 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Multimodal 3D Brain Tumor Segmentation with Adversarial Training and Conditional Random Field
Nov 21, 2024Accurate brain tumor segmentation remains a challenging task due to structural complexity and great individual differences of gliomas. Leveraging the pre-eminent detail resilience of CRF and spatial feature extraction capacity of V-net, we propose a multimodal 3D Volume Generative Adversarial Network (3D-vGAN) for precise segmentation. The model utilizes Pseudo-3D for V-net improvement, adds conditional random field after generator and use original image as supplemental guidance. Results, using the BraTS-2018 dataset, show that 3D-vGAN outperforms classical segmentation models, including U-net, Gan, FCN and 3D V-net, reaching specificity over 99.8%.
* 13 pages, 7 figures, Annual Conference on Medical Image Understanding and Analysis (MIUA) 2024
One-stop Training of Multiple Capacity Models
May 24, 2023



Training models with varying capacities can be advantageous for deploying them in different scenarios. While high-capacity models offer better performance, low-capacity models require fewer computing resources for training and inference. In this work, we propose a novel one-stop training framework to jointly train high-capacity and low-capactiy models. This framework consists of two composite model architectures and a joint training algorithm called Two-Stage Joint-Training (TSJT). Unlike knowledge distillation, where multiple capacity models are trained from scratch separately, our approach integrates supervisions from different capacity models simultaneously, leading to faster and more efficient convergence. Extensive experiments on the multilingual machine translation benchmark WMT10 show that our method outperforms low-capacity baseline models and achieves comparable or better performance on high-capacity models. Notably, the analysis demonstrates that our method significantly influences the initial training process, leading to more efficient convergence and superior solutions.
CoLa-Diff: Conditional Latent Diffusion Model for Multi-Modal MRI Synthesis
Mar 24, 2023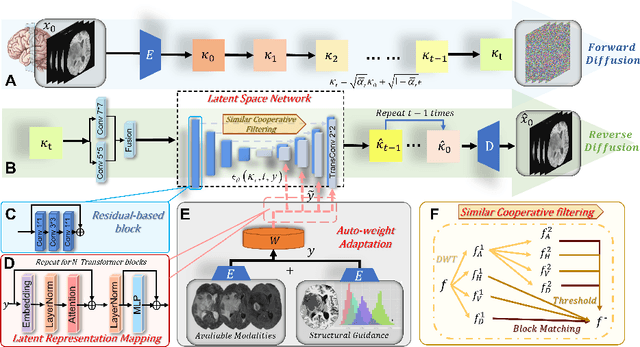
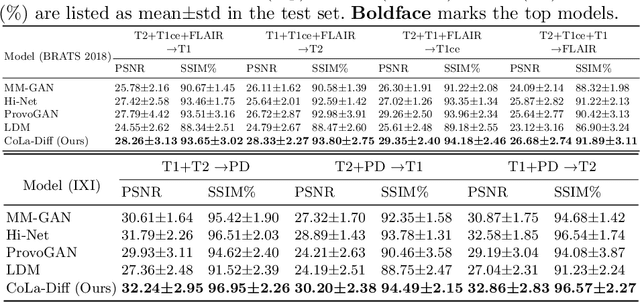
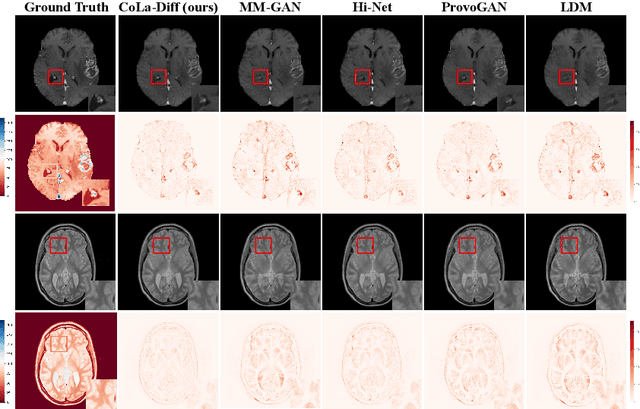
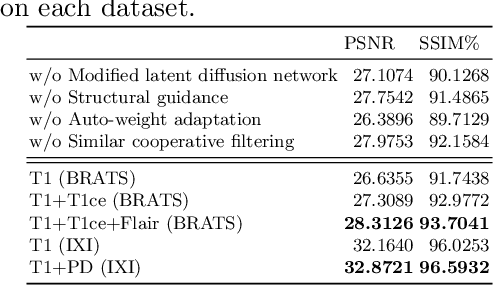
MRI synthesis promises to mitigate the challenge of missing MRI modality in clinical practice. Diffusion model has emerged as an effective technique for image synthesis by modelling complex and variable data distributions. However, most diffusion-based MRI synthesis models are using a single modality. As they operate in the original image domain, they are memory-intensive and less feasible for multi-modal synthesis. Moreover, they often fail to preserve the anatomical structure in MRI. Further, balancing the multiple conditions from multi-modal MRI inputs is crucial for multi-modal synthesis. Here, we propose the first diffusion-based multi-modality MRI synthesis model, namely Conditioned Latent Diffusion Model (CoLa-Diff). To reduce memory consumption, we design CoLa-Diff to operate in the latent space. We propose a novel network architecture, e.g., similar cooperative filtering, to solve the possible compression and noise in latent space. To better maintain the anatomical structure, brain region masks are introduced as the priors of density distributions to guide diffusion process. We further present auto-weight adaptation to employ multi-modal information effectively. Our experiments demonstrate that CoLa-Diff outperforms other state-of-the-art MRI synthesis methods, promising to serve as an effective tool for multi-modal MRI synthesis.
DisC-Diff: Disentangled Conditional Diffusion Model for Multi-Contrast MRI Super-Resolution
Mar 24, 2023

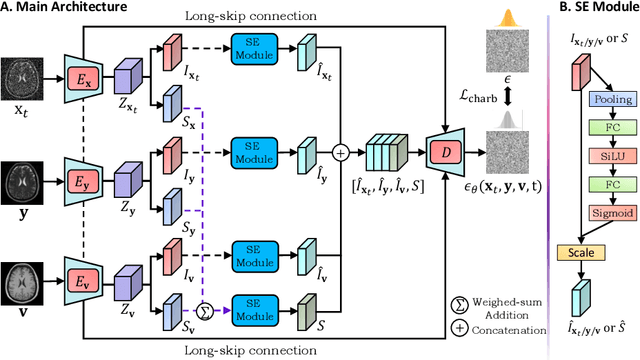

Multi-contrast magnetic resonance imaging (MRI) is the most common management tool used to characterize neurological disorders based on brain tissue contrasts. However, acquiring high-resolution MRI scans is time-consuming and infeasible under specific conditions. Hence, multi-contrast super-resolution methods have been developed to improve the quality of low-resolution contrasts by leveraging complementary information from multi-contrast MRI. Current deep learning-based super-resolution methods have limitations in estimating restoration uncertainty and avoiding mode collapse. Although the diffusion model has emerged as a promising approach for image enhancement, capturing complex interactions between multiple conditions introduced by multi-contrast MRI super-resolution remains a challenge for clinical applications. In this paper, we propose a disentangled conditional diffusion model, DisC-Diff, for multi-contrast brain MRI super-resolution. It utilizes the sampling-based generation and simple objective function of diffusion models to estimate uncertainty in restorations effectively and ensure a stable optimization process. Moreover, DisC-Diff leverages a disentangled multi-stream network to fully exploit complementary information from multi-contrast MRI, improving model interpretation under multiple conditions of multi-contrast inputs. We validated the effectiveness of DisC-Diff on two datasets: the IXI dataset, which contains 578 normal brains, and a clinical dataset with 316 pathological brains. Our experimental results demonstrate that DisC-Diff outperforms other state-of-the-art methods both quantitatively and visually.
ROSE: Robust Selective Fine-tuning for Pre-trained Language Models
Oct 18, 2022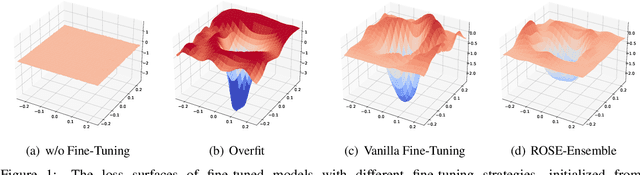
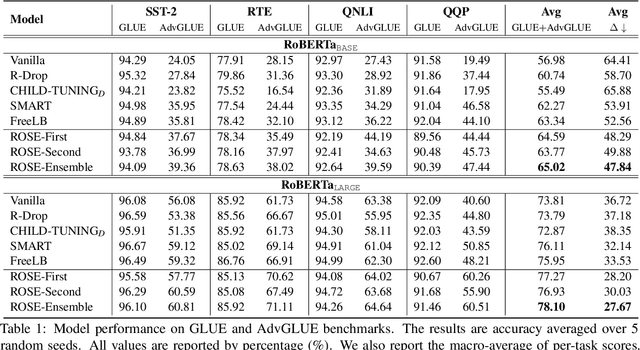
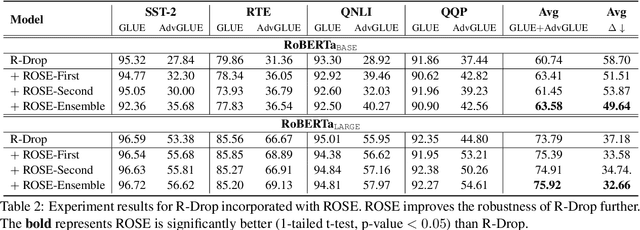
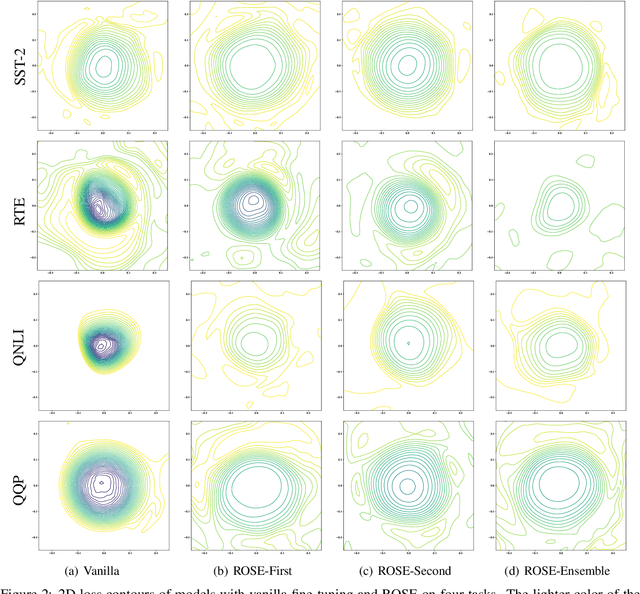
Even though the large-scale language models have achieved excellent performances, they suffer from various adversarial attacks. A large body of defense methods has been proposed. However, they are still limited due to redundant attack search spaces and the inability to defend against various types of attacks. In this work, we present a novel fine-tuning approach called \textbf{RO}bust \textbf{SE}letive fine-tuning (\textbf{ROSE}) to address this issue. ROSE conducts selective updates when adapting pre-trained models to downstream tasks, filtering out invaluable and unrobust updates of parameters. Specifically, we propose two strategies: the first-order and second-order ROSE for selecting target robust parameters. The experimental results show that ROSE achieves significant improvements in adversarial robustness on various downstream NLP tasks, and the ensemble method even surpasses both variants above. Furthermore, ROSE can be easily incorporated into existing fine-tuning methods to improve their adversarial robustness further. The empirical analysis confirms that ROSE eliminates unrobust spurious updates during fine-tuning, leading to solutions corresponding to flatter and wider optima than the conventional method. Code is available at \url{https://github.com/jiangllan/ROSE}.
Detecting Layout Templates in Complex Multiregion Files
Sep 15, 2021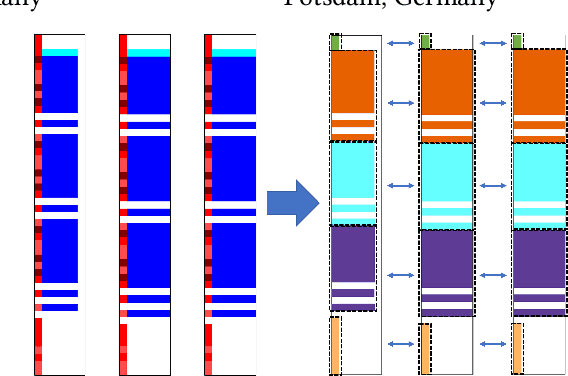
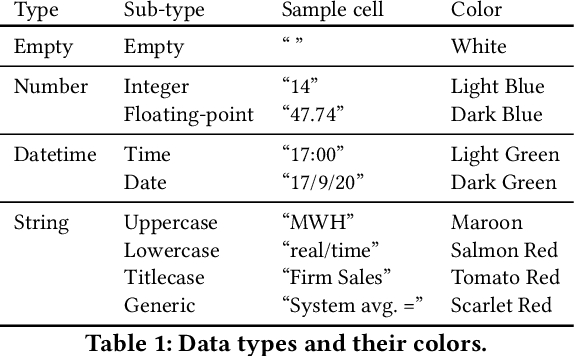

Spreadsheets are among the most commonly used file formats for data management, distribution, and analysis. Their widespread employment makes it easy to gather large collections of data, but their flexible canvas-based structure makes automated analysis difficult without heavy preparation. One of the common problems that practitioners face is the presence of multiple, independent regions in a single spreadsheet, possibly separated by repeated empty cells. We define such files as "multiregion" files. In collections of various spreadsheets, we can observe that some share the same layout. We present the Mondrian approach to automatically identify layout templates across multiple files and systematically extract the corresponding regions. Our approach is composed of three phases: first, each file is rendered as an image and inspected for elements that could form regions; then, using a clustering algorithm, the identified elements are grouped to form regions; finally, every file layout is represented as a graph and compared with others to find layout templates. We compare our method to state-of-the-art table recognition algorithms on two corpora of real-world enterprise spreadsheets. Our approach shows the best performances in detecting reliable region boundaries within each file and can correctly identify recurring layouts across files.
Exposing Length Divergence Bias of Textual Matching Models
Sep 06, 2021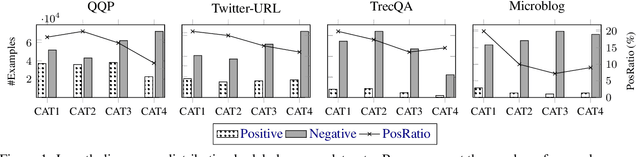

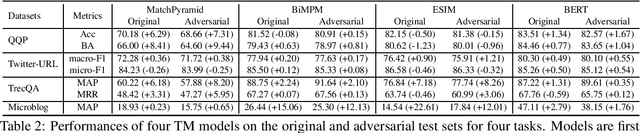
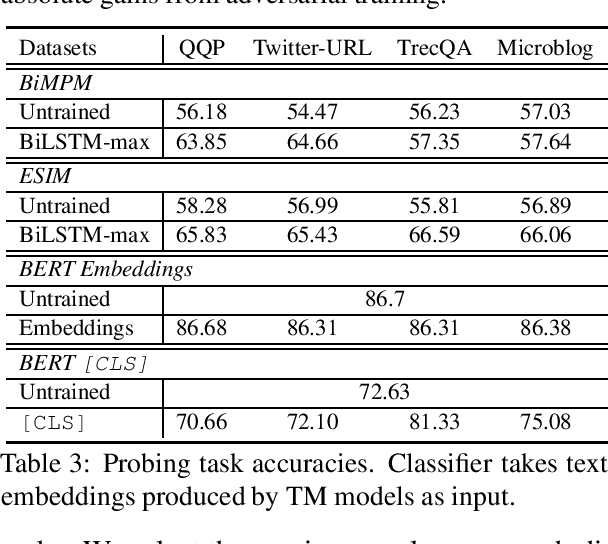
Despite the remarkable success deep models have achieved in Textual Matching (TM), their robustness issue is still a topic of concern. In this work, we propose a new perspective to study this issue -- via the length divergence bias of TM models. We conclude that this bias stems from two parts: the label bias of existing TM datasets and the sensitivity of TM models to superficial information. We critically examine widely used TM datasets, and find that all of them follow specific length divergence distributions by labels, providing direct cues for predictions. As for the TM models, we conduct adversarial evaluation and show that all models' performances drop on the out-of-distribution adversarial test sets we construct, which demonstrates that they are all misled by biased training sets. This is also confirmed by the \textit{SentLen} probing task that all models capture rich length information during training to facilitate their performances. Finally, to alleviate the length divergence bias in TM models, we propose a practical adversarial training method using bias-free training data. Our experiments indicate that we successfully improve the robustness and generalization ability of models at the same time.
Improving Neural Language Models by Segmenting, Attending, and Predicting the Future
Jun 04, 2019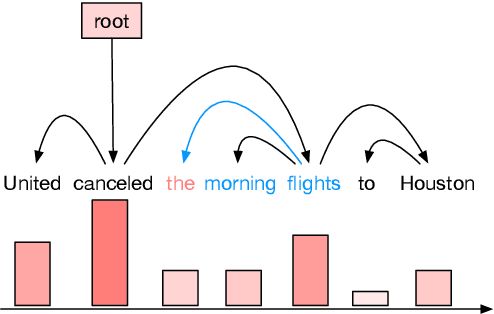
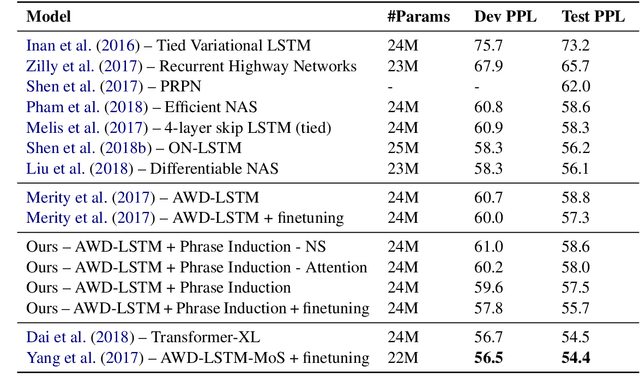
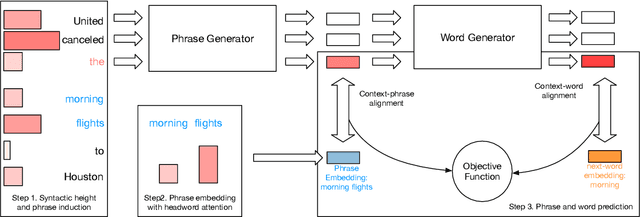
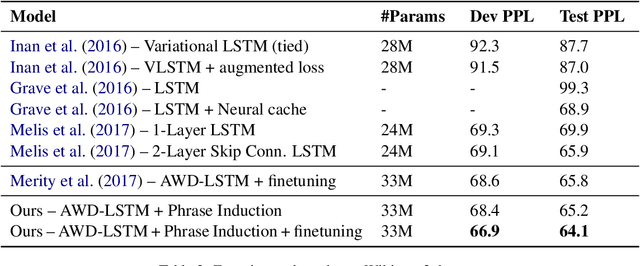
Common language models typically predict the next word given the context. In this work, we propose a method that improves language modeling by learning to align the given context and the following phrase. The model does not require any linguistic annotation of phrase segmentation. Instead, we define syntactic heights and phrase segmentation rules, enabling the model to automatically induce phrases, recognize their task-specific heads, and generate phrase embeddings in an unsupervised learning manner. Our method can easily be applied to language models with different network architectures since an independent module is used for phrase induction and context-phrase alignment, and no change is required in the underlying language modeling network. Experiments have shown that our model outperformed several strong baseline models on different data sets. We achieved a new state-of-the-art performance of 17.4 perplexity on the Wikitext-103 dataset. Additionally, visualizing the outputs of the phrase induction module showed that our model is able to learn approximate phrase-level structural knowledge without any annotation.
Tracking multiple moving objects in images using Markov Chain Monte Carlo
Mar 17, 2016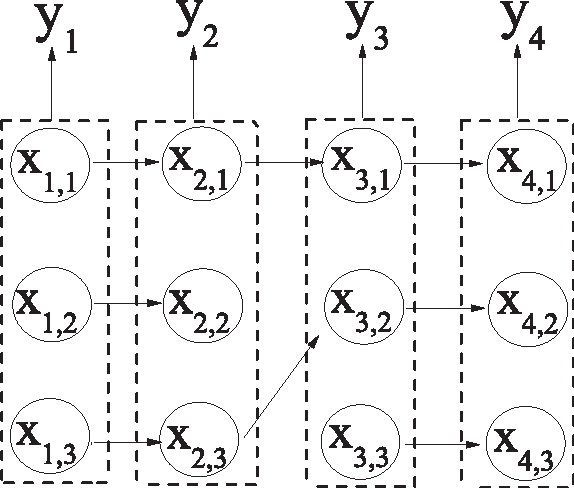
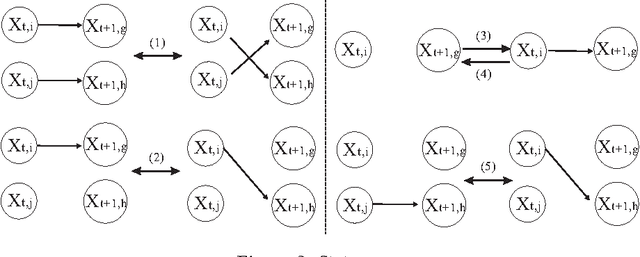
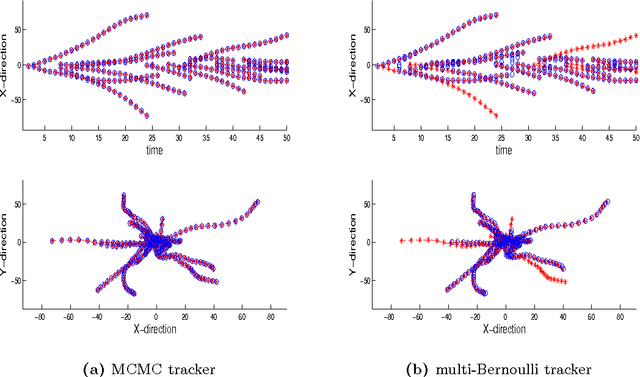
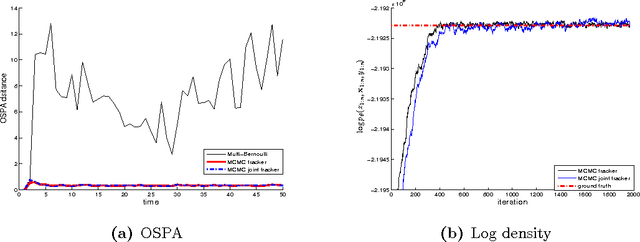
A new Bayesian state and parameter learning algorithm for multiple target tracking (MTT) models with image observations is proposed. Specifically, a Markov chain Monte Carlo algorithm is designed to sample from the posterior distribution of the unknown number of targets, their birth and death times, states and model parameters, which constitutes the complete solution to the tracking problem. The conventional approach is to pre-process the images to extract point observations and then perform tracking. We model the image generation process directly to avoid potential loss of information when extracting point observations. Numerical examples show that our algorithm has improved tracking performance over commonly used techniques, for both synthetic examples and real florescent microscopy data, especially in the case of dim targets with overlapping illuminated regions.