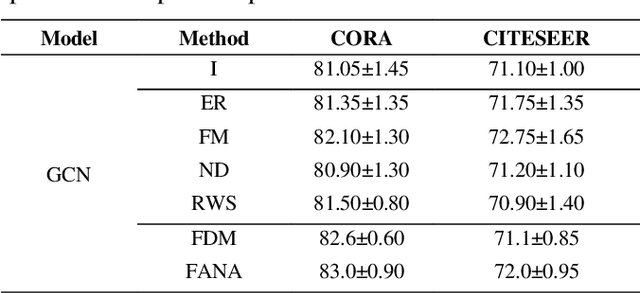
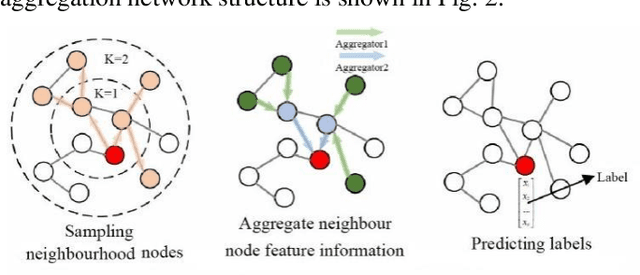
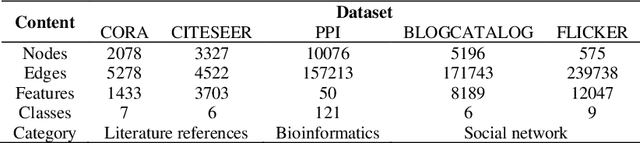
Data, algorithms, and arithmetic power are the three foundational conditions for deep learning to be effective in the application domain. Data is the focus for developing deep learning algorithms. In practical engineering applications, some data are affected by the conditions under which more data cannot be obtained or the cost of obtaining data is too high, resulting in smaller data sets (generally several hundred to several thousand) and data sizes that are far smaller than the size of large data sets (tens of thousands). The above two methods are based on the original dataset to generate, in the case of insufficient data volume of the original data may not reflect all the real environment, such as the real environment of the light, silhouette and other information, if the amount of data is not enough, it is difficult to use a simple transformation or neural network generative model to generate the required data. The research in this paper firstly analyses the key points of the data enhancement technology of graph neural network, and at the same time introduces the composition foundation of graph neural network in depth, on the basis of which the data enhancement technology of graph neural network is optimized and analysed.
Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Feb 26, 2024



Large language models (LLMs) demonstrate remarkable multilingual capabilities without being pre-trained on specially curated multilingual parallel corpora. It remains a challenging problem to explain the underlying mechanisms by which LLMs process multilingual texts. In this paper, we delve into the composition of Transformer architectures in LLMs to pinpoint language-specific regions. Specially, we propose a novel detection method, language activation probability entropy (LAPE), to identify language-specific neurons within LLMs. Based on LAPE, we conduct comprehensive experiments on two representative LLMs, namely LLaMA-2 and BLOOM. Our findings indicate that LLMs' proficiency in processing a particular language is predominantly due to a small subset of neurons, primarily situated in the models' top and bottom layers. Furthermore, we showcase the feasibility to "steer" the output language of LLMs by selectively activating or deactivating language-specific neurons. Our research provides important evidence to the understanding and exploration of the multilingual capabilities of LLMs.