 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Length Divergence Bias of Textual Matching Models
Sep 06, 2021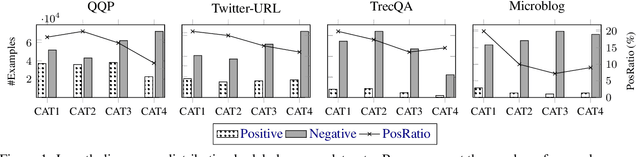

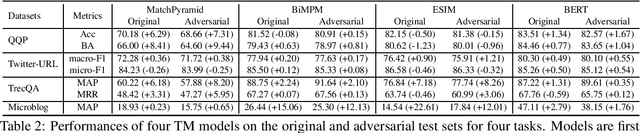
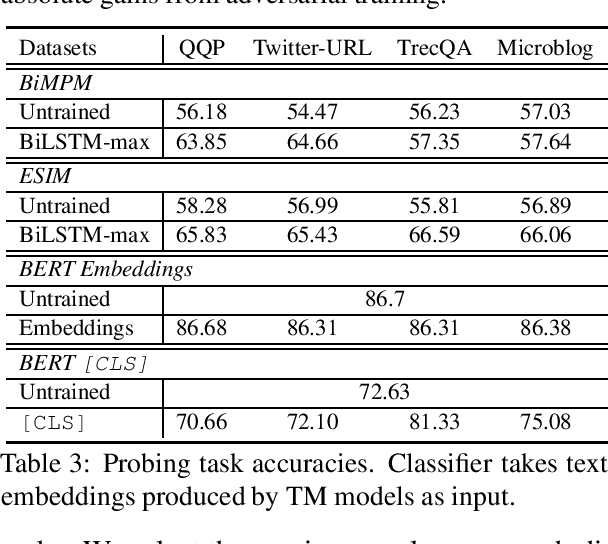
Despite the remarkable success deep models have achieved in Textual Matching (TM), their robustness issue is still a topic of concern. In this work, we propose a new perspective to study this issue -- via the length divergence bias of TM models. We conclude that this bias stems from two parts: the label bias of existing TM datasets and the sensitivity of TM models to superficial information. We critically examine widely used TM datasets, and find that all of them follow specific length divergence distributions by labels, providing direct cues for predictions. As for the TM models, we conduct adversarial evaluation and show that all models' performances drop on the out-of-distribution adversarial test sets we construct, which demonstrates that they are all misled by biased training sets. This is also confirmed by the \textit{SentLen} probing task that all models capture rich length information during training to facilitate their performances. Finally, to alleviate the length divergence bias in TM models, we propose a practical adversarial training method using bias-free training data. Our experiments indicate that we successfully improve the robustness and generalization ability of models at the same time.
Compositional Network Embedding
Apr 18, 2019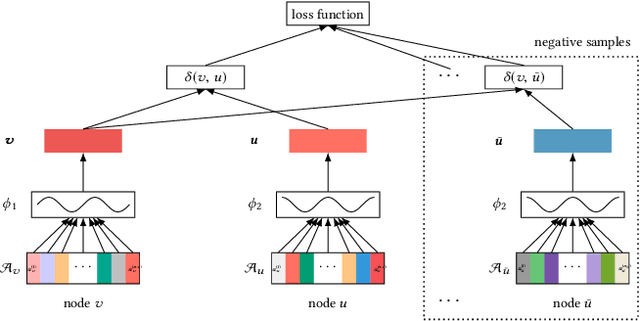
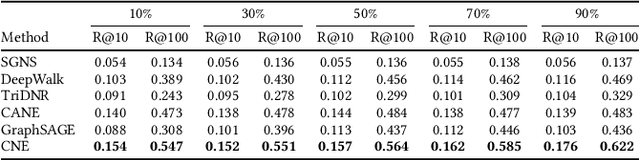
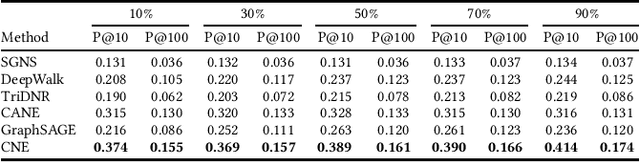
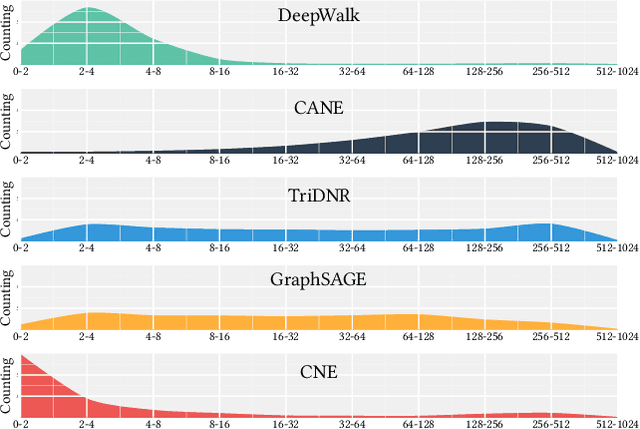
Network embedding has proved extremely useful in a variety of network analysis tasks such as node classification, link prediction, and network visualization. Almost all the existing network embedding methods learn to map the node IDs to their corresponding node embeddings. This design principle, however, hinders the existing methods from being applied in real cases. Node ID is not generalizable and, thus, the existing methods have to pay great effort in cold-start problem. The heterogeneous network usually requires extra work to encode node types, as node type is not able to be identified by node ID. Node ID carries rare information, resulting in the criticism that the existing methods are not robust to noise. To address this issue, we introduce Compositional Network Embedding, a general inductive network representation learning framework that generates node embeddings by combining node features based on the principle of compositionally. Instead of directly optimizing an embedding lookup based on arbitrary node IDs, we learn a composition function that infers node embeddings by combining the corresponding node attribute embeddings through a graph-based loss. For evaluation, we conduct the experiments on link prediction under four different settings. The results verified the effectiveness and generalization ability of compositional network embeddings, especially on unseen nodes.
Incorporating Diversity into Influential Node Mining
Oct 29, 2018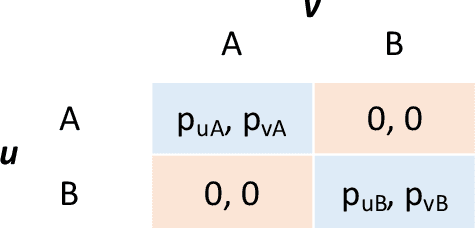
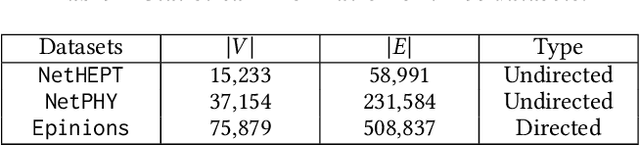
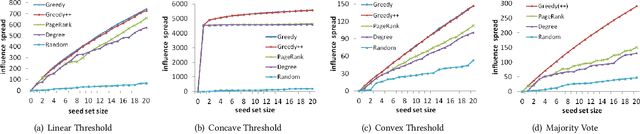
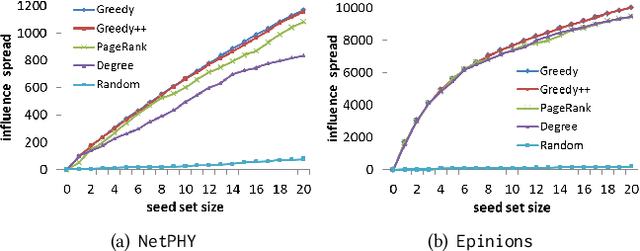
Diversity is a crucial criterion in many ranking and mining tasks. In this paper, we study how to incorporate node diversity into influence maximization (IM). We consider diversity as a reverse measure of the average similarity between selected nodes, which can be specified using node embedding or community detection results. Our goal is to identify a set of nodes which are simultaneously influential and diverse. Three most commonly used utilities in economics (i.e., Perfect Substitutes, Perfect Complements, and Cobb-Douglas) are proposed to jointly model influence spread and diversity as two factors. We formulate diversified IM as an optimization problem of these utilities, for which we present two approximation algorithms based on non-monotonic submodular maximization and traditional IM respectively. Experimental results show that our diversified IM framework outperforms other natural heuristics, such as embedding and diversified ranking, both in utility maximization and result diversification.