 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Length Divergence Bias of Textual Matching Models
Sep 06, 2021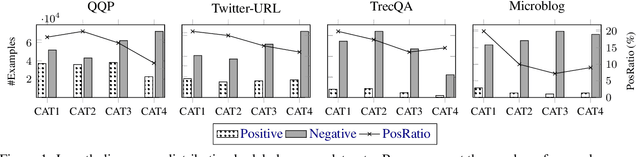

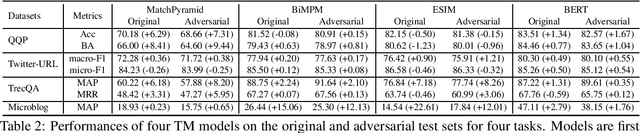
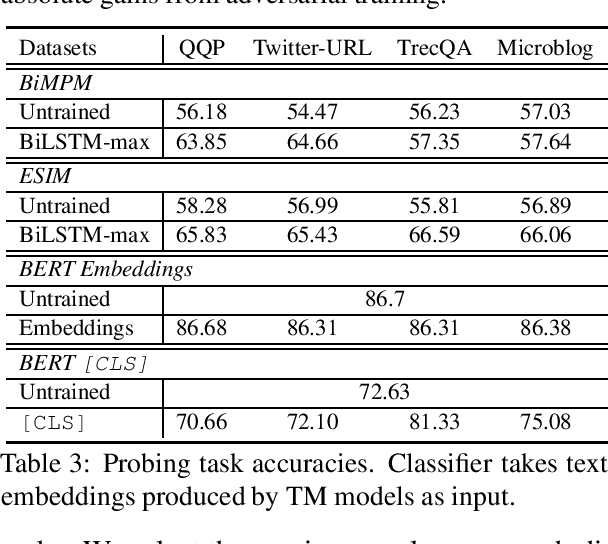
Despite the remarkable success deep models have achieved in Textual Matching (TM), their robustness issue is still a topic of concern. In this work, we propose a new perspective to study this issue -- via the length divergence bias of TM models. We conclude that this bias stems from two parts: the label bias of existing TM datasets and the sensitivity of TM models to superficial information. We critically examine widely used TM datasets, and find that all of them follow specific length divergence distributions by labels, providing direct cues for predictions. As for the TM models, we conduct adversarial evaluation and show that all models' performances drop on the out-of-distribution adversarial test sets we construct, which demonstrates that they are all misled by biased training sets. This is also confirmed by the \textit{SentLen} probing task that all models capture rich length information during training to facilitate their performances. Finally, to alleviate the length divergence bias in TM models, we propose a practical adversarial training method using bias-free training data. Our experiments indicate that we successfully improve the robustness and generalization ability of models at the same time.